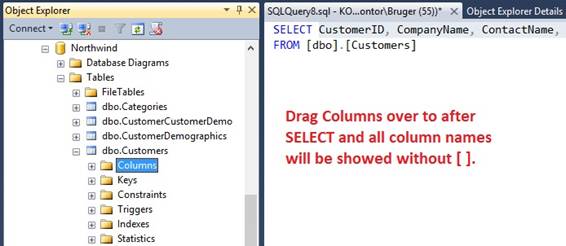
|
SQL Server 2014 -
2025 by Joakim Dalby 1.
Introduction The first version of SQL Server,
known as SQL Server 1.0, was released in 1989 for the OS/2 operating system.
This version was developed in collaboration with Sybase, a software company
that also produced a relational database management system. Microsoft
licensed Sybase's technology and rebranded it as SQL Server. This article is a mix of my
experiences with SQL Server 2014 to SQL Server 2025.
I’m very happy for the developer
edition that can be installed and used on a Windows desktop local computer and
the developer edition include all the enterprise features. It is easy to make
a sql script for deployment at the real windows server where the users have
their databases and data warehouses, SSIS packages, SSRS reports, SSAS OLAP
cubes, SSAS Tabular model cubes and SQL Agent jobs running the ETL process in
the night. SQL Server versions: 2016 2017 2019 2022 2025 What's new in SQL Server 2025 What's new
in SQL Server 2025 in YT video Whats new in Analysis services 2025 Same whats new in Analysis services 2025 Current Service Pack (SP) and
Cumulative Update (CU) to SQL Server
at Microsoft SQL Server Analysis
services Reporting
services. SQL Server Documentation 2022 Pricing Editions and supported
features of SQL Server 2022 Download SQL Server Developer, Management Studio SSMS, Data
Tools SSDT Install sql server integration services in visual studio Additional Tips and Tricks for using SSMS More tips and tricks for SSMS Tutorials for SQL Server
mssqltips tutorials
Quick reference guide Index reorganize / rebuild Deadlock troubleshooting
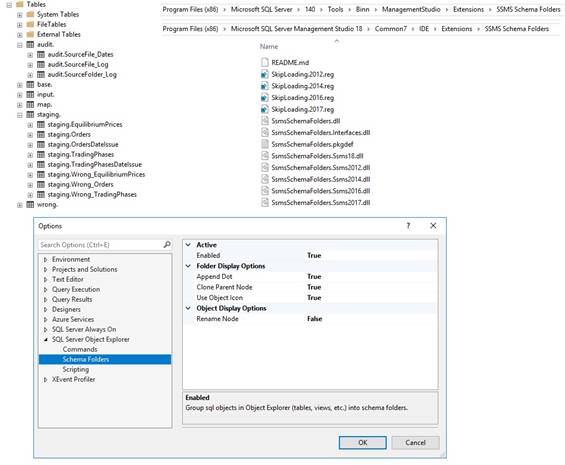
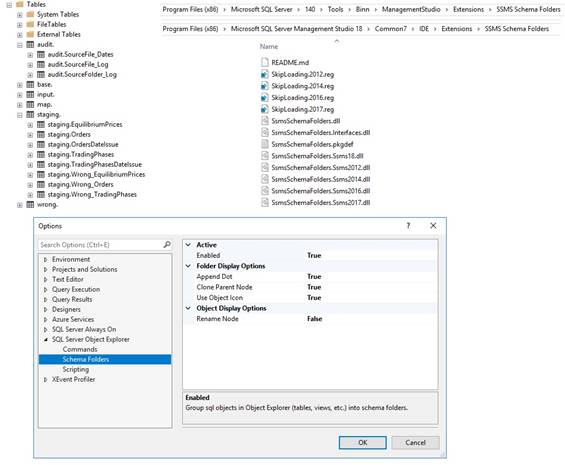
Monitoring blocking Schema folders to divide tables,
views, stored procedures in Object Explorer tree Optimized locking in SQL Server 2025 In case of error message about OLE
DB or ODBC, please update the drives. The SQL Server Native Client (often
abbreviated SNAC) has been removed from SQL Server 2022 (16.x) and SQL Server
Management Studio 19 (SSMS). The SQL Server Native Client (SQLNCLI or
SQLNCLI11) and the legacy Microsoft OLE DB Provider for SQL Server (SQLOLEDB)
are not recommended for new development. Switch to the new Microsoft OLE DB Driver (MSOLEDBSQL) for
SQL Server or the latest Microsoft ODBC Driver for SQL Server going
forward. Download the latest OLE DB driver
MSOLEDBSQL for SQL Server: https://aka.ms/downloadmsoledbsql Download the latest ODBC driver 18
for SQL Server: https://aka.ms/downloadmsodbcsql Read introductory text about: Microsoft OLE DB Driver for SQL Server Clustered A Clustered Index like a Primary Key
is not storing the rows in physical order but in logical order. That why we
can decide to Reorganize or Rebuild the index. Index is useful for SELECT, UPDATE
og DELETE, and can be bad for INSERT, UPDATE and DELETE. In SQL
Server Management Studio New Query some key and mouse tips Refresh IntelliSense in for new
table, column with Ctrl + Shift + R
or in menubar {Edit} {IntelliSense}
{Refresh Local Cache}. Hide Result Pane in bottom of New
Query Ctrl + R. Exceute F5. Ctrl + M turn on query plan and
then F5 to execute to show actual execution plan. Ctrl + L for showing estimated execution
plan before doing the execution. Text selection with Shift +
End/Arrow keys or mouse drag. Text selection from cursor point to
the end Ctrl + Shift + End. All text selection Ctrl + A. Find
text Ctrl + F, Find next F3. Replace text Ctrl + H. Columns or blocks selection with
Shift + Alt + Arrow keys or Alt + mouse drag, like at the right side of
columns in a select statement become highlighted and typein AS and rename
each column, or for fast delete the highlighted text. Uppercase a highlighted text like
select to SELECT with Ctrl + Shift + U.
Download SQL Server Management
Studio (SSMS) through SQL Server 2014 Express link and run SQLManagementStudio_x64_ENU.exe if you don’t
have the DVD. (Read more of latest version and download). When you logon to a SQL Server 2014
with Remote Desktop Connection and it is a Windows Server I recommend to make
icons of the tools at your desktop like for »SQL Server 2014 Management
Studio« and »SQL Server Data Tools for Visual Studio 2013« (the correct name
is »SQL Server Data Tools - Business Intelligence for Visual Studio 2013« or
in short SSDT-BI, read installation later in this article). When you are
handling files, remember to start the tools programs as 'Run as administrator', for example for CLR dll file registration
for an assembly:
In case »run as« has to use
different user account login you can make a ssms.bat file like this: RUNAS /PROFILE /USER:<domain>\<login>
"C:\Program Files (x86)\Microsoft SQL
Server\120\Tools\Binn\ManagementStudio\Ssms.exe" And you will be prompt for a
password. Since Log off is called Sign out and
is close to Shotdown I make a shortcut at my Windows Server desktop with this
command (/l for logoff), icon and text: C:\Windows\System32\logoff.exe or C:\Windows\System32\shutdown.exe
/l
In case you can’t connect to the SQL
Server with TCP/IP please do this check:
2.
SQL Server 2014 installation Always prepare for the architecture of
drives and folders for directories and files used by the SQL Server. In a Windows
server let C drive take care of Windows and install the program at P drive
together with the pagefile and primary filegroup, place database files at D
drive and E drive in multiple files, log files at L drive, tempdb database at
T drive in 8 files and tempdb log at V drive, remember your # local temporary
and ## global temporary tables is stored in tempdb so let the drive be fast
like SSD drive, OLAP cube at O drive or another server, Report services at R
drive, Tabular at U drive or another server. I hope you get my point of using
some drives and folders for the many directories and files and of course best
when some of them are in separate harddrive to gain the a better
performance. TempDB configuration steps to avoid
SQL Server bottlenecks: • Divide the MDF file by the number of
cores. • Separate the file to separate disk
than the Data and Log disks. • Define all of the files are on the
same initial size. • Make sure the TempDB disk is formatted to 64K. • Auto growth should be the same. • Trace Flag 1117 – Grow All Files
in a FileGroup Equally. • Trace Flag 1118 – Full Extents
Only. 2.1.
Installation of SQL Server services and Management Studio From the DVD starts autorun or
setup.exe and the Planning menu has nice links for help
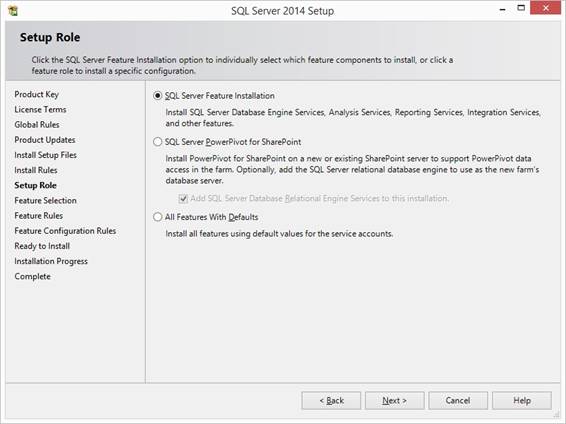
Click the Installation and Option
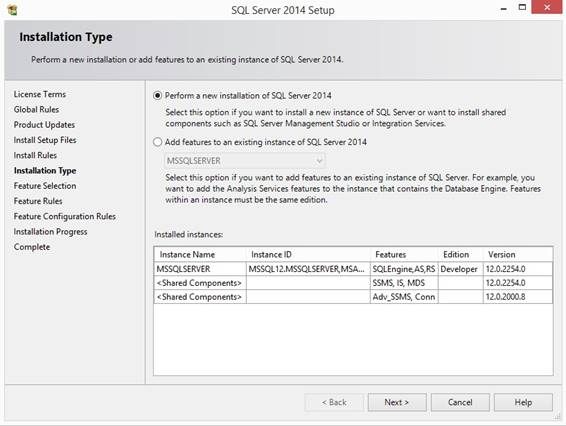
x64 is already selected. Select "New SQL Server
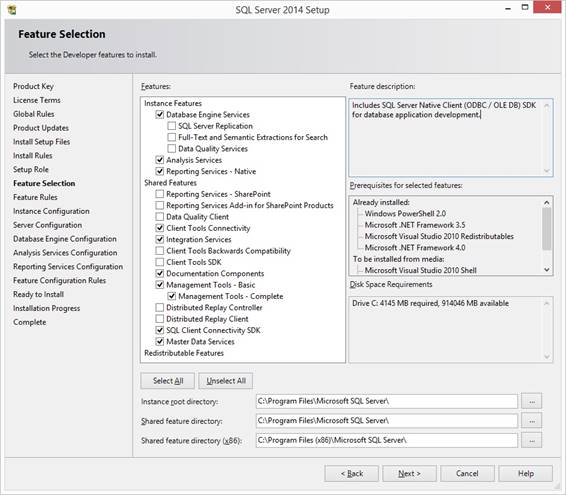
stand-alone installation" and type in the Product key.
Select what you like for the
installation:
SQL Client Connectivity include SQL
Server Native Client 11.0 for ODBC and DSN. Select "Default instance"
and there will be made a SQL Server Instance that has a default name as Instance
Id: MSSQLSERVER in folder: MSSQL12.MSSQLSERVER. Later you can install another
instance of SQL Server software at the same server and name that instance and
connect to it like <servername>\<instancename>. SQL Server is using many running
services at the SQL Server for handling data, jobs, cubes, reports and more
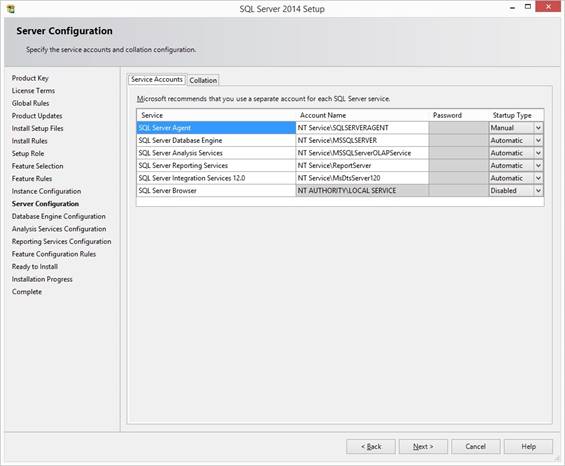
and they are using a default account: · SQL Server (MSSQLSERVER)
Database Engine [run by Windows service account] Provides storage, processing and
controlled access of data and rapid transaction processing. · SQL Server Agent (SQLSERVERAGENT)
[run by a Windows service account] Executes jobs, monitors SQL Server,
fires alerts, and allows automation of some administrative tasks. · SQL Server Analysis
Services (MSSQLServerOLAPService) [by service account] Supplies online analytical
processing (OLAP) and data mining functionality for business intelligence
applications. · SQL Server Integration
Services 12.0 (MsDtsServer120) [by service account] Provides management support for SSIS
package storage and execution. · SQL Server Reporting
Services (ReportServer) [by service account] Manages, executes, renders,
schedules and delivers reports. · SQL Server Browser (SQLBrowser)
[by default account] Provides SQL Server connection
information to client computers. · SQL Server FullText
Search (MSSQLSERVER) [run by default account] Quickly creates full-text indexes on
content and properties of structured and semi-structured data to allow fast
linguistic searches on this data. · SQL Server Active
Directory Helper [run by default account] Enables integration with Active
Directories. · SQL Server VSS Writer (SQLWriter)
[run by default account] Provides the interface to
backup/restore Microsoft SQL server through the Windows VSS infrastructure. Each service is running under a default
account therefore I recommand to make a special Windows AD service account with login name and password, that is
running some of the services and the service account is an administrator of
database, analysis services and report services. For data warehouse servers using
a Windows service account will let the agent job for ETL process use same
account to make data flowing between servers. When a job is going to extract
data from a OLTP database server from a source legacy data system through a
SSIS package or a Linked Servers (Be made using the login's current
security context) the service account can be added to database server with
reading access from the legacy database. Access can also be granted by a sql login
and password (Be made using this security context). The Windows server
account is also used when Analysis Services and Report Services is running at
another servers, and for a presentation server like Targit or Sharepoint server
services is also running under same service account to access a olap cube
data from Analysis Services server or data from a data mart database. You
don’t need to setup the service account in the installation process, you can
do it later in Computer Management at the SQL Server.
The users of the OLAP cubes and
Tabular in Analysis Services through Excel, Targit or other software will be
placed in their own Windows AD group that will be added as role to the cubes.
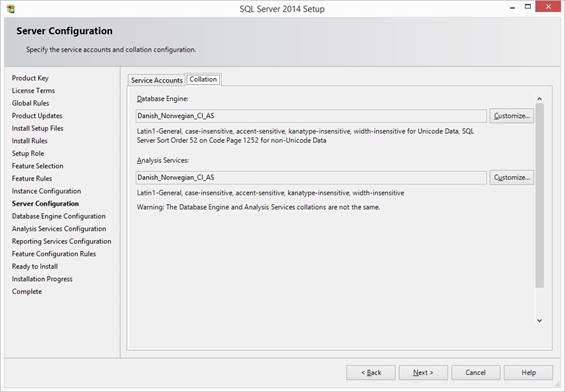
Same for Reporting services or access to a data mart. Collation (language, sortorder)
default is SQL_Latin1_General_CP1_CI_AS. In Denmark we use collation set
under the other tab in above: Danish_Norwegian_CI_AS else we have problems with our extra
letters ÆØÅ as value in text (nvarchar) columns and with sort order like
ORDER BY. I prefer datatype nvarchar for text
/ string, so it can contain chinese like 中文. Since Windows Server operating
system and Windows software programs are using ANSI or codepage 1252 there is
no problem of using danish ÆØÅ or other languages special letters in name
of database and mdf and ldf files, table, column, index, constraint and
default, solution sln file with one or multiple projects dtproj files, SSIS
package dtsx and dtsConfig files, cube, dimension, measure and many more. In
a report I recommand a good test with special letters in your users browser
address line else use english letters for reports in Reporting services
because the browser can have a limit there.
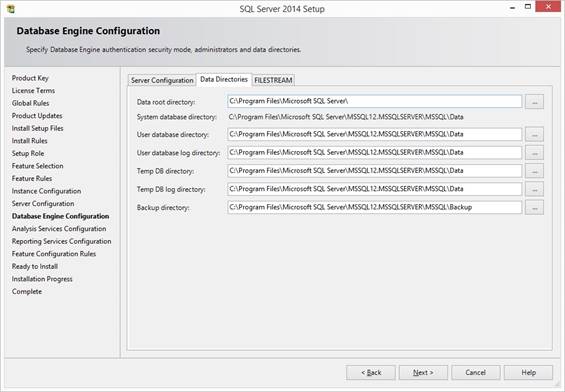
At Database Engine Configuration at
Server Configuration tab I select access mixed mode "SQL Server and
Windows Authentication" so the databases can be accessed by a Windows
user, AD group or by a SQL user and password from an application or an
webservice in DMZ. Give sa account a password, can be used later for Reporting
Services subscription on local PC. Remember to
click "Add Current User" for adding Windows accounts for the people
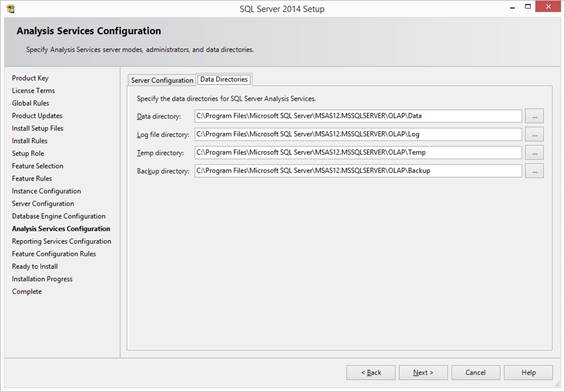
that will be administrators of the SQL Server. At Data Directories tab select the
prepared drives and folders:
In FILESTREAM I don’t enable for
transact-SQL access, later when needed. At Analysis Services Configuration
at Server Configuration tab select between:
I like cube and MDX (Multidimensional
Expressions) and when I want Tabular mode, I will make a new installation and
select it and there will be a new folder (or instance) for that. Then I can
use DAX (Data Analysis Expressions). Click "Add Current User"
for adding the Windows accounts for the people to be administrators of
Analysis Services. At Data Directories tab select the
prepared drives and folders:
Reporting services select between:
Reporting
Services Configuration Options (SSRS) Final click "Install" and
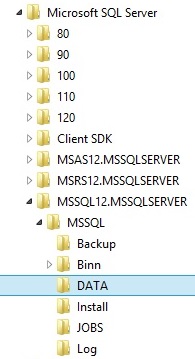
CPU64 is already selected in the messages to come. After installation new folders are
made with the use of the default instance id:
The default instance id is not
needed for the connectionstring from an application to a SQL Server database,
like this: Provider=SQLNCLI11;Server=<name>;Database=Northwind;Trusted_Connection=Yes Provider=SQLNCLI11.1;Data
Source=<server name>;Integrated Security=SSPI; Initial
Catalog=Northwind I got new apps in my Windows 8.1 (or
Windows Server) app list, and 'SQL Server 2014 Managemen NEW' is SQL Server
2014 Management Studio
"C:\Program
Files (x86)\Microsoft SQL
Server\120\Tools\Binn\ManagementStudio\Ssms.exe" and I make it as an icon on my
desktop:
Other
SQL Server programs: SQL
Server 2014 Profiler "C:\Program
Files (x86)\Microsoft SQL Server\120\Tools\Binn\PROFILER.EXE" SQL
Server 2014 Configuration Manager C:\Windows\SysWOW64\mmc.exe
/32 C:\Windows\SysWOW64\SQLServerManager12.msc SQL
Server 2014 Import and Export Data (32-bit) "C:\Program
Files (x86)\Microsoft SQL Server\120\DTS\Binn\DTSWizard.exe" SQL
Server 2014 Import and Export Data (64-bit) "C:\Program
Files\Microsoft SQL Server\120\DTS\Binn\DTSWizard.exe" 2.2.
Windows Update Make a Windows Update to get the
latest service packs and updates from Microsoft. 2.3.
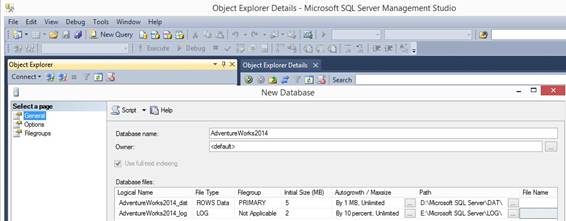
SQL Server 2014 Management Studio Start the SQL Server 2014 Management
Studio, select the server (or local computer) and create a new database with
an owner and Recovery model as Simple and I add a _dat to logical name so I
will get two files in each folder by each path called: AdventureWorks2014_dat.mdf and AdventureWorks2014_log.ldf:
I always use the menu {View} and
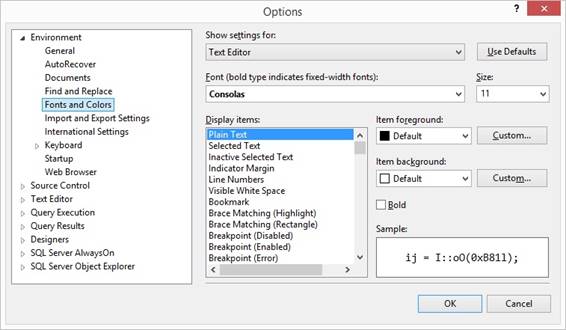
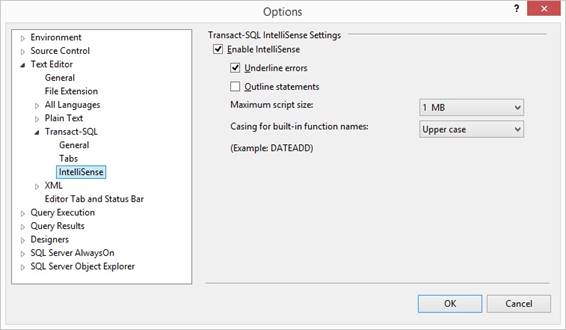
{Object Explorer Details} window. I always set settings in {Tools} and
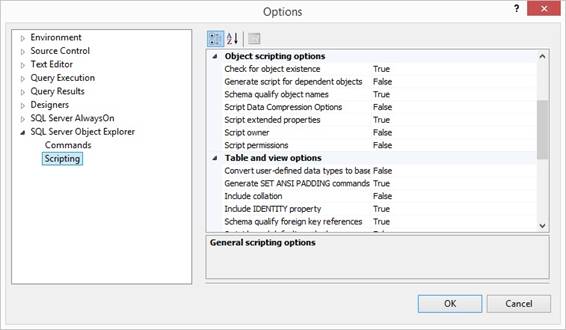
{Options} like this:
I only set 'Check for object
existence' to True before I will do a deployment script using {Drop and
Create to} so the script will have the if-exists part before drop. Else I
have 'Check for object existence' to
False so I can modify a stored procedure in a normal alter procedure way.
2.4.
Connect to Integration Services from Management Studio In previous versions of SQL Server
by default when I installed SQL Server all users in the Users group had access
to the Integration Services service. In SQL Server 2014 users do not have
access to the Integration Services service. The service is secure by default.
To grant access to the Integration Services service do these steps from this
link Grant Permissions to Integration Services Service: 1.
Run
Dcomcnfg.exe to provide a user interface for modifying certain settings in
the registry. 2.
In
the Component Services dialog, expand the Component Services -> Computers -> My Computer ->
DCOM Config node. 3.
Right
click Microsoft SQL Server Integration Services 12.0 and select {Properties}. 4.
On
the Security tab click Edit in the Launch and Activation Permissions area. 5.
Add
users and assign appropriate permissions and then click Ok. 6.
Repeat
steps 4 - 5 for the Access Permissions. 7.
Restart
SQL Server Management Studio. 8.
Restart
the Integration Services Service. After this permission I can from SQL
Server 2014 Management Studio connect to Integration Services. No need for
grant permission for Management Studio to connect to Analysis Server or
Report Server. 2.5.
Installation of SQL Server Data Tools for Business Intelligence SQL Server 2000 had Data
Transformation Services (DTS), SQL Server 2005–2008 R2 had Business Intelligence
Development Studio (BIDS), SQL Server 2012 had SQL Server Data Tools (SSDT)
and SQL Server 2014 has SQL Server Data Tools for Business Intelligence
(SSDT BI) for development of solution and projects of: ·
SQL
Server Analysis Services (SSAS) for cube, dimension and measure. ·
SQL
Server Analysis Services Tabular for in-memory analysis. ·
SQL
Server Integration Services (SSIS) for packages to ETL process. ·
SQL
Server Reporting Services (SSRS) for reports on screen, in paper or file. SSDT-BI is based on Microsoft Visual
Studio 2013 and supports SSAS and SSRS for SQL Server 2014 and earlier, but
SSIS projects are limited to SQL Server 2014. SQL Server 2014 does not install SSDT
BI, I have to download it from Microsoft Download Center at this link: Microsoft SQL Server Data Tools - Business Intelligence for
Visual Studio 2013 I get the file SSDTBI_x86_ENU.exe
and I run it. If you already have Visual Studio
2015 installed for C# programming you just need an add-in that you can
download from this link (Download SQL Server Data Tools (SSDT)): Microsoft
SQL Server Data Tools (SSDT) for Visual Studio 2015 After making a new SSIS project,
right click it and at properties set the property TargetServerVersion to SQL
Server 2014 (or 2012 or 2016). When the project knows which SQL Server
version you are develop SSIS packages for, and later deploy to and will be
running at. For SQL Server 2016 use SSDT
Microsoft Visual Studio 2015 that supports SSIS Integration Services for SQL
Server 2016. Since many computers now is using 64
bit to access more than 3.4 GB RAM it is important in the installation to
select "Perform a new installation of SQL Server 2014" because the
SQL Server is already 64 bit but the tool is 32 bit. This selection will not
create a new SQL Server instance:
Later I select "SQL Server Data
Tools - Business Intelligence for Visual Studio 2013" and I get a new
app in Windows 8.1 app list called SQL Server
Data Tools for Visual Studio 2013 (or maybe only Visual Studio 2013) "C:\Program
Files (x86)\Microsoft Visual Studio 12.0\Common7\IDE\devenv.exe" A Windows Update is good to make
again to get updates after the installation. SQL Server Data Tools - Business
Intelligence for Visual Studio 2013, new project:
SQL Server Integration Services Project
(SSIS) contains SSIS packages with .dtsx file because in SQL Server 2000 a
package was called Data Transformation Services (DTS), therefore Microsoft
add x to filename like docx, xlsx and pptx. When an SSIS packages is using Excel
and Access as source or destination, the server that is going to run the SSIS
package need this engine to be installed: Microsoft Office Engine Redistributable 2.6.
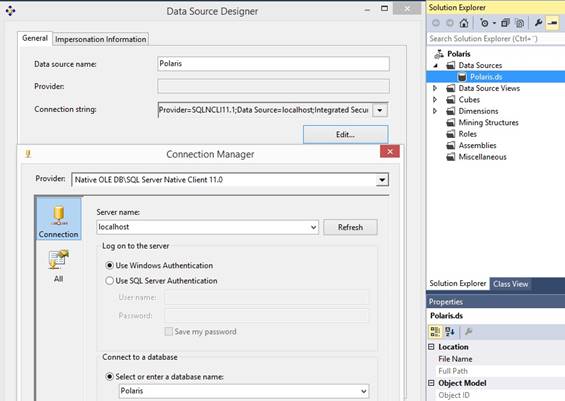
Setup before deployment of a SSAS Analysis Services Cube Deploy a cube from SQL Server Data
Tools for Visual Studio 2013 gives error messages like: OLE
DB error: OLE DB or ODBC error: Login failed for user 'NT
Service\MSSQLServerOLAPService'.; 28000. OLE
DB error: OLE DB or ODBC error: Login failed for user 'NT AUTHORITYANONYMOUS
LOGON'.; 28000. OLE
DB error: OLE DB or ODBC error: Login failed for user 'NT AUTHORITY\NETWORK
SERVICE'.; 28000; Cannot open database requested by the login. The login
failed.; 42000. Normally you will have a Windows AD
service account that is used for login for some of the services running at
the servers and that account will been granted reading access to some
databases, as described previously. Another simple solution is to grant
a service login to the database that Analysis Services Multidimensional and
Data Mining Project has a data source connected to. In Computer Administration under
Services there is a service called 'SQL Server Analysis Services' that has
property Logon to account like: NT
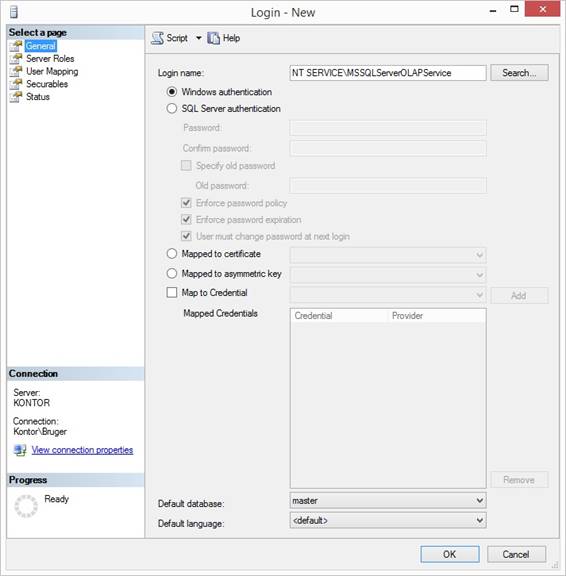
Service\MSSQLServerOLAPService or NT Service\MSOLAP$MSSQL2014. 1. Start SQL Server 2014
Management Studio SSMS. 2. Connect Database Engine
to the database server or localhost (.). 3. Under Security and under
Logins, right click {New Login} and typein Login name: NT
Service\MSSQLServerOLAPService or NT Service\MSOLAP$MSSQL2014. 4. Keep Windows
authentication and keep Default database master. 5. Click Server Roles and
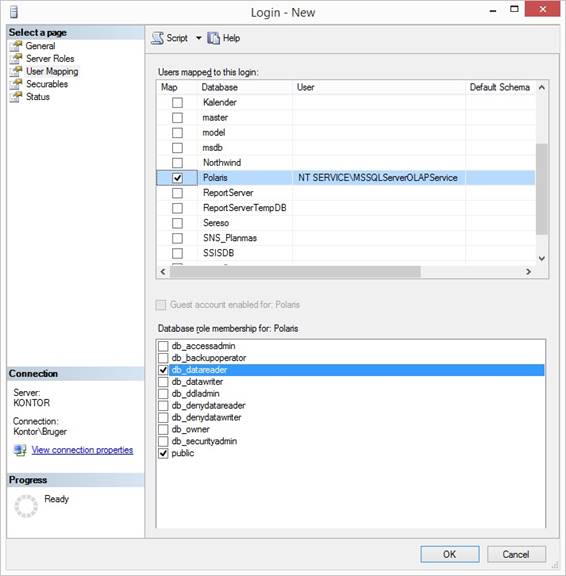
keep checkmark at public and no other checkmarks. 6. Click at page User
Mapping. 7. Set checkmark at the
database the cube will read or fetch data from. 8. Remember to set Default
Schema if the dimension tables and fact tables are placed in another schema
than dbo like: Dimensions and Facts. 9. At the buttom set
checkmark at db_datareader.
10. Setting at the cube
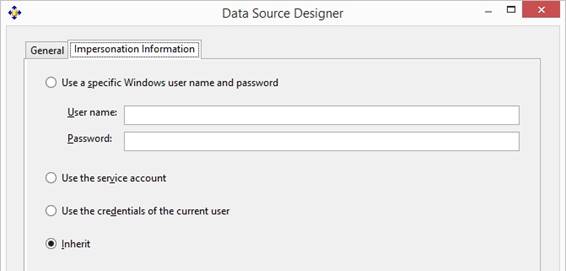
solution in SQL Server Data Tools for Visual Studio 2013 to the default
Impersonation Information called Inherit:
Localhost\instance name or .\instance
name in case SSAS is installed at an instance at the local PC or server.
Same for deployment of a cube to an SSAS instance. An alternative solution is changing
the service 'SQL Server Analysis Services' login to use 'Local System' account
but is not recommended at a server, only for a local PC. SSAS deployment by command line Tool Microsoft.AnalysisServices.Deployment.exe
works with the xml files which is created in the SSAS project's \bin folder
when I build the SSAS project. The four files can be copied to a .zip file
and open in Windows Explorer. I
like the SSAS deployment by command line with a bat file for each environment
development, test and production, here I making it for dev: 1.
Build the SSAS 'Polaris' project. 2.
From the folder \Polaris\bin I copy the four
files to a SSAS deployment folder I have made at my computer. 3.
In the deployment folder I have made a
file DEV_Polaris.bat with this line for deploy to a SQLDEV server to the
Analysis Services database: "%ProgramFiles(x86)%\Microsoft
SQL Server\120\Tools\Binn\ManagementStudio\ Microsoft.AnalysisServices.Deployment.exe"
Polaris.asdatabase 4.
I run the bat file and the deployment wizard
starts and asking for target server name. I could also in file Polaris.deploymenttargets
with Notepad have write in the target server name and I can use parameter
option /s for in silent mode and not display any dialog boxes from the
wizard. 5.
/o:Polaris.xmla /d runs wizard in output
mode so deployment will not occur, instead a xml for analysis (XMLA) script,
that would ordinarily be sent to the deployment target server, is saved to
the specified output script file. /d specifies that the wizard should not
connect to the target server the output script is generated based only on
information retrieved from the input files. I rightclick the Polaris.xmla
file and select Open so SQL Server Management Studio starts and shows the
deployment script and I click the button Execute to do the deploy of the cube
database. Later
it is easy to have other .bat files for test server and for production server
for deployment from my computer, or hand over the files to a person to do it
in test and later in production. 2.7.
Setup before a job process a SSAS Analysis Services Cube SQL Server Agent Job runs a job
under a special service account and then a job is using a SSIS package that
will process a cube, the service account need to have access to SSAS. In
Computer Administration under Services there is a service called 'SQL Server
Agent' that has property Logon to account like: NT Service\SQLSERVERAGENT or NT
SERVICE\SQLAgent$MSSQL2014. 1. Start SQL Server 2014
Management Studio SSMS. 2. Connect Analysis Services
to the server or localhost (.). 3. Right click the SSAS
server name and select {Properties}. 4. At page Security click
Add and typein Login name: NT
Service\SQLSERVERAGENT or NT SERVICE\SQLAgent$MSSQL2014. 2.8.
Setup before deployment of a SSRS Reporting Services report Deploy a report from SQL Server Data
Tools for Visual Studio 2013 gives error message like: The permissions
granted to user 'domain\username' are insufficient for performing this
operation Report
Manager URL: http://localhost/Reports or http://<servername>/Reports Reporting Services Report Manager also
called Report Server Web Interface. (http://localhost/ReportServer shows
a simple list). 1.
Right
click at Internet Explorer and select {Run as Administrator}. 2.
Typein
this url address: http://localhost/Reports 3.
You
may have to login with your computer's username and password. 4.
SQL
Server Reporting Services Home Menu is showned by this url: 5.
http://localhost/Reports/Pages/Folder.aspx 6.
Click
'Folder Setting' and 'New Role Assignment'. 7.
At
'Group or user name' typein your 'domain\username' (not Everyone, domain can
be localPC name or server name). 8.
Check
the checkbox Content Manager, it has all properties from the others roles Browser,
My Reports, Publisher, Report Builder. 9.
Click
OK. 10.
If
you later want to change do the same as above and after 'Folder Setting'
click at the Edit word of the line to change and end with click Apply. 11.
You
should be able to deploy the report
from SQL Server Data Tools for Visual Studio 2013. 12.
Start
Internet Explorer in normal way and in typein the URL address: http://localhost/Reports 13.
Click
the folder that has same name as the project and at the report that has same
name as the rdl file in the project. 14.
Sometime
also need to do a Site Settings but first has to right click at Internet
Explorer and select {Run as Administrator} and at the top-right-corner click 'Site
Settings'. 15.
Go
to the 'Security' page and click 'New Role Assignment'. 16.
Added
'domain\username' (not Everyone) as a System Administrator. System Administrator: View and modify
system role assignments, system role definitions, system properties, and
shared schedules. System User: View system properties,
shared schedules, and allow use of Report Builder or other clients that
execute report definitions. 17.
Sometimes
make sure you have access configured to the URL therefore do: 18.
Start
SQL Reporting Services Configuration. 19.
Connect
to the Report Server instance. 20.
Click
on 'Report Manager URL'. 21.
Click
the Advanced button. 22.
In
the Multiple Identities for Report Manager click Add. 23.
In
the Add a Report Manager HTTP URL popup box, select Host Header Name and type
in: localhost. 24.
Click
OK to save your changes. SQL Server 2014 Reporting Services
Configuration Manager is used to set up email smtp for sending report pdf
file to subscribers. Sometimes need to do Reporting
Services URLs to a trusted site in the browser. 1.
Right
click at Internet Explorer and select {Run as Administrator}. 2.
URL
address typein http://localhost/Reports 3.
Click
Tools. 4.
Click
Internet Options. 5.
Click
Security. 6.
Click
Trusted Sites. 7.
Click
Sites. 8.
Add
http://<servername>. 9.
Clear
the check box Require server certification (https:) for all sites in this
zone if you are not using HTTPS for the default site. 10.
Click
Add. 11.
Click
OK. You can not access all of the report
server properties available in SQL Server Management Studio unless you
start Management Studio with administrative privileges or do this settings: 1.
Right
click at SQL Server 2014 Management Studio and select {Run as Administrator}. 2.
Connect
to Reporting Services server. 3.
At
Security node click System Roles. 4.
Right
click System Administrator and then click Properties. 5.
Check
the checkbox 'View report server properties' and 'View shared schedules'. 6.
Click
OK. 7.
Exit
SQL Server 2014 Management Studio and start in normal way. 2.9.
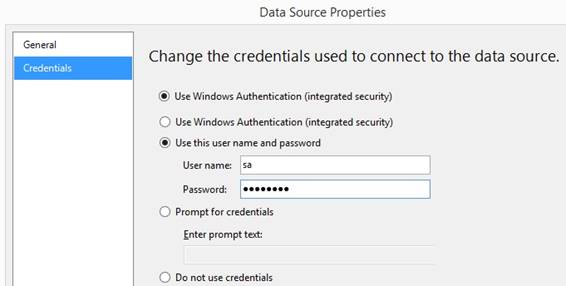
SSRS Credentials In SQL Server Data Tools for Visual
Studio 2013 a data source (shared among multiple reports in a project or
embedded in one report) has Credentials by right click the name of the data
source and select {Data Source Properties} and can be set like:
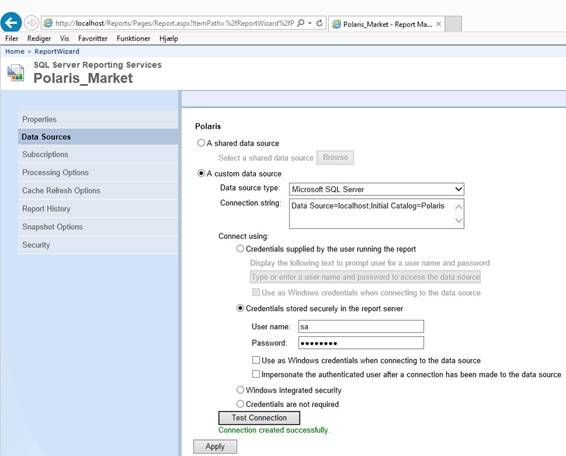
Subscription to a report in Report
Manager gives error message like: Subscriptions cannot
be created because the credentials used to run the report are not stored, or
if a linked report, the link is no longer valid In http://localhost/Reports or http://<servername>/Reports: 1.
Click
the folder with the same name as the report project name and it will open and
show one or multiple reports that has been deployed. 2.
At
one report set the mouse above the reportname and click on the arrow […] at
the right side to open the report menu and then click Manage. 3.
Inside
the report server management you see properties where it is a good idea to
write in textbox Description the time you want the report to run. 4.
Click
at the page 'Data Sources' and select the wanted credentials because the
subscription will make a SQL Agent Job that will call a stored procedure in
the database ReportServer and therefore need an account to login with:
5.
Click
[Test Connection] and [Apply]. 6.
Click
at the page 'Subscriptions' and [New Subscription] or [New Data-driven
Subscription] when you like to control who receive email with report. An AD windows group can also be
added to the Data Source and user members of the group will get access. Access to
folder When you place your reports in a
folder, you need to grant access to the folder with click on the arrow […] at the right side to open the report
menu and then click Manage. Access to
stored procedure Often a report dataset is calling a
stored procedure in a sql server database and the stored procedure can be
placed in dbo or another schema. Therefore we need to grant execute access
the the schema in SQL Server Management Studio in the database under Security
by right click at the schema, select Properties, in the dialogbox make sure
in page General that schema owner is dbo and in page Permissions click the
Search button and insert the AD windows group name (domain\group). After the
OK click you have to set checkmark in a column called Grant for Execute and
for Select. After OK click again, the access has been granted and if you open
the dialogbox again you can see the column Grantor has dbo with Execute and
Select. 2.10.
SSRS log file When
a report gives an error more information can be found in a log file: X:\Program
Files\Microsoft SQL Server\MSRS12.MSSQLSERVER\Reporting Services\LogFiles 2.11.
Toolbox in Visual Studio If the Report toolbox with
Parameters and Dataset is gone, you get it back at menubar {View} and {Report
Data}. 2.12.
SQL Server Management Studio 21 SQL Server Management Studio 21.5.14
version has changed the default value for Command Timeout from 0 to 30
seconds, which can give you an error message when your query runs for a long
time. In Connection dialog box under
Advanced you can change it back to 0 and avoid: "Execution Timeout Expired. The
timeout period elapsed prior to completion of the operation or the server is
not responding." You can still stop your query as
usual :)
3.
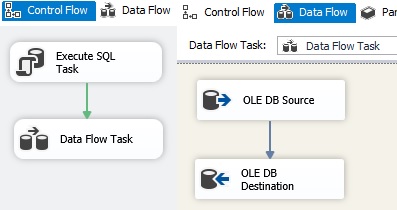
SSIS package architecture and deployment SQL Server Data Tools for Business Intelligence
has two modes of SSIS package deployment:
I recommend a SSIS architecture by
implementation of several Integration Services Projects for the entire ETL
process like projects for:
I recommend that each SSIS package
in a project is prefix with the name of the project so each SSIS package name
is unique in the organization. Project
Deployment Model tips
Before deployment of a project I
need to create a SSISDB Catalog: 1. Start SQL Server
Management Studio. 2. Connect to the Database
Engine. 3. In the tree right click at
'Integration Services Catalogs' and select {Create Catalog}. 4. Check 'Enable CLR
Integration'. 5. Check 'Enable automatic
execution of Integration Services stored procedure at SQL Server startup' to
enable the catalog.startup stored procedure to run each time the SSIS server
instance is restarted and performs maintenance of the state of operations
for the SSISDB catalog. It fixes the status of any packages there were
running if and when the SSIS server instance goes down. 6. Enter a password twice. In SQL Server Management Studio
under 'Integration Services Catalogs' there is a SSISDB catalog and right click
at it and select {Create Folder} to make a SSISDB folder for the later SSIS project
deployment. I calling the folder Production. Back to the project in SQL Server
Data Tools for Visual Studio 2013 I right click the project name and select
{Deploy}, select the SQL Server to receive the deployment and a Path which is
the folder that I created before or I can click at Browser button. The folder
will contain the project and all of its SSIS packages that are deployed at
the same time and later replaced by new version release. I can execute a
deployed IS package and get a report with execution data. The
SQL Server got a new database called SSISDB for the SSISDB catalog created
above and I can seen it in Management Studio. SSISDB contains deployment and
runtime versions of SSIS packages and all their objects can been seen in
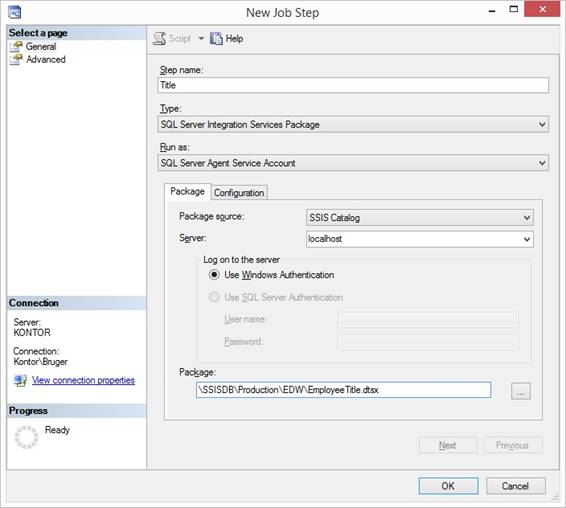
table called executable_statistics and package name in table called executables. SQL Server Agent Job SSIS package
calling When the SSIS packages is deployed
into the SSISDB catalog, I can call or execute the package from a SQL Server
Agent Job like 4 am in the morning. The job step properties are set to like
this:
Poject
Deployment Model with SQL Server based connection string My SSIS packages is placed into one
or several SSIS projects (.sln solution file), like a project for each layer
in my data warehouse system architecture. I can run a SSIS package manually
from the SQL Server Data Tools - Business Intelligence for Visual Studio 2013
and when it is finish, I can do a deployment to a SQL Server. I don't need
XML or dedicated SQL table to save my configuration strings because I can
save it in the SSISDB catalog and I can make sure only dba has access. Before I deploy a SSIS project to
the SSISDB catalog, I organize SSISDB catalog with folders where a folder
represent a data warehouse system like a folder called CustomerSalesDW. If I
don’t have access to SSISDB catalog, I can be granted to a role that is set
up inside the real SSIS database under Security, Role or Users (maybe Owner
dbo). At the created SSISDB folder in next section, right click the folder
and select {Properties} and go to Permissions page and browse the role and
grant Read, Modify or Execute rights. Making deployment folder and
environment variable for connection string In SQL Server 2014 Management Studio
SSMS I open Integration Services Catalogs, right click at SSISDB catalog
and select {Create Folder} and typein a folder name. A SSISDB folder contains
the deployment of the whole data warehouse system and the SSISDB folder has
two subfolders:
I like to have only one environment
with name Configuration and I will make the same setup in my different SQL
Servers environments for Development, Test, Pre production and Production and
with different connection strings for each environment. I make an Environments folder by
right click at Environments and select {Create Environment} and typein name
Configuration. I right click at Configuration and select {Properties} and at
Variables page I make variables for each connection string like a variable
called: DSAconnectionstring with Value as a real connection string: Data
Source=DEV;Initial Catalog=DSA;Provider=SQLNCLI11.1;Integrated
Security=SSPI;Auto Translate=False; Data
Source=<sql server name>;Initial Catalog=<database
name>;Provider=SQLNCLI11.1; Integrated
Security=SSPI;Auto Translate=False; At Permissions page I can grant Read
or Modify permissions to SQL Server logins or roles in the environment so I
can safeguard connection strings and passwords. The idea with the environment
variable is that I inside the SSISDB catalog can map an environment variable
to a parameter in a SSIS project and that mapping is kept every time I deploy
the SSIS project to the SSISDB catalog to each of the SQL Servers. Therefore
my deployment procedure will be very easy and I only need to do maintenance
of SSISDB catalog when there is a new connection string. Making SSIS project Parameter for connection
string (other method in the next) 1. In a SSIS project I want
a connection to my Development SQL Server so I make a new Connection Manager
and choose type OLEDB because it will use the provider: Native OLE DB\SQL
Server Native Client 11.0. I rename the connection manager to
DSAconnectionstring.conmgr. 2. I can not from Solution
Explorer parameterize a connection manager, but I can do it inside a package,
down in the Connection Managers tray where all connections are shown. There
I right click at (project)DSAconnectionstring and select {Parameterize} and
in the dialogbox I name the parameter DSAconnectionstring and click OK. In
Connection Managers tray it is shown as a fx symbol. 3. Now it is very important
inside the package to click [Save All] button in the toolbar because it will
save the new parameter and add it to the connection manager. 4. I like to see parameter
so in Solution Explorer I doubleclick at Project.params. When a parameter is
Sensitive its value will be encrypted when the project is deployed to the
SSIS catalog. Required should be False because True indicates that it is
mandatory to pass a value to the parameter before the package can be executed
from SQL Server Agent Job. 5. I like to see parameter
inside connection manager so in Solution Explorer I right click at
DSAconnectionstring.conmgr and {View Code} and see:
DTS:Name="ConnectionString">@[$Project::DSAconnectionstring]</DTS:PropertyExpression> 6. I will make a package
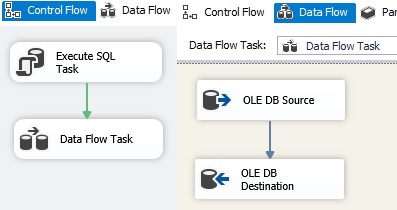
with a data flow inside the DSA database from a source table to a destination
table and save the package and project. I do some tests. 7. I will deploy the SSIS project
to the Integration Services Catalogs SSISDB catalog to the SSISDB folder I created
before, so in Solution Explorer I right click at topnode and {Deploy},
typein the SQL Server name and browse to the SSISDB folder. From SQL Server
2016 deploying individual SSIS packages is possible with right-click on a
package and {Deploy Package}. 8. Back in SSMS I refresh
the SSISDB catalog and inside the SSISDB folder I see the deployed SSIS
project. I will map the SSISDB environment variable to the parameter inside
the SSIS project by right click at the SSIS project and {Configure}. 9. At References page I
click [Add] and browse to SSISDB catalog, SSISDB folder and select enviroment
Configuration. At Parameters page I see the SSIS project parameter
DSAconnectionstring and I click at ellipsis [...] and in dialogbox in buttom
I map the parameter to 'Use environment variable' called DSA-connectionstring.
Finish with OK. In case a SSIS project does not has
parameter for connection, it is possible to typein the connection string as a
value for the Environment under the Parameters page from step 9 above under a
tab called Connection Managers. Execute SSIS package using the
environment variable connection string To execute a SSIS package from SSMS
inside Integration Services Catalogs, SSISDB catalog, SSISDB folder, SSIS
project, I right click at SSIS package and select {Execute} and in the
dialogbox in buttom I set a checkmark at Environment and OK and package will
run. To execute a SSIS package from SQL
Agent job and use the environment variable, I use step type 'SQL Server
Integration Services Package', Package source 'SSIS Catalog', Server
'localhost', and I browse to the SSIS package with ellipsis [...] at the SSISDB
catalog\SSISDB folder\SSIS project\SSIS package. At tab Configuration in
buttom I set a checkmark at Environment and OK. Job is ready to Start. To execute a SSIS package from a
third-party scheduling tool it is using dtexec from "%ProgramFiles%\Microsoft
SQL Server\120\DTS\Binn\DTExec.exe"
An example of a RunSSISpackage.cmd
file contents to be run from a SQL Agent Job as type Operating system
(CmdExec) with command as path\filename or from a TWS job through a TWS
client installed at the SQL Server, example: C:\SSISPACKAGE\SSIS\RunSSISpackage.cmd @echo
off SET
"PackageName=LoadCustomer" SET
"ErrorLogFolder=C:\SSISPACKAGE\SSIS\ErrorLog" "C:\Program
Files\Microsoft SQL Server\120\DTS\Binn\DTExec.exe" /ISSERVER
"\"\SSISDB\Load\LoadCustomer.dtsx\"" /SERVER localhost /ENVREFERENCE
2 /Par "\"$ServerOption::LOGGING_LEVEL(Int16)\"";100 /Par "\"$ServerOption::SYNCHRONIZED(Boolean)\"";True
/CALLERINFO SQLAGENT /REPORTING E || goto :error echo.
echo.
echo
Success with exit code #%errorlevel%. goto
:EOF :error echo. echo.
echo
Failed with exit code #%errorlevel%. echo.
echo
Errors in file %ErrorLogFolder%\%PackageName%.txt sqlcmd
-S LOCALHOST -y 2000 -E -o %ErrorLogFolder%\%PackageName%.txt -u -Q "EXEC Audit.dbo.SSISDBGetErrorMessage
'%PackageName%'" exit
/b 1 In an Audit database there is a
stored procedure that fetch an error that the Error event from the SSIS
package has inserted in a database table to write the error message to a log
fil, specially good for TWS operation monitoring. The other SQL Servers At the other SQL Servers I need to
do the same setup just with a different connection string for SQL Servers
for Test, Preproduction and Production where the database name can also is
different in the connection string. After this setup I can deploy a SSIS
project to any SQL Server without thinking of which connection string the
server is using. Making SSIS project Connection
Managers for connection string, no project params This approach do not use project
parameters to keep connection string, instead it is using a Connection
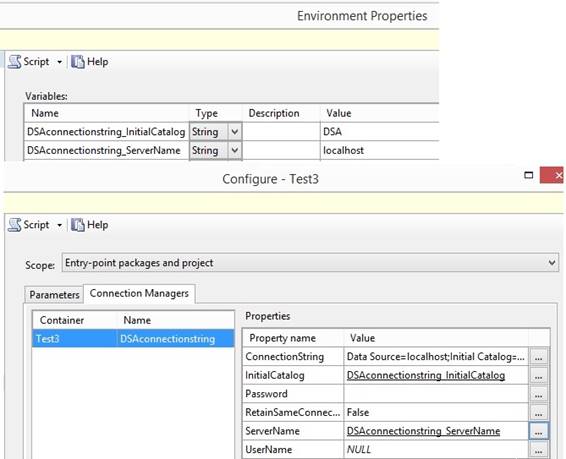
Managers inside Integration Services Catalogs. 1. Want to make two environments
variable inside Integration Services Catalogs at the folder you made for your
ssis packages to be deployed into:
2. Add the two variables to
Connection Managers from SSMS inside Integration Services Catalogs, SSISDB
catalog and inside your folder under SSISDB. 3. After deployment of a
SSIS project to the folder under SSISDB, I right click at SSIS project and
select {Configure} and a dialogbox is open on the screen. 4. I click at page
References and I click the Add button and point out the enviroment variable I
already made in SSISDB under a folder. 5. In the same dialogbox I
click at page Parameters and I click at tab 'Connection Managers'. 6. In the list I select
container DSAconnectionstring and in the right side under properties I
select InitialCatalog. 7. I click at ellipsis [...]
and in a new dialogbox in buttom I select 'Use enviroment variable' and in
drop down I select DSAconnectionstring_InitialCatalog. 8. In the list I select
container DSAconnectionstring again and in the right side under properties
I select ServerName. 9. I click at ellipsis [...]
and in a new dialogbox in buttom I select 'Use enviroment variable' and in
drop down I select DSAconnectionstring_ServerName.
To execute a SSIS package from SSMS
inside Integration Services Catalogs, SSISDB catalog, SSISDB folder, SSIS
project, I right click at SSIS package and select {Execute} and in the
dialogbox in buttom I set a checkmark at Environment and OK and package will
run. I do almost the same when I set up a sql server agent job. SSIS deployment by command line Tool ISDeploymentWizard.exe works
with the .ispac binary file which is created in the SSIS project's
\bin\Development folder when I build the SSIS project. The .ispac file can be
copied to a .zip file and open in Windows Explorer. I
like the SSIS deployment by command line with a bat file for each environment
development, test and production, here I making it for dev: 1.
Build the SSIS 'Northwind' project. 2.
From the folder \Source\Northwind\bin\Development
I copy the file Nortwind.ispac to a SSIS deployment folder I have made at my
computer. 3.
In the deployment folder I have made a
file DEV_Northwind.bat with this line for deploy to a SQLDEV server to the
SSISDB catalog folder Source:
"%ProgramFiles%\Microsoft SQL
Server\120\DTS\Binn\ISDeploymentWizard.exe" /S /ST:File
/SP:Northwind.ispac /DS:SQLDEV /DP:/SSISDB/Source/Northwind The notation is: "%ProgramFiles%\Microsoft SQL
Server\120\DTS\Binn\ISDeploymentWizard.exe" /S /ST:File
/SP:<SSIS project name>.ispac /DS:<SQL Server name>
/DP:/SSISDB/<SSISDB folder name>/<SSIS project name> 4.
I run the bat file and the deployment is
done to the dev sql server. Later
it is easy to have other .bat files for test server and for production server
for deployment from my computer, or hand over the Northwind.ispac file to a
person to do it in test and later in production. Extra information SSIS project at Connection manager {View
Code} with the project parameter @[$Project::DSAconnectionstring] run
mode replace the DTS:ConnectionString <?xml
version="1.0"?> <DTS:ConnectionManager
xmlns:DTS="www.microsoft.com/SqlServer/Dts"
DTS:ObjectName="DSAconnectionstring"
DTS:DTSID="{3795174E-55F8-42D1-B447-91C5121F97CE}" DTS:CreationName="OLEDB"> <DTS:PropertyExpression
DTS:Name="ConnectionString">@[$Project::DSAconnectionstring]</DTS:PropertyExpression> <DTS:ObjectData> <DTS:ConnectionManager DTS:ConnectionString="Data
Source=<sql server name>;Initial Catalog=<database name>;
Provider=SQLNCLI11.1;Integrated Security=SSPI;Auto
Translate=False;" /> </DTS:ObjectData> </DTS:ConnectionManager> Limitation of SSIS project parameter SSIS project parameter can be used
like variable in SSIS package with a few exceptions. It is possible to
assign values to them and to use them within expressions for different
components. Unfortunately it is not possible to replace variables at all by
parameters, as they cannot store results from 'Execute SQL Tasks '.
Therefore I find parameters used for configuration purposes, fixed values for
a package and for sending values around packages in runtime mode. Alternative
approach to Environment variable with Configuration Manager Instead of having connection strings
in environment variables inside SSISDB catalog they can be placed inside
SSIS project using the Configuration Manager inside the properties for the
project, where to click at button [Configuration Manager]. There is a default
configuration called Development and in dropdown 'Active solution
configuration' I select <New> to make new solution configuration for
Test, Pre production and Production with copy settings from Development and
create new project configuration. It is in the same dropdown where I pick
which configuration mode the SSIS project is using before build and deploy. Properties
'Server name' and 'Server Project Path' tells for each configuration where to
deploy the project. I go to project parameters and in
the small toolbar I click at button [Add Parameters to Configurations] to connect
parameters to each configuration and I can typein different connection
strings, so each parameter has different values for each configuration inside
the SSIS project. Now I have configurations for each
SQL Server and I can easily pick one to be the active and the parameter will
use the right connection string to that SQL Server. I pick configuration
Test, I build the project and I deploy the project to the Test server and it
will use the Test connection from the parameter in runtime mode. The disadvantage
with this approach is that I have to pick an active configuration mode before
build and deploy, but I am not using any environment variable in SSISDB catalog
and therefore I do not need to set them up and configure them to the SSIS project
at each SQL Server. Alternative
approach to Environment variable with server alias In tool SQL Server 2014
Configuration Manager is it possible to create an alias that can connect to
same (localhost .) SQL Server or to another SQL Server. When the same alias
(name) is setup at Developer server, Test, Preproduction and Production
server, the alias can be used inside a SSIS project connection managers or
inside SSAS or SSRS data sources as a 'Server name'. Then there is no need to
change connection string and server name when a project is deployed to different
servers because they all use the same alias and that alias is defined for
each server enviroments. In tool SQL Server 2014
Configuration Manager under node SQL Native Client 11.0 Configuration (32bit)
and under node SQL Native Client 11.0 Configuration do this: 1. Open the node and right click
at Aliases and select {New Alias}. 2. Typein the Alias name. 3. Typein Server name like localhost,
. or name of another SQL Server. 4. Select Protocal like Named
Pipes. 5. Typein Port no like
\\\pipe\sql\query or \\.\pipe\MSSQL$MSSQL2014\sql\query. On an Analysis Services server that
will load data from another SQL Server, it can also be through an alias. Use
Start, Run, cliconfg.exe and at the Alias tab click Add, then typein the
connection details, select TCP/IP and typein the SQL Server name in the
format servername\instancename. Inside the Analysis Services project open
data source and change the server name to the alias name and the provider is
still the normal Native OLE DB\SQL Server Native Client 11.0. In case of
local development at your PC, you can make the same alias so your
deployment later will be easy because of reuse of alias name but at your PC
and the servers the alias name point to different database servers. Alternative
approach is to have a database table with connection strings Normally the SSIS packages is
running from the data warehouse database server and therefore connection to
the databases can use localhost or . But for source systems we need the connection
strings and with this approach they are stored in a table as rows and the
SSIS package will fetch them when needed. Each SQL Servers environments for
Development, Test, Pre production and Production can have different connection
strings stored in the table. I create a database called ETL_SYSTEM with a
table called Source with source system connection strings and I show an
implementation in chapter '16. SSIS package gets connection string from a
table' at Tips
for SSIS SQL Server Integration Services. Run
SSIS packages by SQL Server Agent job with a proxy account Many dba people like to use a proxy account
for a SQL Server Agent Job Step to control access and using a Windows Server AD
Service Account when it is running a SSIS package and process a SSAS cube.
With a proxy account we can override the normal SQL Server Agent Service Account
and the proxy account can get access to SSISDB (and msdb), SSAS and SSRS, and
the Windows AD Service account maybe also has access to folders at some
servers to fetch data or to deliver files. In SQL Server 2014 Management Studio
the AD Service account is created as a Login under Security and under User
Mapping checkmark SSISDB and no need for property ssis_admin. Then create a Credential under
Security for the AD Service account as Identity with its password. Then create a Proxy account under
SQL Server Agent under Proxies that will use the made credential and
checkmark property "SQL Server Integration Services Package".
Alternative without credential use the Principals page for the Proxy account. Then in a specific SQL Server Agent Job
under Properties under Steps page at the "Run as" dropdown box I
replace "SQL Server Agent Service Account" with the made proxy
account that will be used for running that step which is executing a SSIS
package deployed in SSISDB (or msdb, see next section). Package
Deployment Model tips
From SQL Server Data Tools for
Business Intelligence (SSDT BI) I make a new or open an Integration
Services Project and in the menu I select {Project} and {Convert to Package
Deployment Model} to change the model of the project. Don’t save sensitive connectionstring
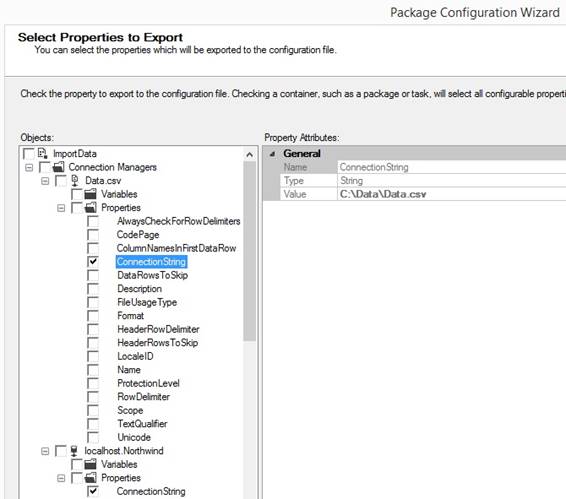
and use of package XML configuration file When I design a SSIS package and all
the connections to files and databases are made, I set the Protection Level
to DontSaveSensitive and I right click in the canvas of the package and
select {Package Configurations}. I check "Enable package
configuration" and I add a XML configuration file and placed it in the SSIS_Config
folder and name the xml .dtsConfig file with the same name of the package. I
only check ConnectionString for each connection to be saved as sensitive
data in the xml configuration file:
The SQL Server name is saved in the configuration
file so the xml config file at the developer server can be copied to the test
or production server, I only need to open it the xml file in Nodepad and
change the server name. SSIS packages can use several configuration files for
different connections and there can be a general xml config file with
connection to a SQL Server that will be refered to from all packages. Copy a SSIS package from developer server
to test or production server I copy the package .dtsx file and
the xml configuration .dtsConfig file from developer server to the test or production
server into a new release folder (like R001, R002…) where I open a new .dtsConfig
file in Nodepad to correct the connection and then copy the .dtsConfig file
to the SSIS_Config folder. I like to have simular SSIS project
at developer server as at test or production server, therefore I will first
at test or production server open the SSIS project and delete an existing
package. Then I will right click "SSIS Packages" and select {Add
Existing Package} I find the SSIS package .dtsx file from the release folder
and it will be added or copied into the project. With this method I can update one package in a project with many
packages without interfere the other packages in the production project.
I can rebuild the project as a kind of compile. I think a SSIS package .dtsx file is
like a source code for a exe/dll program, therefore I think it is very
important to have the current .dtsx file at the server where the SSIS package
is running in case of debug the ETL process. And it will be the server .dtsx
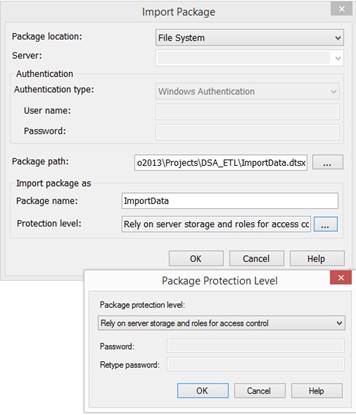
file that will be deployed for the ETL process. Deploying a SSIS package into MSDB
at a SQL Server At a SQL Server I start SQL Server
2014 Management Studio and connect to Integration Services: 1.
Open
node "Stored Packages" and open node "MSDB": 2.
Right
click at node "MSDB". 3.
Select
{Import Package} and set up the import specifications: 4.
Package
location will be File System. 5.
Find
the SSIS package .dtsx file from the solution \ project folder. 6.
In
Protection level select "Rely on server storage and roles for access
control". 7.
After
OK, remember to key press F5 when "MSDB" has focus so the tree will
be refreshed to show the new imported package. 8.
F 9.
G 10.
H 11.
J 12.
A imported package can be started to
run by right click and select {Run Package}. When a package is running it
will be using the connectionstring from the .dtsConfig file that was added to
the package .dtsx file and developers with access to the test server can
start Server Data Tools for Business Intelligence and open an Integration
Services Project and open/design the package for maintenance and run it on
the screen to identify a running failure caused by bad data from legacy
system. I’m not a fan of Package
Installation Wizard, I really like to be 100% in control of each deployed
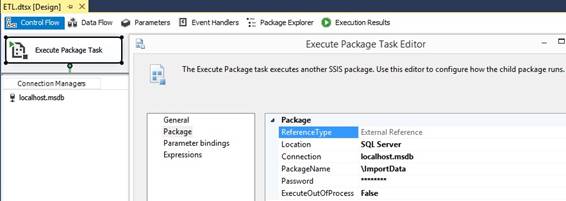
SSIS package to Integration Services at test and production server. Parent child SSIS package calling When I want a SSIS package to call or
execute another package, I first deploy the called child package into MSDB and
in the calling parent package through SQL Server Data Tools for Business
Intelligence (SSDT BI) I will make an extra connection to the MSDB database
and add a "Execute Package Task" and Edit it with properties
where I don’t type in any password so the *** is already there and has no
meaning here:
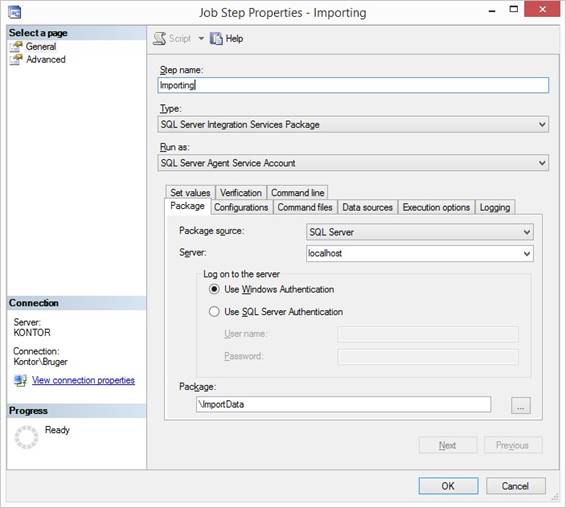
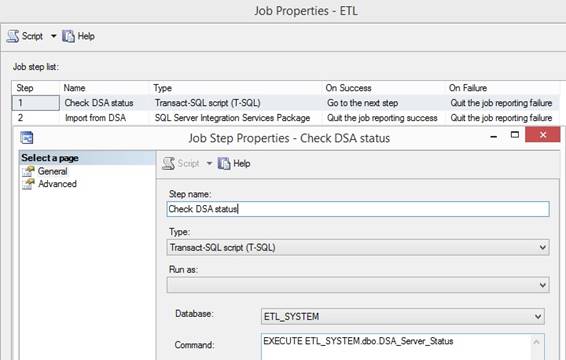
SQL Server Agent Job SSIS package calling When the SSIS packages is deployed into
the MSDB database, I can call or execute the package from the SQL Server
Agent Job like 4 am in the morning after the new data is ready from the
legacy system and ETL will be finish before the users logon later in the
morning to make their analyzes. The job step properties are set to:
In case of using a proxy account,
the security login needs in User Mapping to checkmark msdb database and db_ssisoperator
and then and Create Credential and Create Proxy and use it as "Run as"
in a SQL Server Agent Job Step. 4.
Sending email with status of the ETL process Before a stored procedure or a SQL Server
Agent Job can send an email I have to set up an email sender operator that
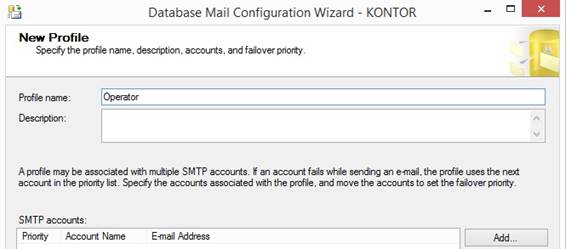
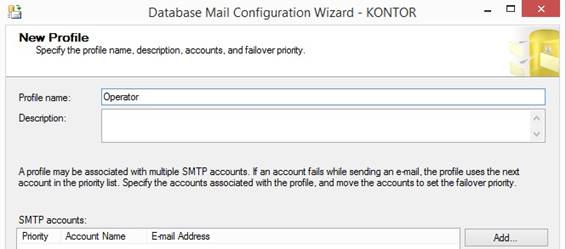
will send the email from an email address through SMTP. Database Mail sender of email I will in SQL Server 2014 Management
Studio connect to a SQL Server where I select in the tree 'Management' and 'Database
Mail' and right click and select {Configure Database Mail} and type in a
Profile name (here Operator) that will be used later for sending an email
from a stored procedure or a SQL Server Agent Job:
In the dialogbox I click [Add] and to
set up an account for sending an email through a SMTP server URL or an
IP-address. The E-mail address represent the from email address that also can be a email-group-address. The to email address for a recipient person
to receive the email will be added later in a stored procedure or a SQL
Server Agent Job:
In the next screen I do no check at
Public or Private Profiles. In the tree the new Operator will
not be shown. Stored procedure sending an email A stored procedure can send an email
by using a Microsoft standard sp where I refer to the Operator profile name
from Database Mail as the sender (from)
of the email and at parameter recipients I write the to email address of a recipient person that
will receive the email and use ; to separate several email addresses. The string variable @text
will be the body text of the email created by the stored procedure when some
data is missing a receipt from the person who maintain the database. From
a stored procedure in language Transact-SQL (T-SQL): DECLARE @text as
nvarchar(1024) SET @text = '' IF EXISTS(SELECT 1 FROM
dbo.EDW_DB_CURRENT_CUSTOMER WITH(TABLOCK) WHERE Receipt = 0) SET @text = @text +
'EDW_DB_CURRENT_CUSTOMER is missing a receipt.' + CHAR(10) IF @tekst <> '' EXEC msdb.dbo.sp_send_dbmail @profile_name = 'Operator', @recipients = 'pete@abc.com', @subject = 'ETL status', @body = @text These kind of emails can be very usefull
for supervision of the ETL process and a stored procedure can make count of
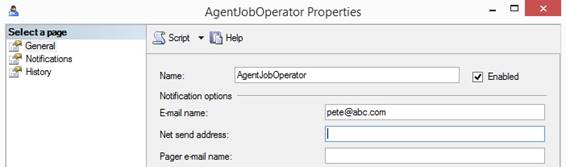
rows in tables and email the result and so on. SQL Agent Job sending an email A SQL Agent Job can send an email
with the status Succeeded or Failed after running an SSIS-package. First I
need to set up a recipient person’s email address in SQL Server 2014
Management Studio connected to a SQL Server where I select in the tree 'SQL
Server Agent' and 'Operators' and right click and select {New Operator} and type
in a Name (here AgentJobOperator). The E-mail name is the to email address of a recipient person
that will receive the email and use ; to separate several email addresses:
In the tree the new AgentJobOperator
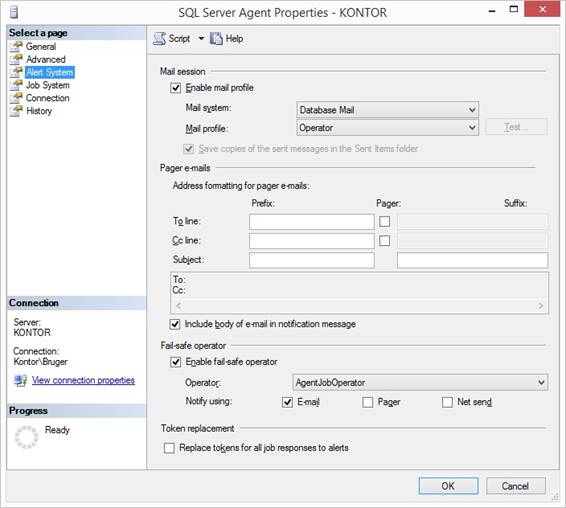
will be shown. Then I will set up email for jobs in
generel so I right click at 'SQL Server Agent' and select {Properties} and in
the pane I click at 'Alert System' where I refer to the Operator profile
name from Database Mail as the sender of the email as the from email address, and I refer to AgentJobOperator
from SQL Server Agent as the recipient
person’s email address as the
to email address in case of fails,
together with some checks like this:
Now it is very important to restart
to SQL Agent Job service so the setting will be invoked, I right click again
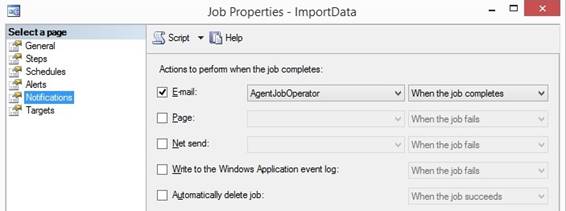
at 'SQL Server Agent' and select {Restart}. For each job I will refer to
AgentJobOperator from SQL Server Agent as the
recipient
person’s email address as the
to email address of the job
status. I right click at a job and select {Properties} and in the pane I
click at 'Notifications' where I select that the job will send a status when
it is completed:
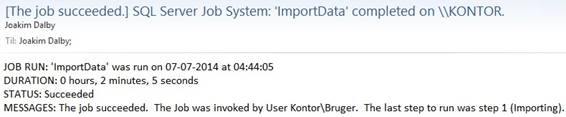
When the job is running it will in
the ending send an email with the status so the AgentJobOperator of the ETL
process can see the status of the job and see the duration time to compare if
it is as expected or in case duration time is very short maybe the legacy
system did not submit data or in case duration time is very long maybe legacy
system submit double data or the SAN or SQL Server has suddenly become very
slow due to external loads. An example of an email from a job:
When a job has »STATUS: Failed« it
can be an error in the ETL process like a »primary key violation« or a stored
procedure that is missing. I will right click at the job and select {View
History} I can study the error message like this: »Message. Executed
as user: NT Service\SQLSERVERAGENT. Microsoft (R) SQL Server Execute Package
Utility Version 12.0.2000.8 for
64-bit Copyright (C) Microsoft
Corporation. All rights reserved.
Started: 21:42:57 Error: 2014-07-07 04:00:00.86 Code:
0xC002F210 Source: Truncate ImportData Execute SQL Task Description:
Executing the query "EXEC dbo.ImportData_Truncate" failed with the
following error: "Could not find
stored procedure 'dbo.ImportData_Truncate'.". Possible failure
reasons: Problems with the query, "ResultSet" property not set
correctly, parameters not set correctly, or connection not established
correctly. End Error DTExec: The package execution returned
DTSER_FAILURE (1). Started: 21:42:57
Finished: 21:42:57
Elapsed: 0.281 seconds. The package execution failed. The step failed.« SSIS package has a 'Send Mail Task'
where I need to type in the smtp address together with the from and to email
adresses. 5.
Migration from SQL Server 2000 When I like to migrate my database
from SQL Server 2000 or earlier to SQL Server 2014 there is no support from
Microsoft, because version 2014 can only read version 2005 which means that a
ten year old database in version 2000 (before 2005 was released) can’t be migrated
directly! I really need a version 2005, 2008, 2008 R2 or 2012 as the middle
man helper in the migration procedure like this: 1.
In
SQL Server 2000 backup the database to a bak file. 2.
Move
the backup bak file to another SQL Server like 2005 – 2012. 3.
Restore
the backup bak file into the SQL Server 2005 – 2012. 4.
Change
the database property to the SQL Server version in Compatibility level:
5.
Delete
the backup bak file. 6.
Backup
the database to a bak file. 7.
Move
the backup bak file to SQL Server 2014. 8.
Restore
the backup bak file into the SQL Server 2014. 9.
Change
the database property to the SQL Server 2014 in Compatibility level:
10.
Under
Files remember to set the owner normally an administrator. 11.
Delete
the backup bak file. 12.
Backup
the database to a bak file. 13.
Delete
the database but not the backup bak file. 14.
Restore
the backup bak file again into the SQL Server 2014. 6.
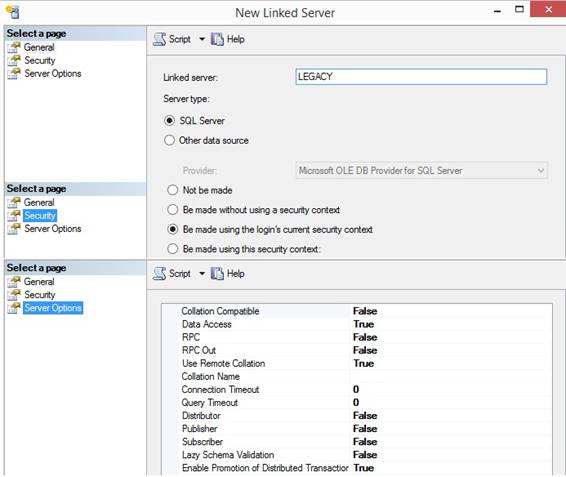
Get legacy system data through Linked Servers With Linked Servers I can connect to
another remote SQL Server, Oracle, DB2 or others and I can from a data warehouse
database Data Staging Area DSA send a query to the legacy database for
receiving some records from a table or view and at the same time getting the datatype
of columns with allow null. When I use 'SELECT *' all new columns in the
legacy table will be added automatically to the DSA table because I will
recreate the table. I can also rename column names from the legacy table to
my own language (danish) so the DSA table will use my column names in the
further ETL process. To set up a Linked Server in SQL
Server 2014 Management Studio connected to a SQL Server data warehouse:
I’m
calling the Linked
Servers for LEGACY, normally sql server use the servername. In
the DSA database I make a stored procedure to extract data based on a hired date
of employee as criteria parameter, transform english column names to danish
names and load data into the data
warehouse DSA database. Some
simple examples first with no criteria just to pull or fetch data from the
linked servers from the database Northwind from the table Employees and all
the columns: When
the linked server is a SQL server (linkedserver.database.schema.table): SELECT *
FROM LEGACY.Northwind.dbo.Employees With
a criteria from a variable: DECLARE @hiredDate datetime = '2014-02-07' -- latest
hired date SELECT *
FROM LEGACY.Northwind.dbo.Employees WHERE HiredDate > @hiredDate Join
between database and linked server but is bad for performance: SELECT *
FROM LEGACY.Northwind.dbo.Employees E INNER
JOIN dbo.Criteria C ON
C.Date = E.HiredDate But
often the linked server is another serverdatabase therefore using of
openquery: SELECT *
FROM OPENQUERY(LEGACY, 'SELECT * FROM Northwind.dbo.Employees') Pull
data rows into an on-the-fly created table DSA_Employees with select * into: IF EXISTS (SELECT 1 FROM INFORMATION_SCHEMA.TABLES WHERE
TABLE_SCHEMA = 'dbo'
AND
TABLE_NAME = 'DSA_Employees') DROP
TABLE dbo.DSA_Employees SELECT *
INTO dbo.DSA_Employees
FROM OPENQUERY(LEGACY, 'SELECT * FROM Northwind.dbo.Employees') It
is so nice that SQL Server create the table automatically with good data
types from the table Employees from the linked server database, also when it
is a Oracle or DB2 or others too. Primary key and identity column is
not included from the linked table. Pull
data rows into an empty table DSA_Employees: TRUNCATE TABLE dbo.DSA_Employees INSERT INTO
dbo.DSA_Employees SELECT *
FROM OPENQUERY(LEGACY, 'SELECT * FROM Northwind.dbo.Employees') Instead
of using linked servers there is a t-sql OPENROWSET command like this: SELECT a.* FROM OPENROWSET('SQLNCLI', 'Server=<server>;Trusted_Connection=yes;', 'SELECT
* FROM
Northwind.dbo.Employees') AS a Linked
servers with hardcoded criteria: SELECT *
FROM OPENQUERY(LEGACY, 'SELECT * FROM
Northwind.dbo.Employees WHERE HiredDate
> ''2014-07-02''') OPENQUERY
will send the sql select statement to the linked server but does not accept
variable or parameter therefore I need to use EXECUTE and the string mark ' char(39)
has to be double in use with a criteria in T-SQL variable with prefix @: EXECUTE ('SELECT * FROM OPENQUERY(LEGACY, ''SELECT *
FROM Northwind.dbo.Employees
WHERE HiredDate > '''''+@HiredDate+''''''')') With
variable as criterie for the latest HiredDate (normally yesterday because ETL
process runs every day) to extract new hired employees and insert them into
the table DSA_Employees: CREATE PROCEDURE
[dbo].[Extract_LEGACY_Employees] AS BEGIN SET NOCOUNT
ON DECLARE @Today date = CAST(GETDATE() AS date) DECLARE
@NumberOfRowsAffected int = 0 DECLARE @ErrorNumber int DECLARE @ErrorMessage nvarchar(500) DECLARE @HiredDate datetime SET @HiredDate = (SELECT ISNULL(MAX(HiredDate),'19000101') -- getting latest HiredDate FROM
dbo.DataReceptionLog -- for finding
new hired employees WHERE DataSource = 'Employees') -- of Employees data. BEGIN TRY IF
EXISTS (SELECT 1 FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA =
'dbo' AND
TABLE_NAME = 'DSA_Employees') DROP TABLE dbo.DSA_Employees -- if table already exists
it will be deleted and created again EXECUTE ('
-- and receive new hired employees as incremental delta data. SELECT
EmployeeID AS MedarbejderId, LastName AS Efternavn, FirstName AS Fornavn, -- renamed
columns BirthDate
AS Fødselsdag, HiredDate AS Ansættelsesdato, GETDATE() AS DSA_InsertTime INTO
dbo.DSA_Employees FROM OPENQUERY(LEGACY,
''SELECT EmployeeID, LastName, FirstName, BirthDate, HiredDate FROM
Northwind.dbo.Employees --
database.schema.table at Legacy lnksrv. WHERE HiredDate
> '''''+@HiredDate+''''''') ') SELECT
@NumberOfRowsAffected = @@ROWCOUNT,
@ErrorNumber = @@ERROR IF @ErrorNumber <>
0 SET @Today = '19000101' END TRY BEGIN CATCH SELECT
@ErrorNumber = ERROR_NUMBER(), @ErrorMessage =
ERROR_MESSAGE() SET @Today = '19000101' END CATCH SET @HiredDate = (SELECT ISNULL(MAX(Ansættelsesdato),'19000101') FROM dbo.DSA_Employees) INSERT INTO
dbo.DataReceptionLog(DataSource, ReceiptDateTime,
HiredDate, NumberOfRows, ErrorNumber,
ErrorMessage) VALUES('Employees', GETDATE(), @HiredDate, @NumberOfRowsAffected,
@ErrorNumber, @ErrorMessage) END The
table DataReceptionLog shows how many rows that is received at each ETL
process and column HiredDate is used to ask for only new hired employees
since latest ETL process. This is an incremental
loading also known as delta data
detection into the data warehouse and the select statement specify the
wanted columns from the legacy system for keeping the transfered data as a
minimum. In case of an error the DataReceptionLog will register that too like
this and when error is fixed the ETL process can be started again and be completed:
Instead
of sending a SELECT statement through the linked server I make a stored
procedure in the Northwind legacy database included the danish renamed
columns: CREATE PROCEDURE
[dbo].[Extract_Employees] @HiredDate date AS BEGIN SET
NOCOUNT ON SELECT EmployeeID AS MedarbejderId, LastName AS
Efternavn, FirstName AS
Fornavn,
BirthDate AS Fødselsdag, HiredDate AS
Ansættelsesdato FROM dbo.Employees WHERE HiredDate > @HiredDate END In
the DSA database I’m calling the stored procedure with a parameter in the EXECUTE
statement that replace the above: EXECUTE (' SELECT *,
GETDATE() AS DSA_InsertTime INTO
dbo.DSA_Employees FROM
OPENQUERY(LEGACY, ''Northwind.dbo.Extract_Employees '''''+@HiredDate+''''''') ') In
case of no criteria parameter I can instead make a view in the Northwind legacy
database and get data like this and insert them into the table DSA_Employees: SELECT *, GETDATE() AS DSA_InsertTime INTO dbo.DSA_Employees FROM OPENQUERY(LEGACY, 'SELECT * FROM
Northwind.dbo.Extract_Employees_View') CREATE VIEW [dbo].[Extract_Employees_View] AS SELECT EmployeeID AS MedarbejderId, LastName AS
Efternavn, FirstName AS
Fornavn,
BirthDate AS Fødselsdag, HiredDate AS
Ansættelsesdato FROM dbo.Employees I
can make a direct call to the stored procedure with the parameter but then I
first need to configured for linked server legacy a server option property
RPC Out changed to True (RPC stands for Remote Procedure Call): EXEC LEGACY.Northwind.dbo.Extract_Employees @HiredDate I
can also make a table-valued function in the Northwind legacy database
included the danish renamed columns: CREATE FUNCTION
[dbo].[Extraction_Employees](@HiredDate date) RETURNS TABLE AS RETURN ( SELECT EmployeeID AS MedarbejderId, LastName AS
Efternavn, FirstName AS
Fornavn,
BirthDate AS Fødselsdag, HiredDate AS
Ansættelsesdato FROM dbo.Employees WHERE HiredDate > @HiredDate ) Linked
server can't call a table-valued function but SQL server offers a new way
where the parameter don’t need all the ' and instead I empty the destination
table. I need to configure the linked
server a server option property RPC Out to True: TRUNCATE TABLE dbo.DSA_Employees INSERT INTO
dbo.DSA_Employees EXECUTE ('SELECT *, GETDATE() AS DSA_InsertTime FROM
Northwind.dbo.Extraction_Employees(?)', @HiredDate) AT
LEGACY The
'insert into' raise an error message: »MSDTC on server '<computer name>'
is unavailable« because a service called DTC Distributed Transaction
Coordinator is needed to be running at the SQL Server and is turned on in the
Computer Management. Check also for firewall issues there might be a need
to configure certain ports to allow firewall access. Synonyms Linked
servers between SQL Servers is using the name of server like this: SELECT *
FROM SQLTEST01.Northwind.dbo.Employees Which is a problem when moving the code to
production with servername SQLPROD01. Therefor setting up a synonyms for each
table from the linked server gives an alias effect so the sql statement is
unchanged when moving to production. In a test database like DSA I create a
synonym linked to test server: CREATE SYNONYM
[dbo].[Legacy_Employees] FOR [SQLTEST01].[Northwind].[dbo].[Employees] GO In a producton database like DSA I create a synonym
linked to production server: CREATE SYNONYM
[dbo].[Legacy_Employees] FOR [SQLPROD01].[Northwind].[dbo].[Employees] GO In the sql statement I use the synonym and therefore
easy to move to code later: SELECT *
FROM dbo.Legacy_Employees Sometimes people use different names of databases at
production server and test server, here can Synonyms be
a help with different definition at the two servers and I only need to be
change synonym when database is copied from prod to test: CREATE SYNONYM
[dbo].[Northwind_DB_Address] FOR [Northwind_Test].[dbo].[Address] GO CREATE SYNONYM
[dbo].[Northwind_DB_Address] FOR [Northwind_Prod].[dbo].[Address] GO CREATE VIEW
[dbo].[Northwind_Address] AS SELECT StreetName, ZipCode FROM dbo.Northwind_DB_Address GO ADO.Net
Oracle Client Data Provider connectors will work but is slow therefore using
Microsoft Oracle Source Component by Attunity but with multiple execution parallel
of SSIS packages can make job hanging (running forever) and warning in the
Integration Services Catalogs report: »Information: The buffer manager detected
that the system was low on virtual memory, but was unable to swap out any
buffers. 0 buffers were considered and 0 were locked. Either not enough
memory is available to the pipeline because not enough is installed, or other
processes are using it, or too many buffers are locked.« Then change the
execution from parallel to execute SSIS package in serial one-by-one way. 7.
Get a DSA server status through Linked Servers in a job I
like to have a DSA server (Data Staging Area) to receive data from legacy systems
and have a loging system that in the ending will make a status that will be
used at the data warehouse server in the ETL job to check if new data is
ready before starting transform and load into the data warehouse. At
the DSA server there is a database called DSA_LOG with a table called STATUS
that has a row for each status, typical per night when new data has been
received:
A
view will get the latest status in a row for today date: CREATE VIEW
[dbo].[DSA_Status] AS SELECT Status
= ISNULL(st.Status,0) FROM dbo.STATUS st INNER
JOIN ( SELECT
StatusId = MAX(StatusId) FROM dbo.STATUS WHERE CAST(StatusDateTime AS date) = CAST(Getdate() AS date) )
latest ON latest.StatusId
= st.StatusId WHERE CAST(st.StatusDateTime AS date) = CAST(Getdate() AS date) At the data warehouse server there is a database
called ETL_SYSTEM with a stored procedure that connect to DSA server and get
the status and is using raiseerror to throwing an errormessage that will make
a sql agent job to catch it and stop the job with a failure so the job will
stop and people will get an email and can handle on the status at the DSA
server: CREATE PROCEDURE
[dbo].[DSA_Server_Status] AS BEGIN BEGIN TRY SET NOCOUNT ON DECLARE
@DSA_Server_Status bit = 0 -- default value in
case the view will return no row. SELECT
@DSA_Server_Status = ISNULL(Status,0) FROM
OPENQUERY(DSASERVER, 'SELECT Status FROM DSA_LOG.dbo.DSA_Status') IF @DSA_Server_Status = 0 BEGIN RAISERROR('DSA server
status is failed therefore no new data and ETL job is stopped.', 2,
1) END END TRY BEGIN CATCH RAISERROR('DSA server
status is failed therefore no new data and ETL job is stopped.', 2,
1) END CATCH END The
stored procedure will be called or executed from a step in a sql agent job:
When
status is 1 (true) the first step is fine and the job continue to next step. When
status is 0 (false) the first step will fail and the job will stop with a
failure and in job view history the errormessage from stored procedure can
been seen in the buttom of the step details:
How
to see the running jobs: SELECT JobName = sj.name, Seconds = DATEDIFF(SECOND,aj.start_execution_date,GetDate()) FROM msdb..sysjobactivity aj INNER JOIN msdb..sysjobs sj on sj.job_id = aj.job_id WHERE aj.stop_execution_date IS NULL -- job hasn't
stopped running AND aj.start_execution_date IS NOT NULL -- job is currently running AND sj.name = '<JOBNAME>' AND NOT
EXISTS( -- make
sure this is the most recent run SELECT
1 FROM
msdb..sysjobactivity new WHERE
new.job_id =
aj.job_id AND
new.start_execution_date > aj.start_execution_date ) 8.
SSIS package versus Stored procedure SSIS package in solution\project
is a graphics tool of making ETL where sql statements will be insert into
different task objects like this:
In
the SSIS project I make a new Connection Manager and choose type OLEDB because
it will use the provider: Native OLE DB\SQL Server Native Client 11.0. Since
a Data Flow Task Destination don’t have a check for Truncate table, I need to
make a sql statement in beginning of Control Flow with: TRUNCATE
TABLE dbo.EmployeesTitle Inside
Data Flow Task Source I make a sql statement (select, view or exec stored
procedure with parameters): SELECT
EmployeeID, LastName, FirstName, Title, BirthDate, HiredDate FROM
dbo.Employees WHERE
Title = 'Sales Representative' In
SQL Profiler I can see sql statements send from the running package to SQL
Server because the Source and Destination need data to package memory: TRUNCATE
TABLE dbo.EmployeesTitle declare
@p1 int set
@p1=1 exec
sp_prepare @p1 output,NULL,N'SELECT EmployeeID, LastName, FirstName, Title, BirthDate,
HiredDate FROM dbo.Employees WHERE Title = ''Sales Representative''',1 select
@p1 insert
bulk [dbo].[EmployeesTitle]([EmployeeID] int,[LastName] nvarchar(20) collate
Danish_Norwegian_CI_AS,[FirstName] nvarchar(10) collate
Danish_Norwegian_CI_AS,[Title] nvarchar(30) collate Danish_Norwegian_CI_AS, [BirthDate]
date,[HiredDate] date)with(TABLOCK,CHECK_CONSTRAINTS) Stored procedure has a ETL process
and it is compiled and save very close to the data tables in the same database
and it can be tested directly from SQL Server 2014 Management Studio where
each sql statement can be execute step by step. The above graphic SSIS
package as a stored procedure that will do the same task: CREATE PROCEDURE
[dbo].[ETL_Employees_EmployeesTitle] AS BEGIN SET
NOCOUNT ON TRUNCATE
TABLE dbo.EmployeesTitle --
empty table for full dump INSERT
INTO dbo.EmployeesTitle
WITH(TABLOCK) -- load to
destination (EmployeeID, LastName,
FirstName ,Title,
BirthDate, HiredDate) SELECT
EmployeeID, LastName,
FirstName, Title,
BirthDate, HiredDate FROM
dbo.Employees WITH(TABLOCK)
-- extract from source WHERE Title =
'Sales Representative' END I
will make a SSIS package in a project to execute the stored procedure and a
package can contains several executions of stored procedures for a specific
ETL process to a small area of data (one or few tables) in the DSA, EDW or
DM. The transform part of ETL can use TMP tables and there can be INSERT
INTO, UPDATE and DELETE statements in stored procedures to enrichment and enhanced
data. |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
9.
Stored procedure to load a data mart In
a database like a EDW Enterprise Data Warehouse database I have created views
with subset of data to a data mart DM database. With two stored procedures it
is easy to make materialize views in EDW to created tables in DM. The views
are prefixed DATAMART_<tablename in datamart> like view
DATAMART_Customer and it will become a tablename dm.Customer in DataMart
database with schema dm (made with CREATE SCHEMA dm AUTHORIZATION
dbo). I use
SELECT * INTO to create the table in DataMart database and I have added a
UNION ALL that will always be false but it avoid the primary key identity
column to be a identity column in the table. Sadly there is no way to transfer
the primary key because the view could be a join among severals tables in EDW
database. CREATE PROCEDURE
[dbo].[DATAMART_Load_Create] AS BEGIN SET NOCOUNT ON DECLARE @ViewName AS nvarchar(50) DECLARE @TableName AS nvarchar(50) DECLARE Scan CURSOR LOCAL
FORWARD_ONLY DYNAMIC
FOR SELECT ViewName = TABLE_NAME FROM INFORMATION_SCHEMA.VIEWS WHERE TABLE_TYPE = 'VIEW'
AND TABLE_NAME LIKE
'DATAMART_%' OPEN Scan FETCH NEXT FROM
Scan INTO @ViewName WHILE @@FETCH_STATUS = 0 BEGIN SET @TableName = RIGHT(@ViewName,LEN(@ViewName)-9) EXECUTE ('IF EXISTS
(SELECT 1 FROM DataMart.INFORMATION_SCHEMA.TABLES WHERE
TABLE_SCHEMA = ''dm'' AND TABLE_NAME = ''' + @TableName + ''') DROP
TABLE DataMart.dm.[' +
@TableName +']') EXECUTE ('SELECT * INTO
DataMart.dm.[' +
@TableName + '] FROM
dbo.[' + @ViewName + '] UNION
ALL SELECT * FROM dbo.[' +
@ViewName + '] WHERE
1 = 0') FETCH NEXT FROM
Scan INTO @ViewName END CLOSE Scan DEALLOCATE Scan END Primary key can be set as design of
the table in SQL Server 2014 Management Studio or by a sql commando: ALTER TABLE
dm.Customer ADD CONSTRAINT
PK_Customer PRIMARY KEY
CLUSTERED (CustomerId) ON [PRIMARY] GO Stored procedure DATAMART_Load_Create
is only executed one time or in case views are changed, after that the ETL
process will use another stored procedure that’s empty the tables in DataMart
database and transfer the data. CREATE PROCEDURE
[dbo].[DATAMART_Load] AS BEGIN SET NOCOUNT ON DECLARE @ViewName AS nvarchar(50) DECLARE @TableName AS nvarchar(50) DECLARE Scan CURSOR LOCAL
FORWARD_ONLY DYNAMIC
FOR SELECT ViewName = TABLE_NAME FROM INFORMATION_SCHEMA.VIEWS WHERE TABLE_TYPE = 'VIEW'
AND TABLE_NAME LIKE
'DATAMART_%' OPEN Scan FETCH NEXT FROM
Scan INTO @ViewName WHILE @@FETCH_STATUS = 0 BEGIN SET @TableName = RIGHT(@ViewName,LEN(@ViewName)-9) EXECUTE ('TRUNCATE TABLE
DataMart.dm.[' + @TableName +']') EXECUTE ('INSERT INTO
DataMart.dm.[' +
@TableName + '] SELECT
* FROM dbo.[' + @ViewName + ']') FETCH NEXT FROM
Scan INTO @ViewName END CLOSE Scan DEALLOCATE Scan END I found this approach fast for maintenance
with new columns in an existing view or adding a new view, because I don’t
need to change stored procedures, just execute them. In a SSIS package I need
to change the Data Flow Task or add a new and type in a viewname in OLE DB
Source and tablename in OLE DE Destination and deploy the package, that’s a
lot of repetitive or trivially work. This approach works also for linked server
like shown earlier in the article, like this where I ask for data from a DSA
server: EXECUTE ('IF EXISTS (SELECT 1 FROM INFORMATION_SCHEMA.TABLES WHERE
TABLE_SCHEMA = ''dbo'' AND TABLE_NAME = ''' + @TableName + ''') DROP
TABLE dbo.' + @TableName) EXECUTE ('SELECT *, GETDATE() AS DSA_InsertTime INTO
dbo.' + @TableName + ' FROM OPENQUERY(DSA_SERVER,
''SELECT
* FROM LEGACY_VIEW.dbo.' +
@TableName + ''')') @TableName can be taking from a »metadata«
table in the database with rows for all the views or tables that I want to be
transferred. 10.
Identity column problem Yes I know Identity means that each
row has a unique number but I also think that Identity is like an autonumber
e.g. 1, 2, 3, 4 without any gap except when I delete a row. But since SQL
Server 2008 R2 Identity column do a jump by between 997 and 1000 in number
sequence and make a gap or a failed over e.g. 1206306, 1207306, 1208303,
because SQL Server use a cache size of 1000 when allocating identity values
in an int column and restarting the service lose unused values, the cache
size is 10000 for bigint column. One solution is to set SQL Server Startup
Parameter with trace flag -T272 by start SQL Server Configuration Manager,
click in left side at SQL Server Services and in right side, rightclick at
SQL Server (MSSQLSERVER), select Properties and tab Startup Parameters and
typein -T272 and click Add and Apply buttons. rightclick at SQL Server
(MSSQLSERVER) and select Restart. There is no assume and guarantee that an
identity column to be contiguous. Of course this setting will affect
all your databases at the SQL Server, therefore another solution could be
better than using Identity and that is using a Sequence column with No Cache
setting that you will make for each table and old Identity column. SQL Server table trigger is fire
once per statement but Oracle and mySQL has trigger for each row when engine InnoDB
AUTO_INCREMENT makes gaps: CREATE TRIGGER
`Customer_Before_Insert` BEFORE INSERT ON
`Customer` FOR EACH ROW BEGIN SET NEW.CustomerId = (SELECT
IFNULL(MAX(CustomerId), 0) + 1 FROM Customer); END mySQL Startup Parameter is edited in
file my.ini or my.cnf type in: innodb_autoinc_lock_mode=0 for traditional lock mode, restart mysql
server. 11.
Sequence column A sequence column is normally using
an unique number for the whole database compared to an Identity that is an
unique number for a table. First I need to create a sequence with a name and
parameters in SQL Server 2014 Management Studio under Programmability, Sequences
or by a sql script, where I make a sequence object called DataId to be used later as a default
value for a bigint column also called DataId in one or multiple tables in a
database for archive data from source systems, so the DataId values can be used
as a unique trace value through the data warehouse and data marts. CREATE SEQUENCE DataId AS
bigint START WITH
1 INCREMENT BY 1 NO CACHE -- to avoid gap in number or jump in number GO I have noticed at Azure that no
cache gives poor performance with loading many records. Cache 100 works and
will give a gap of 100 when the sql server is restarted. Then I can make a table that is
using the sequence as a default value like this: CREATE TABLE [dbo].[Archive_Order] ( [OrderID] [int] NOT NULL, [CustomerID] [nchar](5) NULL, [OrderDate] [datetime] NULL, [Quantity] [int] NULL, [DataId] [bigint] NOT NULL CONSTRAINT [DF_Archive_Order_DataId] DEFAULT(NEXT VALUE FOR dbo.DataId), CONSTRAINT [PK_Archive_Order] PRIMARY KEY CLUSTERED ( [OrderID] ASC ) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE =
OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 90) ON [PRIMARY] ) ON [PRIMARY] GO Or I can add a column to a table with a default
value using the sequence
and if the table has rows, the new column will be with values from the
sequence DataId: IF NOT EXISTS(SELECT 1 FROM INFORMATION_SCHEMA.COLUMNS WHERE
TABLE_NAME = 'Archive_Order'
AND COLUMN_NAME =
'DataId') BEGIN ALTER TABLE [dbo].[Archive_Order] ADD
[DataId] [bigint] NOT NULL CONSTRAINT [DF_Archive_Order_DataId] DEFAULT(NEXT VALUE FOR dbo.DataId) WITH VALUES END GO In case of adding the sequence
default value to an existing column, give the column the sequence values,
and make sure the column will never be null: ALTER TABLE [dbo].[Archive_Order] ADD CONSTRAINT
[DF_Archive_Order_DataId] DEFAULT(NEXT VALUE FOR dbo.DataId) FOR [DataId] GO UPDATE [dbo].[Archive_Order] SET DataId = NEXT VALUE FOR dbo.DataId GO ALTER TABLE [dbo].[Archive_Order] ALTER COLUMN [DataId]
[bigint] NOT NULL
GO When I insert data the sequence DataId
will do an auto incremental of its number: INSERT INTO dbo.Archive_Order WITH(TABLOCK) (OrderID, CustomerID, OrderDate,
Quantity) SELECT OrderID, CustomerID, OrderDate,
Quantity FROM dbo.Source_Order WITH(TABLOCK) Same will happen in a SSIS package
and no extra option in FastLoadOptions. In case I want an index for the
sequence column: ALTER TABLE [dbo].[Archive_Order] ADD CONSTRAINT
[IX_Archive_Order_DataId] UNIQUE NONCLUSTERED ( [DataId] ) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE
= OFF, IGNORE_DUP_KEY
= OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS
= ON, FILLFACTOR = 90) ON [PRIMARY] GO Or like this: CREATE UNIQUE NONCLUSTERED INDEX
[IX_Archive_Order_DataId] ON [dbo].[Archive_Order] ( [OrderID] ASC ) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE
= OFF, SORT_IN_TEMPDB
= OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING
= OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS
= ON, FILLFACTOR = 90) ON [PRIMARY] GO Get the current value of the sequence: SELECT Current_Value FROM SYS.Sequences WHERE name='DataId' When I do this the sequence count up and show the new value: SELECT (NEXT VALUE FOR dbo.DataId) In case of a restart of sequence: ALTER SEQUENCE dbo.DataId RESTART WITH 1 In case of delete the sequence
default value, refer to the constraint name given before: ALTER TABLE [dbo].[Archive_Order] DROP CONSTRAINT
[DF_Archive_Order_DataId] GO In case of delete the sequence
column: ALTER TABLE [dbo].[Archive_Order] DROP COLUMN DataId GO In case of delete the sequence: DROP SEQUENCE [dbo].[DataId] In case of rename a column from name
DataId to name DWH_RECORD_ID: EXEC sp_rename 'Archive_Order.DataId', 'DWH_RECORD_ID', 'COLUMN' 12.
Computed column In a select statement and saved as a view it is easy
to make a computed column like a calculation or a concatenation of string
columns like this: SELECT [EmployeeID] ,[LastName] ,[FirstName] ,[Title] ,CONCAT(FirstName, ' ', LastName, ' - ', Title) AS NameTitle FROM [Northwind].[dbo].[Employees] In a design of a table I can add a Computed Column
Specification called NameTitle:
Or as a sql script: CREATE TABLE [dbo].[Employees]( [EmployeeID] [int] IDENTITY(1,1) NOT NULL, [NameTitle] AS (concat([FirstName],' ',[LastName],' - ',[Title])), [LastName] [nvarchar](20) NOT NULL, [FirstName] [nvarchar](10) NOT NULL, [Title] [nvarchar](30) NULL, CONSTRAINT [PK_Employees] PRIMARY
KEY CLUSTERED
( [EmployeeID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE
= OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS
= ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY] GO I can use the computed column
NameTitle like any other columns, but I can’t edit it, but then I edit the
other columns, the computed column is updated automatically. Another example of computed columns: CREATE TABLE [dbo].[Campaign]( [CampaignId] [int] IDENTITY(1,1) NOT NULL, [Campaign] [nvarchar](100) NOT NULL, [CampaignFromDate] [datetime2](7) NOT NULL, [CampaignToDate] [datetime2](7) NOT NULL, [InactiveDays] [int] NOT NULL, [InactiveDaysFromDate] AS (dateadd(day,-[InactiveDays],[CampaignFromDate])), [InactiveDaysToDate] AS (dateadd(nanosecond,(-50),[CampaignFromDate])), [DisplayFromDate] AS (convert([date],format([CampaignFromDate],'yyyyMMdd'))), [DisplayToDate] AS (convert([date],format([CampaignToDate],'yyyyMMdd'))) CONSTRAINT [PK_Campaign] PRIMARY
KEY CLUSTERED
( [CampaignId] ASC ) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE
= OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS
= ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO A row in the table:
A computed column to show
a fixed value in all rows and it can not be edited: [Type] AS ('CustomerType') A computed column to show
a hashbyte value and to be used for a primary key: [HashKey] AS (CONVERT([binary](32),HASHBYTES('SHA2_256', CONCAT_WS(';',CustomerId,
ProductId, OrderDate,
Code, Name))))
PERSISTED NOT
NULL, CONSTRAINT [PK_CustomerOrder] PRIMARY KEY NONCLUSTERED ([HashKey] ASC)WITH (FILLFACTOR = 100) ON [PRIMARY]) ON [PRIMARY] The computed column can
be used in a Merge join without a presort. 13.
Comparison column with a hashbyte value A comparison column is a special
kind of computed column where
multiple columns are added together to give a unique value for each concatenation
so it can be used to compare with same columns in another table. Checksum
function is not accurate and reliable, therefore I am using Hashbytes
function that return a Hex value e.g. 0xE3B0C44298FC1C149AFBF4C8996FB92427AE41E4649B934CA495991B7852B855 SELECT EmployeeID ,LastName ,FirstName ,Comparison
= HASHBYTES('SHA2_256', CONCAT(UPPER(RTRIM(LTRIM(FirstName))),';',UPPER(RTRIM(LTRIM(LastName))))) ,DATALENGTH(HASHBYTES('SHA2_256', CONCAT(FirstName, LastName))) AS [Length] FROM Northwind.dbo.Employees I have added a new
column Comparison with datatype binary(32) because hashbytes always return
the same number of bytes, length, for the same type of hash, and then I can update
the column: UPDATE e SET Comparison = HASHBYTES('SHA2_256', CONCAT(UPPER(RTRIM(LTRIM(FirstName))), ';',UPPER(RTRIM(LTRIM(LastName))))) FROM Northwind.dbo.Employees e The 256 bit length of the hash ensures that the
chance on hash collisions is minimal. 256 bit maps to 64 characters char(64) and
66 characters with 0x to show Hex. UPDATE Northwind.dbo.Employees SET Comparison = CONVERT(Binary(32),'') Concat takes care of null value in column else
isnull(firstname, ''). Concat columns with value Null or empty string '' give
same hashbyte value: select Comparison = HASHBYTES('SHA2_256', CONCAT(null,null)) select Comparison = HASHBYTES('SHA2_256', CONCAT('','')) 0xE3B0C44298FC1C149AFBF4C8996FB92427AE41E4649B934CA495991B7852B855 When concatenating columns that can be null it is
important to have a delimiter because these two give same hashbyte value: select Comparison = HASHBYTES('SHA2_256', CONCAT('ABC',NULL,'DEF','GHI')) select Comparison = HASHBYTES('SHA2_256', CONCAT('ABC','DEF',NULL,'GHI')) 0x2CDF6E152315E807562E3265BEA43B48FE82511242D002FC45A35D190067A3D0 select Comparison = HASHBYTES('SHA2_256', CONCAT(12,3,45)) select Comparison = HASHBYTES('SHA2_256', CONCAT(1,2,345)) 0x5994471ABB01112AFCC18159F6CC74B4F511B99806DA59B3CAF5A9C173CACFC5 Therefore I am using semicolon as delimiter to get
two different hashbyte values: select Comparison = HASHBYTES('SHA2_256', CONCAT('ABC',';',NULL,';','DEF',';','GHI')) select Comparison = HASHBYTES('SHA2_256', CONCAT('ABC',';','DEF',';',NULL,';','GHI')) select Comparison = HASHBYTES('SHA2_256', CONCAT(12,';',3,';',45)) select Comparison = HASHBYTES('SHA2_256', CONCAT(1,';',2,';',345)) SQL Server 2017 got Concat with separator: select Comparison = HASHBYTES('SHA2_256', CONCAT_WS(';', 'ABC',NULL,'DEF','GHI')) select Comparison = HASHBYTES('SHA2_256', CONCAT_WS(';', 'ABC','DEF',NULL,'GHI')) Lower case and upper case has different hashbytes
therefore I used UPPER before: select Comparison = HASHBYTES('SHA2_256', CONCAT('a','b')) select Comparison = HASHBYTES('SHA2_256', CONCAT('A','B')) When the SELECT is placed in a SSIS
Source component, I use convert or cast: Comparison = CAST(HASHBYTES('SHA2_256', CONCAT(…)) AS binary(32)) because then the data type in the SSIS
pipeline will go from DT_BYTES 8000 to the correctly DT_BYTES 32 and that
will use very less memory for the SSIS package. Going to compare in a SSIS package,
I need to convert or cast to a string e.g.: (DT_WSTR,66)New_Comparison !=
(DT_WSTR,66)Old_Comparison SELECT HashBytes('SHA2_256', 'Hello World') SELECT UPPER(master.dbo.fn_varbintohexstr(HashBytes('SHA2_256', 'Hello World'))) SELECT UPPER(SUBSTRING(master.dbo.fn_varbintohexstr(HashBytes('SHA2_256', 'Hello World')), 3, 64)) SELECT UPPER(master.dbo.fn_varbintohexsubstring(0, HashBytes('SHA2_256', 'Hello World'), 1, 0)) SELECT CONVERT(CHAR(64),HashBytes('SHA2_256', 'Hello World'),2) -- best to string. A591A6D40BF420404A011733CFB7B190D62C65BF0BCDA32B57B277D9AD9F146E For SQL Server 2014 and earlier,
allowed input values are limited to 8000 bytes. I have before used this conversion
but it is only for the last 8 bytes: CONVERT(BIGINT, HASHBYTES('MD5', '-')) become 7048536267016676135 for varchar. CONVERT(BIGINT, HASHBYTES('MD5', N'-')) become 664431943632833479 for nvarchar. MD5 is 16 bytes or 32 char and SHA-1
is 20 bytes or 40 char. Computed
column It is common in a data warehouse in
an input data area or a stage table to have a computed column to calculate
and persist a hashbyte value to compare a row from source system with a row
in data warehouse when the rows has same business key, e.g. for an Employee
table with business key EmployeeID that is hashed and three data columns
that is hashed and please notice that a data type like int and date needs to
be converted to a varchar string before a hashbyte is created: CREATE TABLE [dbo].[Stg_Employees]( [EmployeeID] [int] NOT NULL, [LastName] [nvarchar](20) NOT NULL, [FirstName] [nvarchar](10) NOT NULL, [BirthDate] [date] NULL, [Comparison_bkey_metadata] AS (CONVERT([binary](32),HASHBYTES('SHA2_256', CONVERT([varchar](10),[EmployeeID])))) PERSISTED, [Comparison_metadata] AS (CONVERT([binary](32),HASHBYTES('SHA2_256', CONCAT_WS(';',UPPER(TRIM([FirstName])),UPPER(TRIM([LastName])), CONVERT([varchar](23),[BirthDate],(126))))) PERSISTED, CONSTRAINT [PK_Stg_Employees] PRIMARY KEY CLUSTERED ( [EmployeeID] ASC ) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE
= OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] (SQL Server 2017 got Concat with separator and Trim). Update if the comparison of data does
not match for the same comparison key: UPDATE dwh SET IsCurrent = 0 ... FROM dbo.Employees dwh INNER JOIN dbo.Stg_Employees stg ON
stg.Comparison_bkey_metadata = dwh.Comparison_bkey_metadata WHERE stg.Comparison_metadata
!= dwh.Comparison_metadata Using the same column name e.g. ComparisonKey_dwh
and ComparisonData_dwh in all your tables, the ETL programming becomes
simpler and similar. 14.
Timestamp or RowVersion column A timestamp column is a special kind
of column where I can’t
typein, insert or update an explicit value because it is automatically generate a binary
number which is guaranteed to be unique within a database every time a row is
inserted or updated. A Customer table where column UpdatedTS is datatype
timestamp:
When I have updated both rows and inserted
a new row, they got a new TS values:
I don’t need any trigger or programming
to look after when a row is updated, timestamp do the work for me. An Order
By Desc at the TS column will sort data so the last insert/updated row will
be shown first. TS is often used to extract delta data from a table, meaning
rows that has been updated or changed since last time I fetch data from the
table, example WHERE UpdatedTS > 0x00009CEF00A25897. When I need to copy the exact same
timestamp value to another table, I have to change the data type in the
destination table to binary(8) because timestamp is not updatable. Cast a timestamp to a big integer
gives a nice unique value: SELECT
CAST(0x00009CEF00A258AF AS bigint) -- gives 172550321756335 SELECT CAST([UpdatedTS]
AS bigint) Cast a timestamp to a string varchar
by using a sql server function where 0x become lowercase and the rest is uppercase: SELECT LEFT(master.sys.fn_varbintohexstr([UpdatedTS]),2)
+ UPPER(RIGHT(master.sys.fn_varbintohexstr([UpdatedTS]), LEN(master.sys.fn_varbintohexstr([UpdatedTS]))-2))
AS [UpdatedTS_String] Cast a timestamp to a datetime gives
maybe a value but it has nothing to do with
the date and time when the row was updated: SELECT
CAST(0x00009CEF00A258AF AS datetime) --
gives 2009-12-30 09:51:05.117 In SSMS in design of a table I can
choose timestamp in the Date type dropdown box, but from SQL Server 2012 the
timestamp is a synonym for the rowversion data type, but strange I can’t
choose rowversion in the Date type dropdown. In DDL statement it is better to
use rowversion because timestamp syntax is deprecated and will be removed in
a future version of SQL Server, examples: CREATE TABLE Customers (……, UpdatedRV
rowversion) GO ALTER TABLE dbo.Customers ADD UpdatedRV rowversion GO Example I have a table that needs to send
new, changed and deleted data to another system, I made a timestamp column in
the table and a delete trigger for the table together with a new table to
store the deleted rows, and I make a DataType column that have two values E =
Editing (insert/update) and D = Deleted to tell the other system what happen
with the data, so the system can insert rows that do not exists and update
rows that exists and delete rows that system do not need anymore. I am using
approach Incremental load or Delta data detection from the table to the other
system to limit the number of rows in the transportation. ALTER TABLE dbo.Customer ADD DataTimestamp timestamp
NOT NULL GO CREATE TABLE [dbo].[CustomerDeleted]( [DataId] [int] IDENTITY(1,1) NOT NULL, [DataDate] [datetime2](7) NOT NULL, [DataType] [char](1) NOT NULL, [DataLogin] [nvarchar](20) NOT NULL, [DataHost] [nvarchar](20) NOT NULL, [DataTimestamp] [timestamp] NOT NULL, [CustomerId] [int] NULL, [CustomerName] [nvarchar](50) NULL, CONSTRAINT [PK_CustomerDeleted] PRIMARY KEY CLUSTERED ( [DataId] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE
= OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 90) ON [PRIMARY] ) ON [PRIMARY] GO CREATE TRIGGER [dbo].[Customer_Delete] ON [dbo].[Customer] AFTER DELETE AS SET NOCOUNT ON INSERT INTO dbo.CustomerDeleted ( DataType, DataDate, DataLogin, DataHost, CustomerId, CustomerName ) SELECT 'D', SYSDATETIME(), STUFF(SUSER_SNAME(), 1, charindex('\', SUSER_SNAME()), ''), HOST_NAME(), CustomerId, CustomerName FROM [Deleted] GO CREATE PROCEDURE [dbo].[CustomerDataDelta] @DataTimestamp binary(8) – timestamp AS /* DECLARE @ts binary(8) SET @ts = 0x00000000001F57E6 EXEC dbo.CustomerDataDelta @ts */ SET NOCOUNT ON SELECT DataTimestamp, 'E'
AS DataType, CustomerId, CustomerName FROM dbo.Customer WITH(NOLOCK) WHERE DataTimestamp >
@DataTimestamp UNION ALL SELECT DataTimestamp, 'D'
AS DataType, CustomerId, NULL
-- no need to give name of the deleted
customer to the other system. FROM dbo.CustomerDeleted
WITH(NOLOCK) WHERE DataTimestamp >
@DataTimestamp ORDER BY DataTimestamp ASC GO 15.
Data Compression Page or Clustered Columnstore Index SQL Server storage is called RowStore where a data compression
page is a way to limit the hard drive space as a kind of a zip table and to achieve
faster query performance. SQL Server storage is called ColumnStore where an index shrink
data to limit the hard drive space a lot, and to achieve faster query
performance. Data
compression page Right-click at table and select
Storage and Manage Compression starts a wizard and it will set
DATA_COMPRESSION = PAGE to an existing table constraint primary key and index
and to all its partitions (a table is born with one default partition). Add compression to an existing table
e.g.: ALTER TABLE [Bank].[Transaction] REBUILD PARTITION = ALL WITH (DATA_COMPRESSION =
PAGE) Add compression to an existing index
of a exiting table e.g.: ALTER INDEX
[IX_Bank_Transaction_CustomerId] ON [Bank].[Transaction] REBUILD PARTITION = ALL WITH (SORT_IN_TEMPDB = OFF, ONLINE = OFF, DATA_COMPRESSION = PAGE ) When create a new table with primary
key and index to include compression: CREATE TABLE [Bank].[Transaction]( [TransactionId] [int] NOT NULL, …list of columns… CONSTRAINT [PK_Bank_Transaction] PRIMARY KEY CLUSTERED ( [TransactionId] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE
= OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS
= ON, ALLOW_PAGE_LOCKS = ON, DATA_COMPRESSION = PAGE) ON [PRIMARY] ) ON [PRIMARY] GO CREATE NONCLUSTERED INDEX [IX_Bank_Transaction_CustomerId] ON [Bank].[Transaction] ( [CustomerId] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE
= OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING
= OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, DATA_COMPRESSION
= PAGE) ON [PRIMARY] GO When create a new table with no
primary key to include compression: CREATE TABLE [Bank].[Transaction]( [TransactionId] [int] NOT NULL, …list of columns… ) ON [PRIMARY] WITH (DATA_COMPRESSION = PAGE) GO To see a compression by scripting a
table, please do in SQL Server Management Studio at menu item Tools, Options,
SQL Server Object Explorer, Scripting, Script Data Compression Options set to
True. When you change a data type or add a
column to a table in Design dialogbox,
the
compression will be gone, therefore you need to add compression to
the table and its indexes again. Clustered
Columnstore Index A table with many columns with
repeating values in many rows, like a fact table with many dimensions clustered
columnstore index can reduce the harddisk space up to 10x, a kind of »zip« and
get faster query performance because a server cpu kernels do a fast »unzip«: CREATE TABLE [Data].[Mix] ( [Id] [int] NOT NULL, [CustomerName] [varchar] (200) NOT NULL, [CustomerAddress] [varchar] (200) NULL, [ProductName] [varchar] (200) NOT NULL, [ProductDescription] [varchar] (1024) NULL, [PriceInformation] [varchar] (512) NULL, [SalesPersonName] [varchar] (100) NULL, [MarkedName] [varchar] (100) NULL, [NumberOfIssues] [int] NOT NULL, [CurrentDateOfBusiness] [datetime2](3)
NOT NULL, ) ON [PRIMARY] GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_Data_Mix
ON Data.Mix WITH (DROP_EXISTING = OFF, COMPRESSION_DELAY = 0, DATA_COMPRESSION
= COLUMNSTORE) ON
[PRIMARY] GO Use
MAXDOP = 1 max degree of parallelism in SQL Server Standard edition. A
CCI example using ORDER at a dimension
key column for extra performance when the dimension later will join to a fact
with the same dimension key column. Use
MAXDOP = 1 to ensure that parallelism does not affect data order when the
index is built. Microsoft says here: »When
creating an ordered clustered columnstore index, use the MAXDOP = 1 option
for the highest quality sorting, in exchange for a significantly longer
duration of the CREATE INDEX statement. To create the index as fast as
possible, don't limit MAXDOP. The highest quality of compression and sorting
could aid queries on the columnstore index.« Read
more here. [Read
about maxdop here »In
Azure SQL Database, SQL database in Fabric, and Azure SQL Managed Instance,
the default MAXDOP setting for each new single database, elastic pool database,
and managed instance is 8.« What about Azure Hyperscale? Read
more here including Cost Threshold for Parallelism CTFP. Read
more here and here too with links to other pages.] CREATE CLUSTERED COLUMNSTORE INDEX [CCI_mart_Dim_Customer]
ON [mart].[Dim_Customer] ORDER ([Customer_key]) WITH (MAXDOP = 1, DROP_EXISTING = OFF, COMPRESSION_DELAY = 0, DATA_COMPRESSION = COLUMNSTORE) ON [BASE] GO When you change a data type or add a
column to a table in Design dialogbox,
the ORDER will be gone, therefore
you need to drop CCI and create CCI again. DROP INDEX [CCI_mart_Dim_Customer] ON [mart].[Dim_Customer] Support for data type varchar(MAX)
and nvarchar(MAX) and varbinary(MAX) since SQL Server 2017 but not data types:
text, ntext, timestamp, xml, image, rowversion, sql_variant and CLR types (hierarchyid
and spatial types). Support for ordered clustered
columnstore index since SQL Server 2022. Not support a computed column: Unable
to create index 'CCI_...'. The statement failed because column 'Amount' on
table 'Mix' is a computed column. Columnstore index cannot include a computed
column implicitly or explicitly. A clustered columnstore index is
fundamentally different from a clustered rowstore index, because there is no
key column specification for a clustered columnstore index, it is an index
with no keys because all columns are included in the CCI. By design a clustered
columnstore table does not allow a clustered primary key constraint. Else use
a nonclustered columnstore index on a table to enforce a primary key
constraint. Therefore seldome to have a primary key in a columnstore index
table else compress a NONCLUSTERED PK with DATA_COMPRESSION =
PAGE. Seldome to have index in
a columnstore index table because it will use Key Lookup to the clustered
part and that can cost performance. When a columnstore index is built,
SQL Server reads the data and builds the index 1 million rows at a time, this
is called a rowgroup. SQL Server has metadata of the lowest and the highest
value for each column in each such rowgroup. There are no no index seek only index
scan. A sql statement with a Where NumberOfIssues = 23 SQL Server looks at
the metadata to determine the lowest and highest value for the column per
rowgroup. If the column value in a Where clause cannot exist in the rowgroup,
then the rowgroup doesn't have to be read. This is a rowgroup elimination. Extra insert of rows can degrade the
quality of the index, therefore consider if it is feasible to schedule rebuilds of a columnstore index. Same
goes with Update rows and Delete rows. Anyway, never do an Update in a CCI
table. ALTER INDEX CCI_Data_Mix ON Data.Mix REBUILD WITH (ONLINE
= OFF) An overview of your clustered columnstore
index in a partitioned table: CREATE CLUSTERED COLUMNSTORE INDEX
[CCI_base_Orders] ON [base].[Orders] WITH (DROP_EXISTING = OFF, COMPRESSION_DELAY = 0, DATA_COMPRESSION
= COLUMNSTORE) ON [PartitionScheme_Referenceperiod] ([Referenceperiod]) SELECT OBJECT_SCHEMA_NAME(object_id) AS
[SchemaName], OBJECT_NAME(object_id) AS
[TableName], Partition = prv.value, object_id, index_id,
partition_number, row_group_id,
delta_store_hobt_id, state,
state_desc, transition_to_compressed_state_desc,
trim_reason_desc, total_rows,
deleted_rows, size_in_bytes, has_vertipaq_optimization, generation,
created_time FROM sys.dm_db_column_store_row_group_physical_stats sta INNER JOIN sys.partition_range_values prv ON prv.boundary_id
= sta.partition_number WHERE OBJECT_SCHEMA_NAME(object_id) = 'base' AND OBJECT_NAME(object_id) = 'Orders' ORDER BY state_desc,
partition_number, total_rows Some rows has column state_desc
with values COMPRESSED and OPEN, and column total_rows with value 1048576. Finding partitions with
not COMPRESSED and more than 50000 rows: WHERE OBJECT_SCHEMA_NAME(object_id) = 'base' AND OBJECT_NAME(object_id) = 'Orders' AND state_desc != 'COMPRESSED' AND total_rows >= 50000 ORDER BY total_rows DESC,
state_desc, partition_number
OPEN has
delta_store_hobt_id value 72057605727125504. Rebuild one partition
from a partitioned table with a clustered columnstore index: ALTER INDEX CCI_base_Orders ON
base.Orders REBUILD PARTITION = 4 WITH
(ONLINE = OFF) Now the overview shows column state_desc
with only value COMPRESSED, and transition_to_compressed_state_desc with
value INDEX_BUILD. CCI is useful for a materialized
view that are computed and stored physically as a table and only use small
storage size because of the compression of column store. A view is computed each time it is accessed,
therefore a materialized view improves the query time but when the base
tables are updated the materialized view as a table must be recomputed like a
truncate table insert into select from view or do a singlewise insert, update
and delete (or merge) by stored procedure running in the night or by triggers
at base tables. Of couse it can be inefficient when many updates therefore
think about when and how to update the stored materialized view table. Why is it called a columnstore
index, using the word index? I guess it is because you can think of it as an
index in a way of Drop index and Create index and Rebuild index which is
handy for faster performance in a data warehouse ETL process, where you like
to Insert millions of rows Into a staging table and afterwards do some enrichment
of derived columns with Update(s). Here is a pseudo example: 1. Begin a ETL proces by empty table
staging.Orders and drop its CCI: TRUNCATE TABLE staging.Orders DROP INDEX IF EXISTS staging.Orders.CCI_staging_Orders 2. Insert millions of rows into
staging.Orders by stored procedure, SSIS, RStudio. 3. Do Update of columns in
staging.Orders table, maybe several updates. 4. Create a clustered columnstore
index at staging.Orders when all data is ready: IF NOT EXISTS (SELECT 1 FROM sysindexes WHERE name = 'CCI_staging_Orders') BEGIN CREATE
CLUSTERED COLUMNSTORE
INDEX CCI_staging_Orders ON staging.Orders WITH (DROP_EXISTING = OFF, COMPRESSION_DELAY = 0, DATA_COMPRESSION
= COLUMNSTORE) ON
[BASE] END You will be surprised how little
storage staging.Orders will use with applied CCI. An example is 94.868.513 rows with a
storage at 45.407,563 MB then create a CCI that took 5 minutes and 44 seconds
time and gave a storage at only 6.640,867 MB. 5. Move staging.Orders into a
partition of a partitioned table with a clustered columnstore index where you
have found the @PartitionNumber. Make sure the partition is empty, no rows,
rowcount is 0 by doing a truncate of the partition. Method is called:
Non-partitioned table to a partition in a partitioned table. Load data by
switching in, meaning the whole staging table (all its rows) will be switch
in to the relevant partition in base table. The power of partitioning lies in
partition switching. TRUNCATE TABLE base.Orders WITH (PARTITIONS(@PartitionNumber)) ALTER TABLE staging.Orders SWITCH TO
base.Orders PARTITION
@PartitionNumber Notice
that you cannot Disable a CCI, because you will get this message: »The
query processor is unable to produce a plan because the index
'CCI_staging_Orders' on table or view 'Orders' is disabled.« Another
example for a full load to a fact table with a clustered columnstore index: TRUNCATE TABLE [fact].[Sales] DROP INDEX IF EXISTS [fact].[Sales].[CCI_FactSales] INSERT INTO [fact].[Sales](.....) SELECT ..... FROM [staging].[Sales] CREATE CLUSTERED COLUMNSTORE INDEX
[CCI_FactSales] ON [fact].[Sales] ORDER ([PurchaseDate_key]) WITH (MAXDOP = 1, DROP_EXISTING = OFF, COMPRESSION_DELAY = 0, DATA_COMPRESSION
= COLUMNSTORE) ON [PRIMARY] More
readings Nonclustered index versus clustered columnstore index CREATE COLUMNSTORE INDEX
Basics of Clustered Columnstore Index Columnstore indexes - Data loading guidance Ordered clustered columnstore index, sort in tempdb can fill
it up Much more to
read at nikoport Extra in SQL Server 2022
Shrink a database tables with
columnstore index DECLARE @table nvarchar(255) DECLARE @sql
nvarchar(MAX) DECLARE @Scan CURSOR SET @Scan = CURSOR
LOCAL FORWARD_ONLY DYNAMIC FOR SELECT TABLE_NAME FROM
INFORMATION_SCHEMA.TABLES WHERE TABLE_TYPE = 'BASE
TABLE' OPEN @Scan FETCH NEXT FROM
@Scan INTO @table WHILE @@FETCH_STATUS
= 0 BEGIN SET @sql = 'CREATE CLUSTERED COLUMNSTORE
INDEX [CCI_dbo_' + @table + '] ON [dbo].[' + @table + '] WITH (DROP_EXISTING
= OFF, COMPRESSION_DELAY = 0, DATA_COMPRESSION = COLUMNSTORE) ON [PRIMARY]' --PRINT @sql EXECUTE sp_executesql @sql FETCH NEXT FROM @Scan INTO @table END CLOSE @Scan DEALLOCATE @Scan Recovery mode set to Simple. DBCC SHRINKFILE (<databasename>,
1) DBCC SHRINKFILE
(<databasename>_log, 1) 16.
Partitioned Tables with indexes and switching data General information about partitioned tables and indexes Query guide on partitioned tables and indexes Partitioned Tables and Indexes in SQL Server 2005 Create partitioned tables and indexes Partition table with a Columnstore Index The Data Loading Performance Guide The database engine supports up to
15,000 partitions by default. Create a partition function with a data type as parameter for
the column A partitioned table with a clustered
columnstore index behaves like a partitioned heap.
A partition function has a parameter
type (date) to tell the data type for the values. A partition function is wrapped into
a partition scheme to that maps the partitions of a partitioned table. CREATE
PARTITION FUNCTION [PartitionFunction_DateRangeMonth](date) AS
RANGE RIGHT FOR VALUES ('2010-01-01',
'2010-02-01', '2010-03-01', … , '2050-11-01', '2050-12-01') GO
CREATE
PARTITION SCHEME [PartitionScheme_DateRangeMonth] AS
PARTITION [PartitionFunction_DateRangeMonth] ALL TO ([PRIMARY]) GO
Please
notice, that SQL implement it as when you script the object: CREATE
PARTITION SCHEME [PartitionScheme_DateRangeMonth] AS
PARTITION [PartitionFunction_DateRangeMonth] TO ([PRIMARY], [PRIMARY],
[PRIMARY], [PRIMARY], [PRIMARY], … ) GO It
is common to create a partition function and partition scheme through a
stored procedure, because with many partitions it is to hard to write them
manually. Create
a fact table with a Partition scheme and use of data compression page: CREATE
TABLE Fact_Order ( OrderKey bigint IDENTITY(1,1) NOT NULL, OrderDate date NOT NULL, -- partitioning column or partition key. CustomerKey int NOT NULL, ProductKey int NOT NULL, StoreKey int NOT NULL, OrderQuantity int NOT NULL, CONSTRAINT
[PK_fact_Order] PRIMARY KEY CLUSTERED ( [OrderKey]
ASC, [OrderDate]
ASC -- partitioning column or
partition key must be included. )WITH
(PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON,
ALLOW_PAGE_LOCKS = ON, DATA_COMPRESSION =
PAGE) ON [PartitionScheme_DateRangeMonth]([OrderDate]) )
ON [PartitionScheme_DateRangeMonth]([OrderDate]) GO
Ensure
unique composite dimension keys and faster search on few orderdates: CREATE
UNIQUE NONCLUSTERED INDEX [UIX_fact_Order] ON [fact].[Order] ( [OrderDate] ASC, -- partitioning column or partition key. [CustomerKey] ASC, [ProductKey] ASC )WITH
(PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF,
DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON,
ALLOW_PAGE_LOCKS = ON, DATA_COMPRESSION = PAGE) ON [PartitionScheme_DateRangeMonth]([OrderDate]) GO Ensure
faster sum up for each store within a partition of a month: CREATE
NONCLUSTERED INDEX [IX_fact_Order_OrderQuantity] ON [fact].[Order] ( [OrderDate] ASC, -- partitioning column or partition key. [StoreKey] ASC, [OrderQuantity] ASC )WITH
(PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF,
ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS =
ON, DATA_COMPRESSION = PAGE) ON [PartitionScheme_DateRangeMonth]([OrderDate]) GO Search
in a partition by fetch a partion with a partition function: SELECT
CustomerKey, ProductKey, StoreKey, OrderQuantity FROM
Fact_Order WHERE
$PARTITION.PartitionFunction_Date(OrderDate) = (SELECT
$PARTITION.PartitionFunction_Date('2020-06-05')) Or
just: SELECT
CustomerKey, ProductKey, StoreKey, OrderQuantity FROM
Fact_Order WHERE
OrderDate = '2020-06-05' SELECT
CustomerKey, ProductKey, StoreKey, OrderQuantity FROM
Fact_Order WHERE
OrderDate = '2020-06-05' AND OrderQuantity BETWEEN 10 AND 14 A
great overview of the table partitions: SELECT
OBJECT_SCHEMA_NAME(pstats.object_id) AS SchemaName, OBJECT_NAME(pstats.object_id) AS
TableName, ps.name AS PartitionSchemeName, ds.name AS PartitionFilegroupName, pf.name AS PartitionFunctionName, CASE pf.boundary_value_on_right WHEN 0 THEN 'Range Left' ELSE 'Range Right' END AS PartitionFunctionRange, CASE pf.boundary_value_on_right WHEN 0 THEN 'Upper Boundary' ELSE 'Lower Boundary' END AS PartitionBoundary, prv.value AS PartitionBoundaryValue, c.name AS PartitionKey, CASE WHEN pf.boundary_value_on_right =
0 THEN c.name + ' > ' + CAST(ISNULL(LAG(prv.value) OVER(PARTITION BY
pstats.object_id ORDER
BY pstats.object_id, pstats.partition_number), 'Infinity') AS VARCHAR(100)) +
' and ' + c.name + ' <= ' + CAST(ISNULL(prv.value, 'Infinity') AS
VARCHAR(100)) ELSE c.name + ' >= ' +
CAST(ISNULL(prv.value, 'Infinity') AS VARCHAR(100)) + ' and ' + c.name + '
< ' + CAST(ISNULL(LEAD(prv.value) OVER(PARTITION BY pstats.object_id
ORDER BY pstats.object_id, pstats.partition_number), 'Infinity') AS
VARCHAR(100)) END AS PartitionRange, pstats.partition_number AS
PartitionNumber, pstats.row_count AS PartitionRowCount, p.data_compression_desc AS
DataCompression FROM
sys.dm_db_partition_stats AS pstats INNER JOIN sys.partitions AS p
ON pstats.partition_id = p.partition_id INNER JOIN
sys.destination_data_spaces AS dds ON
pstats.partition_number=dds.destination_id INNER JOIN sys.data_spaces AS
ds ON dds.data_space_id = ds.data_space_id INNER JOIN
sys.partition_schemes AS ps ON dds.partition_scheme_id = ps.data_space_id INNER JOIN
sys.partition_functions AS pf ON ps.function_id = pf.function_id INNER JOIN sys.indexes AS i ON
pstats.object_id = i.object_id AND pstats.index_id =
i.index_id AND dds.partition_scheme_id =
i.data_space_id AND i.type <= 1 /* Heap or
Clustered Index */ INNER JOIN sys.index_columns
AS ic ON i.index_id = ic.index_id AND i.object_id = ic.object_id AND ic.partition_ordinal >
0 INNER JOIN sys.columns AS c ON
pstats.object_id = c.object_id AND ic.column_id = c.column_id LEFT JOIN
sys.partition_range_values AS prv ON pf.function_id = prv.function_id AND pstats.partition_number =
(CASE pf.boundary_value_on_right WHEN 0 THEN prv.boundary_id ELSE (prv.boundary_id+1) END) ORDER
BY TableName, PartitionNumber; SELECT
TableName = o.name, partition_id, partition_number, Rows FROM
sys.partitions p INNER
JOIN sys.objects o ON o.object_id = p.object_id WHERE
o.name = 'Fact_Order' ORDER
BY partition_number SELECT DISTINCT
SCHEMA_Name(t.schema_id), t.name, p.* FROM sys.partitions
p INNER JOIN sys.tables t ON
t.object_id = p.object_id WHERE
p.partition_number <> 1 AND p.index_id = 1 ORDER BY 1,2,6 Every table in SQL Server contains
at least one partition (the default partition) even if the table is not
explicitly partitioned. In a data warehouse it is common to fetch data into a
staging fact table and later in the ETL process load the whole table into a real
fact table. Using full load with a staging fact table and a fact table having same
structure, we can use a switch commando, where we very fast move all data
from a staging fact table into an empty fact table by the default partition. Therefore we must
first empty or truncate the fact table so it has zero rows and then do a
switch to by alter the staging table: TRUNCATE
TABLE <FactTableName> ALTER
TABLE <StagingFactTableName> SWITCH TO <FactTableName> The staging fact table is empty
after the switch to fact table. Partition switching moves entire
partitions between tables almost instantly. It is extremely fast because it
is a metadata-only operation that updates the location of the data, no data
is physically moved. Using delta load with a staging fact table and a fact table having same
structure, we can use a switch commando, where we very fast move all data
from a staging fact table into an empty partition
of a fact table. Method is called: Non-partitioned table to a partition in a
partitioned table. Load data by switching in, meaning the whole staging table
(all its rows) will be switch in to the relevant partition in fact table. Example
of switch to a partition in to a fact table where Date is the partitioning
column or partition key with a
partition per date: DECLARE
@Date = '2016-02-07' DECLARE
@PartitionNumber int = 0 DECLARE
@PartitionRowCount bigint = 0 DECLARE
@sql nvarchar(512) DECLARE
@params nvarchar(max) DECLARE
@ErrorMessage varchar(1024) SET
NOCOUNT ON BEGIN
TRY -- Get partition number for date because we
switch by partition number and not by a date. SET @sql = N'SELECT @prm_PartitionNumber =
$PARTITION.PartitionFunction_Date(''<Date>'')' SET @sql = REPLACE(@sql, '<Date>',
@Date) SET @params = N'@prm_PartitionNumber int
OUTPUT' EXEC sys.sp_executesql @sql, @params,
@prm_PartitionNumber = @PartitionNumber OUTPUT -- Get the partition rowcount for the
@PartitionNumber to found out if partition is empty or not. SET @sql = N'SELECT @prm_PartitionRowCount
= COUNT_BIG(*) FROM fact.Order WHERE $PARTITION.PartitionFunction_Date([Date])
= @prm_PartitionNumber' SET @params = N'@prm_PartitionNumber int,
@prm_PartitionRowCount bigint OUTPUT' EXEC sys.sp_executesql @sql, @params,
@prm_PartitionNumber = @PartitionNumber, @prm_PartitionRowCount =
@PartitionRowCount OUTPUT IF @PartitionRowCount = 0 -- partition must be empty else all its
data will be gone after the switch. BEGIN -- Since a partition is for one date
only, we must add a constraint to the staging table to check and to -- ensure it only contains data rows with
one date. ALTER TABLE staging.Order DROP CONSTRAINT
IF EXISTS CS_staging_Order_Date -- We need a dynamic sql statement,
because we will use the variable @Date in the statement for the -- constraint on this one date only: SET @sql = N'ALTER TABLE staging.Order
WITH CHECK ADD CONSTRAINT
CS_staging_Order_Date CHECK ([Date] IS NOT
NULL AND [Date] = ''<Date>'')' SET @sql = REPLACE(@sql, '<Date>',
@Date) EXEC sys.sp_executesql @sql ALTER TABLE staging.Order SWITCH TO fact.Order
PARTITION @PartitionNumber ALTER TABLE staging.Order DROP CONSTRAINT
IF EXISTS CS_staging_Order_Date END END
TRY BEGIN
CATCH SELECT LEFT(CONCAT(@ErrorMessage,
ERROR_MESSAGE(), ' '), 1024) EXEC audit.Log_Update_Error @Log_Id,
@ErrorMessage ;THROW END
CATCH In case staging.Order table is a Partitioned
Table we can avoid the CONSTRAINT CS_staging_Order_Date and do a switch from
one partition to another: ALTER TABLE
staging.Order SWITCH PARTITION @PartitionNumber TO fact.Order PARTITION
@PartitionNumber Metadata about the partitions in a
schema/table: SELECT * FROM
sys.dm_db_column_store_row_group_physical_stats WHERE
OBJECT_SCHEMA_NAME(object_id) = 'base' AND OBJECT_NAME(object_id) = 'Orders' ORDER BY
partition_number, row_group_id, state Looking for a partitionnumber: SELECT * FROM
sys.partition_range_values Where boundary_id is the same as
partition_number with the value of the partitioning column or partition key. How to Partition an existing SQL Server Table Dacpac
solution In Visual Studio in a database
project add a folder Storage. Make a file sql script PartitionFunctionDateRangeMonth.sql
to contain: CREATE
PARTITION FUNCTION [PartitionFunction_DateRangeMonth](date) AS
RANGE RIGHT FOR VALUES ('2010-01-01',
'2010-02-01', '2010-03-01', … , '2050-11-01', '2050-12-01') GO
Make another sql script file PartitionSchemeDateRangeMonth.sql to
contain: CREATE
PARTITION SCHEME [PartitionScheme_DateRangeMonth] AS
PARTITION [PartitionFunction_DateRangeMonth] ALL TO ([PRIMARY]) GO
The table schema structure in a file
Fact_Order.sql to contain: CREATE
TABLE Fact_Order ( … )
ON [PartitionScheme_DateRangeMonth]([OrderDate]) Remember to right–click at both
files and select Properties and set BuildAction
to Build, because it can have default
None and that is not working for a Build later. Build the database project with
successful, because the partition thing is included. Deployment of the database project
in a release pipeline needs extra things: https://learn.microsoft.com/en-us/sql/tools/sqlpackage/sqlpackage-publish?view=sql-server-ver17 "$($Settings.Config.DeployTools.SqlPackagePath)"
/Action:Publish /SourceFile:"$($EnvSettings.Database.ProjectName).dacpac" /p:ExcludeObjectTypes="PartitionSchemes;PartitionFunctions" (/p:IgnorePartitionSchemes=false
/p:IgnorePartitionFunctions=false) In Visual Studio in a database
project add a folder PreDeploy. Make a file sql script PreDeployment.sql (or Script.PreDeployment.sql),
because the above parameter has excluded partition schemes and partition
functions from the dacpac, and therefore we need to add them in a pre
deployment script to run only at the first time they are deployed. The file
will contain: IF
NOT EXISTS (SELECT 1 FROM sys.partition_functions WHERE name = 'PartitionFunction_DateRangeMonth') BEGIN CREATE PARTITION FUNCTION
[PartitionFunction_DateRangeMonth](date) AS RANGE RIGHT FOR VALUES ('2010-01-01', '2010-02-01', '2010-03-01',
… , '2050-11-01', '2050-12-01') END GO IF
NOT EXISTS (SELECT 1 FROM sys.partition_schemes WHERE name = 'PartitionScheme_DateRangeMonth') BEGIN CREATE PARTITION SCHEME [PartitionScheme_DateRangeMonth]
AS PARTITION
[PartitionFunction_DateRangeMonth] ALL TO ([PRIMARY]) END GO Remember to right-click at the file PreDeployment.sql
and select Properties and set BuildAction
to PreDeploy. Build the database project with
successful. Maybe
you already have a folder PostDeploy with a file PostDeployment.sql (or Script.PostDeployment.sql)
with BuildAction to PostDeploy. Deploy
with SQLPackage or Azure DevOps together with parameter: /p:DropObjectsNotInSource=False Has an unresolved reference to
object means that a .sql file has BuildAction None and must be changed to
Build, or a .sql file reference is missing in database project file .sqlproj. 17.
Flush SQL Server data memory to test query performance Flush sql server data memory before
run a query to compare performance time: CHECKPOINT GO DBCC FREEPROCCACHE GO DBCC FREESESSIONCACHE GO DBCC FREESYSTEMCACHE ('ALL') GO DBCC DROPCLEANBUFFERS GO WAITFOR DELAY '00:00:05' 18.
FILEGROUP Three examples: CREATE DATABASE [SMALL] CONTAINMENT = NONE ON PRIMARY ( NAME = N'SMALL_dat', FILENAME = N'D:\SMALL_dat.mdf' ,
SIZE = 102400KB ,
MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB
) LOG
ON ( NAME = N'SMALL_log', FILENAME = N'E:\SMALL_log.ldf' ,
SIZE = 51200KB ,
MAXSIZE = 2048GB , FILEGROWTH
= 10% ) GO CREATE TABLE [SMALL].[dbo].[Table]( [Id] [int] IDENTITY(1,1) NOT NULL, [Name] [nvarchar](20) NOT NULL, CONSTRAINT
[PK_Table] PRIMARY KEY
NONCLUSTERED ( [Id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE
= OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 90) ON [PRIMARY] ) ON [PRIMARY] GO CREATE DATABASE [LARGE] CONTAINMENT = NONE ON PRIMARY -- for only system
objects ( NAME = N'LARGE', FILENAME = N'D:\Data\LARGE.mdf' ,
SIZE = 3072KB ,
MAXSIZE = UNLIMITED, FILEGROWTH =
1024KB ), FILEGROUP
[DATA] ( NAME = N'LARGE_dat1', FILENAME = N'D:\Data\LARGE_dat1.ndf' ,
SIZE = 102400000KB , MAXSIZE = UNLIMITED,
FILEGROWTH = 10240000KB ), ( NAME = N'LARGE_dat2', FILENAME = N'D:\Data\LARGE_dat2.ndf' ,
SIZE = 102400000KB ,
MAXSIZE = UNLIMITED, FILEGROWTH =
10240000KB ), FILEGROUP
[INDEX] ( NAME = N'LARGE_index', FILENAME = N'F:\Data\LARGE_index.ndf' ,
SIZE = 5120000KB ,
MAXSIZE = UNLIMITED, FILEGROWTH = 512000KB
) LOG
ON ( NAME = N'LARGE_Log1', FILENAME = N'E:\Logs\LARGE_log1.ldf' ,
SIZE = 8192000KB ,
MAXSIZE = 2048GB,
FILEGROWTH = 1024000KB ), ( NAME = N'LARGE_Log2', FILENAME = N'E:\Logs\LARGE_log2.ldf' ,
SIZE = 8192000KB , MAXSIZE =
2048GB, FILEGROWTH =
1024000KB ) GO CREATE TABLE [LARGE].[dbo].[Table]( [Id] [int] IDENTITY(1,1) NOT NULL, [Name] [nvarchar](20) NOT NULL, CONSTRAINT
[PK_Table] PRIMARY KEY
NONCLUSTERED ( [Id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE
= OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 90) ON [INDEX] ) ON [DATA] GO CREATE UNIQUE NONCLUSTERED INDEX
[IX_Table_Name] ON [LARGE].[dbo].[Table] ( [Name] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE
= OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS =
ON, FILLFACTOR = 90) ON [INDEX] GO USE [master] GO CREATE DATABASE
[BD_Bank_Transaction] CONTAINMENT = NONE ON PRIMARY ( NAME = N'Transaction_Primary',
FILENAME = N'D:\MSSQL\Data\BD_Bank_Transaction_Primary.mdf' , SIZE = 1024KB , MAXSIZE = UNLIMITED,
FILEGROWTH = 65536KB ),
FILEGROUP
[AUDIT] ( NAME = N'Transaction_Audit', FILENAME = N'D:\MSSQL\Data\BD_Bank_Transaction_Audit.ndf' , SIZE = 1024KB , MAXSIZE = UNLIMITED, FILEGROWTH =
65536KB ), FILEGROUP
[BASE] ( NAME = N'Transaction_Base01', FILENAME = N'D:\MSSQL\Data\BD_Bank_Transaction_Base01.ndf' , SIZE = 1024KB , MAXSIZE = UNLIMITED, FILEGROWTH =
10485760KB ), ( NAME = N'Transaction_Base02', FILENAME = N'D:\MSSQL\Data\BD_Bank_Transaction_Base02.ndf' , SIZE = 1024KB , MAXSIZE = UNLIMITED, FILEGROWTH =
10485760KB ), ( NAME = N'Transaction_Base03', FILENAME = N'D:\MSSQL\Data\BD_Bank_Transaction_Base03.ndf' , SIZE = 1024KB , MAXSIZE = UNLIMITED, FILEGROWTH =
10485760KB ), ( NAME = N'Transaction_Base04', FILENAME = N'D:\MSSQL\Data\BD_Bank_Transaction_Base04.ndf' , SIZE = 1024KB , MAXSIZE = UNLIMITED, FILEGROWTH =
10485760KB ), ( NAME = N'Transaction_Base05', FILENAME = N'D:\MSSQL\Data\BD_Bank_Transaction_Base05.ndf' , SIZE = 1024KB , MAXSIZE = UNLIMITED, FILEGROWTH =
10485760KB ), ( NAME = N'Transaction_Base06', FILENAME = N'D:\MSSQL\Data\BD_Bank_Transaction_Base06.ndf' , SIZE = 1024KB , MAXSIZE = UNLIMITED, FILEGROWTH =
10485760KB ), ( NAME = N'Transaction_Base07', FILENAME = N'D:\MSSQL\Data\BD_Bank_Transaction_Base07.ndf' , SIZE = 1024KB , MAXSIZE = UNLIMITED, FILEGROWTH =
10485760KB ), ( NAME = N'Transaction_Base08', FILENAME = N'D:\MSSQL\Data\BD_Bank_Transaction_Base08.ndf' , SIZE = 1024KB , MAXSIZE = UNLIMITED, FILEGROWTH =
10485760KB ), FILEGROUP
[INPUT] ( NAME = N'Transaction_Input', FILENAME = N'D:\MSSQL\Data\BD_Bank_Transaction_Input.ndf' , SIZE = 1024KB , MAXSIZE = UNLIMITED, FILEGROWTH =
10485760KB ), FILEGROUP
[WRONG] ( NAME = N'Transaction_Wrong', FILENAME = N'D:\MSSQL\Data\BD_Bank_Transaction_Wrong.ndf' , SIZE = 1024KB , MAXSIZE = UNLIMITED, FILEGROWTH =
65536KB ) LOG
ON ( NAME = N'Transaction_Log', FILENAME
= N'D:\MSSQL\Logs\BD_Bank_Transaction_Log.ldf' , SIZE = 1024KB , MAXSIZE = 1048576000KB ,
FILEGROWTH = 10485760KB ) COLLATE
Danish_Norwegian_CI_AS GO ALTER DATABASE
[BD_Bank_Transaction] SET RECOVERY SIMPLE GO USE [BD_Bank_Transaction] GO EXEC sp_changedbowner 'LAN\SA_Transaction' GO USE [BD_Bank_Transaction] GO CREATE SCHEMA [audit] GO CREATE SCHEMA [base] GO CREATE SCHEMA [map] GO CREATE SCHEMA [input] GO CREATE SCHEMA [staging] GO CREATE SCHEMA [wrong] GO CREATE SCHEMA [mart] GO USE [master] GO ALTER DATABASE
[BD_Bank_Transaction] SET ONLINE GO ALTER DATABASE
[BD_Bank_Transaction] SET MULTI_USER GO 19.
Backup and Restore and Shrink by commands USE
[master] BACKUP
DATABASE [Northwind] TO
DISK = N'Z:\Backup\Northwind.bak' WITH NOFORMAT, INIT,
NAME = N'Northwind-Full Database Backup', SKIP, NOREWIND, NOUNLOAD, STATS =
10 GO
RESTORE
DATABASE [Northwind2014] FROM
DISK = N'Z:\Backup\Northwind.bak' WITH FILE = 1, MOVE
N'Northwind_dat' TO N'E:\DATA\Northwind2014_dat.mdf', MOVE
N'Northwind_log' TO N'F:\LOG\Northwind2014_log.ldf', NOUNLOAD, STATS = 10 GO
USE
[Northwind2014] GO
EXEC
sp_changedbowner 'sa' Refresh SQL Server Management
Studio, Databases. Assuming that the database has
Recovery model Simple which will truncate the log at certain events, that
means you shouldn’t be doing backup log with truncate_only all the time.
Recovery model Full will continue to grow until you take a transaction log
backup. It is not good to be in a repeated
cycle of shrink-grow-shrink-grow or even do frequent shrink databases on a
production system. After a big deletion of rows or
truncate table or drop table, the database files keep same size with unused
space or free space, and that is not a problem as other growth in the database
as insert of rows will just end up using that free space. Sometimes it can be
a good idea to shrink the files, which is done for each Logical Name shown by
right click database and select Properties and click Files. Example via a stored procedure in a Northwind
database with filegroups and files: CREATE
PROCEDURE [dbo].[Shrink] AS BEGIN BEGIN TRY USE [Northwind] GO DBCC SHRINKFILE (Northwind_Primary, 1) -- 1 kb shrink will be to the possible
minimum filesize. GO DBCC SHRINKFILE (Northwind_Base1, 1) GO DBCC SHRINKFILE (Northwind_Base2, 1) GO DBCC SHRINKFILE (Northwind_Log, 1) GO DBCC SHRINKDATABASE (Northwind, 0) -- shrink all data and log files as done
above. GO DBCC UPDATEUSAGE (Northwind) GO END TRY BEGIN CATCH SELECT ERROR_NUMBER() AS ErrorNumber END CATCH END Shrink files can create a fragmenting
indexes, therefore follow up with a index maintenance operations like rebuild
indexes. Shrink generates a lot of I/O and
uses a lot of CPU and generates loads of transaction log in log file. Shrink
is not be part of regular maintenance, and you should never have auto shrink
enabled as an option to a database under properties. Make tempdb
initial size smaller, do this in SSMS 1.
Right
click database server and {Restart}. 2.
Right
click tempdb and {Task} {Shrink} {Files}. 3.
Select
in File type dropdown Data (and again later Log). 4.
Select
'Reorganize pages before releasing unused space' and shrink file to 500 MB. 5.
Repeat
this for each file type in dropdown and for each file name in dropdown. 6.
Check
the new initial size by right click tempdb and {Properties} click Files. USE [tempdb] GO DBCC SHRINKFILE (temp, 1) GO DBCC SHRINKFILE (temp2, 1) GO DBCC SHRINKFILE (temp3, 1) GO DBCC SHRINKFILE (temp4, 1) GO DBCC SHRINKFILE (templog, 1) GO SA as owner If you can not see the properties
for a database and get message: Property owner is not available for database,
it is because the owner of the database is dropped from the Security Logins
and you can check it by this command: EXEC sp_helpdb
'<databasename>' -- shows at Owner ~~UNKNOWN~~ To give the database another owner
like sa do this: USE <databasename> EXEC sp_changedbowner 'sa' GO dbo as
owner of a schema so other users can access tables in dbo schema USE <databasename> ALTER AUTHORIZATION ON SCHEMA::[<schema
name>] TO [dbo] Opdater Compatibility
level USE <databasename> ALTER DATABASE [<databasename>] SET COMPATIBILITY_LEVEL = 160 GO Opdater
indeks statistik USE <databasename> UPDATE STATISTICS [dbo].[Customer] GO 20.
Temporal table system-versioned table I
have chosen to start with a Kimball dimension tabel in order to elaborate on
it later. Creating
a temporal table system-versioned table will create two identical tables:
Dimension table dbo.dim_Department
has:
A unique index on the business key
column is to ensure, that a business key value can only stand in one row in
the table dbo.dim_Department as current values. The same business key value
can stand in several rows in the table dbo.dim_Department_History as historical
values. Temporal table system-versioned
table assigns the value for the ValidFrom column to begin time of the current
transaction in UTC time based on the system clock, and assigns the value for
the ValidTo column to the maximum value of 9999-12-31. This marks a row as
open or as current and not deleted. I have chosen to include UTC in the table
structure to avoid misunderstanding of the timezone of the timestamp for a temporal
table system-versioned table: CREATE TABLE [dbo].[dim_Department]( [Department_key] int IDENTITY(1,1) NOT NULL, [Department_bkey] varchar(10) NOT NULL, [DepartmentName]
varchar(50) NOT NULL, [ValidFrom_UTC_metadata] datetime2(3) GENERATED ALWAYS AS ROW START NOT NULL CONSTRAINT
DF_dim_Department_ValidFrom_UTC_metadata DEFAULT SYSUTCDATETIME(), [ValidTo_UTC_metadata] datetime2(3) GENERATED ALWAYS AS ROW END NOT NULL CONSTRAINT
DF_dim_Department_ValidTo_UTC_metadata DEFAULT CONVERT(datetime2(3), '9999-12-31 23:59:59.999'), CONSTRAINT [PK_dim_Department] PRIMARY KEY CLUSTERED ([Department_key] ASC) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY], PERIOD FOR SYSTEM_TIME ([ValidFrom_UTC_metadata], [ValidTo_UTC_metadata]) ) ON [PRIMARY] WITH(SYSTEM_VERSIONING = ON (HISTORY_TABLE = [dbo].[dim_Department_History])) GO A unique index on business key
column Department_bkey is to ensure the same value is not inserted several
times in the table dbo.dim_Department because it contains the current values: CREATE UNIQUE NONCLUSTERED INDEX [UIX_dim_Department_Department_bkey] ON [dbo].[dim_Department] ([Department_bkey] ASC) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 90) ON [PRIMARY] GO Table dbo.dim_Department_History
becomes automatically Data Compression Page and is created without a primary
key and the unique index from above. Instead there has been automatically
created a clustered index on the valid period columns: CREATE CLUSTERED INDEX [ix_dim_Department_History] ON [dbo].[dim_Department_History] ( [ValidTo_UTC_metadata]
ASC, [ValidFrom_UTC_metadata]
ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF, DATA_COMPRESSION = PAGE) ON [PRIMARY] GO Let’s
insert two rows: INSERT INTO [dbo].[dim_Department]([Department_bkey],[DepartmentName]) VALUES('12S','Sales') GO INSERT INTO [dbo].[dim_Department]([Department_bkey],[DepartmentName]) VALUES('12F','Finance') GO Let’s
select all rows at current time: SELECT * FROM [dbo].[dim_Department] ORDER BY Department_bkey
Let’s
select all rows at point in time, with no rows at 08:23:00 UTC: SELECT * FROM [dbo].[dim_Department] FOR SYSTEM_TIME AS OF '2024-04-21 08:23:00.000' AS pointintime ORDER BY Department_bkey Let’s
select all rows at point in time, with two rows at 08:24:00 UTC: SELECT * FROM [dbo].[dim_Department] FOR SYSTEM_TIME AS OF '2024-04-21 08:24:00.000' AS pointintime ORDER BY Department_bkey Let’s
select all rows valid at any point in time in a closed interval: SELECT * FROM [dbo].[dim_Department] FOR SYSTEM_TIME BETWEEN '2024-04-21 08:23:00' AND '2024-04-21 08:24:00' AS period ORDER BY Department_bkey, ValidFrom_UTC_metadata Let’s
select all rows whose entire validity period falls between the two timestamps: SELECT * FROM [dbo].[dim_Department] FOR SYSTEM_TIME CONTAINED IN ('2024-04-21 08:23:00', '2024-04-21 08:24:00') AS period ORDER BY Department_bkey, ValidFrom_UTC_metadata Let’s
select all rows valid at any point in the half-open interval where the end
boundary is exclusive: SELECT * FROM [dbo].[dim_Department] FOR SYSTEM_TIME FROM '2024-04-21 08:23:00' TO '2024-04-21 08:24:00' AS period ORDER BY Department_bkey, ValidFrom_UTC_metadata Let’s
update a row via a business key value and select all rows at current time: UPDATE [dbo].[dim_Department] SET [DepartmentName] = 'SalesEurope' WHERE [Department_bkey] = '12S' SELECT * FROM [dbo].[dim_Department] ORDER BY Department_bkey
At
point in time 08:24:00 there are two rows as above and one with Sales. At
point in time 08:27:00 there are two rows as above and one with SalesEurope. Let’s
select all rows at history time, limited by infinity interval: SELECT * FROM [dbo].[dim_Department] FOR SYSTEM_TIME BETWEEN '2000-01-01' AND '9999-12-31' AS historytime ORDER BY Department_bkey, ValidFrom_UTC_metadata Let’s select all rows for the entire
history of data changes that returns a union of rows that belong to the
current table and the history table as a history full time line: SELECT * FROM [dbo].[dim_Department] FOR SYSTEM_TIME ALL AS historytime ORDER BY Department_bkey, ValidFrom_UTC_metadata
Notice
from Kimball book page 508 that ValidTo is set to exactly the ValidFrom of
the next row so that no gap exists between rows and no overlap too with continuous
time. Let’s
update a row and select all rows at current time: UPDATE [dbo].[dim_Department] SET [DepartmentName] = 'SalesUS' WHERE [Department_bkey] = '12S' SELECT * FROM [dbo].[dim_Department] ORDER BY Department_bkey
Let’s
select all rows at history full time line: SELECT * FROM [dbo].[dim_Department] FOR SYSTEM_TIME ALL AS historytime ORDER BY Department_bkey, ValidFrom_UTC_metadata
At
point in time 08:24:00 there are two rows as above and one with Sales. At
point in time 08:27:00 there are two rows as above and one with SalesEurope. At
point in time 08:40:00 there are two rows as above and one with SalesUS. Let’s
delete the row for finance and select all rows at current time where Finance
is not included: DELETE FROM [dbo].[dim_Department] WHERE [Department_bkey] = '12F' SELECT * FROM [dbo].[dim_Department] ORDER BY Department_bkey
Let’s
select all rows at history full time line where Finance is included: SELECT * FROM [dbo].[dim_Department] FOR SYSTEM_TIME ALL AS historytime ORDER BY Department_bkey, ValidFrom_UTC_metadata
Finance
got a ValidTo timestamp and no more 9999-12-31 23:59:59.999 meaning Finance
has been deleted and is not included in select all rows at current time. Let’s
update the same row several times and select all rows at current time: UPDATE [dbo].[dim_Department] SET [DepartmentName] = 'SalesTW' WHERE [Department_bkey] = '12S' GO UPDATE [dbo].[dim_Department] SET [DepartmentName] = 'SalesJP' WHERE [Department_bkey] = '12S' GO UPDATE [dbo].[dim_Department] SET [DepartmentName] = 'SalesDK' WHERE [Department_bkey] = '12S' GO SELECT * FROM [dbo].[dim_Department] ORDER BY Department_bkey
Let’s
select all rows at history full time line: SELECT * FROM [dbo].[dim_Department] FOR SYSTEM_TIME ALL AS historytime ORDER BY Department_bkey, ValidFrom_UTC_metadata
Let’s
try to search for SalesJP at current time and it is not found and not shown: SELECT * FROM [dbo].[dim_Department] WHERE DepartmentName = 'SalesJP' Let’s try to search for SalesJP at
history full time line and it is found and shown: SELECT * FROM [dbo].[dim_Department] FOR SYSTEM_TIME ALL WHERE DepartmentName = 'SalesJP' ORDER BY Department_bkey, ValidFrom_UTC_metadata Let’s
select all rows at point in time UTC, shows SalesEurope and SalesDK: SELECT * FROM [dbo].[dim_Department] FOR SYSTEM_TIME AS OF '2024-04-21 08:26:14.679' AS pointintime ORDER BY Department_bkey SELECT * FROM [dbo].[dim_Department] FOR SYSTEM_TIME AS OF '2024-04-21 09:49:26.415' AS pointintime ORDER BY Department_bkey Let’s
select all rows at only from history and not including current rows: SELECT * FROM [dbo].[dim_Department_History] ORDER BY Department_bkey, ValidFrom_UTC_metadata Let’s
insert a row with a business key value that already exists in current time: INSERT INTO [dbo].[dim_Department]([Department_bkey],[DepartmentName]) VALUES('12S','Sales') GO Error
message: Msg 2601, Level 14, State 1, Line 23 Cannot insert duplicate key row in object 'dbo.dim_Department' with
unique index 'UIX_dim_Department_Department_bkey'. The duplicate key value is
(12S). The statement has been terminated. If we insert business key 12F for Finance,
that we deleted before, it will be accepted in current time and the new row
will be giving a new unique sequence number in column Department_key. Let’s
select all rows at history full time line and look into Kimball dimensions: SELECT * FROM [dbo].[dim_Department] FOR SYSTEM_TIME ALL AS historytime ORDER BY Department_bkey, ValidFrom_UTC_metadata
Temporal table history full timeline
looks like a Kimball type 2 dimension, but it is not a Kimball type 2
dimension because the column Department_key is not unique in each row and
therefore a fact row can not refer to a specific dimension key row with
values at the time when the fact data was happening or occurred with its
transaction date or was entered into the fact. The dimension key is not an artificial
auto-generated unique sequence number for each update of values in the dimension
and therefore temporal table is useless for any dimension. Same example from Kimball design tip #100 Temporal table looks like a Kimball type
4 dimension because keeping history in the separate table while original
dimension table keeps current dimension member, but the dimension key is not
an artificial auto-generated unique sequence number. Temporal table current time looks
like a Kimball type 1 dimension when
we include the deleted rows because older fact rows can be referring to it: SELECT cur.* FROM [dbo].[dim_Department] cur UNION ALL SELECT his.* FROM [dbo].[dim_Department] FOR SYSTEM_TIME ALL AS his WHERE NOT EXISTS(SELECT 1 FROM [dbo].[dim_Department] cur
WHERE cur.Department_bkey = his.Department_bkey) ORDER BY Department_bkey
Temporal table system-versioned
table is a Kimball type 1 dimension with an addition of a history-tracking to
handle historical data values for changes (updated or deleted) at any time. Temporal table can be useful for a
Data vault Satellite and for an archive table. Let’s
select all rows at point in time and no rows at 11:15:00 Danish/CET time: DECLARE @dt_dk AS datetime2(3) = '2024-04-21 11:15:00.000' DECLARE @dt AS datetime2(3) = @dt_dk AT TIME ZONE 'Central European Standard Time' AT TIME ZONE 'UTC' SELECT * FROM [dbo].[dim_Department] FOR SYSTEM_TIME AS OF @dt AS pointintime ORDER BY Department_bkey Let’s
select all rows for yesterday 24 hours ago for Danish/CET time: DECLARE @dt AS datetime2(3) = SYSDATETIME() AT TIME ZONE 'Central European
Standard Time' AT TIME ZONE 'UTC' or DECLARE @dt AS datetime2(3) = SYSUTCDATETIME() SELECT * FROM [dbo].[dim_Department] FOR SYSTEM_TIME ALL AS historytime WHERE ValidFrom_UTC_metadata >= DATEADD(day, -1, @dt) ORDER BY Department_bkey, ValidFrom_UTC_metadata Let’s
add a column into the temporal table system-versioned table: ALTER TABLE dbo.dim_Department ADD DepartmentType VARCHAR(50) NULL GO Or
with a default value: ALTER TABLE dbo.dim_Department ADD DepartmentType VARCHAR(50) NOT NULL CONSTRAINT DF_dbo_dim_Department DEFAULT ('NON') GO Let’s
drop a column at the temporal system-versioned table: ALTER TABLE [dbo].[dim_Department] DROP CONSTRAINT [DF_dbo_dim_Department] GO ALTER TABLE dbo.dim_Department DROP COLUMN DepartmentType GO Let’s
delete all current rows: TRUNCATE TABLE [dbo].[dim_Department] Error
message: Truncate
failed on table 'dbo.dim_Department' because it is not a supported operation
on system-versioned tables. DELETE FROM [dbo].[dim_Department] No
current rows: SELECT * FROM [dbo].[dim_Department] Still
historical rows: SELECT * FROM [dbo].[dim_Department] FOR SYSTEM_TIME ALL AS historytime ORDER BY Department_bkey, ValidFrom_UTC_metadata SELECT * FROM [dbo].[dim_Department_History] ORDER BY Department_bkey, ValidFrom_UTC_metadata Let’s
delete all historical rows: DELETE FROM [dbo].[dim_Department_History] Error
message: Cannot delete rows from a temporal
history table 'dbo.dim_Department_History'. Disable
temporal system-versioned table and empty dim_Department_History: ALTER TABLE [dbo].[dim_Department] SET ( SYSTEM_VERSIONING = OFF ) TRUNCATE TABLE [dbo].[dim_Department_History] dim_Department_History
becomes a normal table that is empty. Enable
temporal system-versioned table with dim_Department_History: ALTER TABLE [dbo].[dim_Department] SET ( SYSTEM_VERSIONING = ON (HISTORY_TABLE = [dbo].[dim_Department_History])) dim_Department_History
is again a part of dim_Department system-versioned and new rows can be
inserted and existing rows can be updated and deleted with history-tracking. Let’s
drop the temporal system-versioned table: --Disable the system versioning ALTER TABLE [dbo].[dim_Department] SET ( SYSTEM_VERSIONING = OFF ) GO --Now drop dim_Department table DROP TABLE IF EXISTS [dbo].[dim_Department] DROP TABLE IF EXISTS [dbo].[dim_Department_History] GO --Drop Period definition in case of manipulation of
periods IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[dim_Department]') AND type in (N'U')) ALTER TABLE [dbo].[dim_Department] DROP PERIOD FOR SYSTEM_TIME GO Temporal table Usage Considerations and limitations Querying Create Example 21.
Schema Folder If you have several schemas to divide
objects, a Schema Folder is possible to add to Management Studio Schema-Folders add-ins by an unzip and move the folder
with its files into a folder under SSMS:
22.
About me I have worked with SQL Server since
1997 called 6.5 and the first production was running in 7.0 in 1998. Remark: datetime2(n) has a date
range of 0001-01-01 through 9999-12-31 while datetime starts from 1753-01-01.
datetime takes 8 bytes in storage size. datetime2 takes 6 bytes for
precisions less than 3; 7 bytes for precisions 3 and 4 else takes 8 bytes. datetime2(3)
has same precision as datetime. smalldatetime has a date range of 1900-01-01
through 2079-06-06 and 00 second in the timepart and takes 4 bytes in storage
size and I could use »the forever date« like 2070-12-31. date has storage size 3 bytes and
int has 4 bytes, therefore a date as a integer like 20141231 is not so
important anymore. For a olap cube I prefer the date key column to be a int
data type and for a tabular model I prefer the date datatype. bigint has
storage size 8 bytes and has better performance for join columns in a query
instead of datetime2. Stop using
datetime and Getdate(), use datetime2(3) and Sysdatetime() or SysUTCdatetime(): [InsertTime_meta]
[datetime2](3) NOT NULL CONSTRAINT [DF_Dim_Company_InsertTime_meta] DEFAULT
(sysdatetime()) ALTER
TABLE [dim].[Company] ADD CONSTRAINT [DF_Dim_Company_InsertTime_meta] DEFAULT
(sysdatetime()) FOR
[InsertTime_meta] [InsertTime_UTC_meta]
[datetime2](3) NOT NULL CONSTRAINT [DF_Dim_Company_InsertTime_UTC_meta]
DEFAULT (sysutcdatetime()) Select BeforePaymentDate = DateAdd(nanosecond,-50,PaymentDate)
becomes: BeforePaymentDate gives 2018-02-01
23:59:59.9999999 because PaymentDate is 2018-02-02
00:00:00.0000000 Amount column with data type
Decimal(19, 4) is a popular choice for e-commerce. Remark: A nullable column allows
Null so there is no data value to indicate, null is anything and at the same
time nothing or indefinite. Null means »a missing value«. We use a Null
value because the data will be added later and we can find rows with Null value
by a Where column Is Null. We can also set a column value to Null through an
Update Set column = Null statement or by keypress Ctrl + 0 (zero) when
editing a column value in a row in a table. Sometimes I treat Null as »a nothing
value« because it sounds positive compared to a missing value followed up with
why is it missing? A Null does not equal anything
neither 0, nor empty string '' or "", nor Empty, nor another Null. Null is not equal or unequal to
anything, not even itself, and it can't be compared. The equality Null = Null returns Null,
Null != Null returns Null, Null <> Null returns Null, Not (Null = Null)
returns Null, so we must take care in Where and Join criteria with IsNull
function and Where column Is Not Null. Small
examples with results: SELECT
CASE WHEN NULL = NULL THEN 1 ELSE 2 END -- 2 neither true nor false. SELECT
CASE WHEN NULL <> NULL THEN 1 ELSE 2 END -- 2 in one row. SELECT
CASE WHEN NULL IS NULL THEN 1 ELSE 2 END -- 1 it is true. SELECT
CASE WHEN NULL IS NOT NULL THEN 1 ELSE 2 END -- 2 it is false. SELECT
CASE WHEN NOT(NULL IS NULL) THEN 1 ELSE 2 END -- 2 it is false. SELECT CASE Null WHEN 1 THEN 'True' WHEN
0 THEN 'False' WHEN Null THEN 'Blank' ELSE
'Void' END
-- gives 'Void' in one row because none of When match. A search criteria: WHERE (@code Is
Null Or CustomerCode = @code) when @code = null the expression
evaluate to (true Or null) which is true because of the Or-operator and we
fetch all customers from the table. Null reminds me of: »No answer is also
an answer« when I ask a person a question and he does not reply, his very
silence is an answer in itself. An orphan child as a row in Child
table with a column MotherId as Null. Another orphan child has also MotherId
as Null. It is good that Null = Null will evaluate to Null, because I don’t
know if the two children are siblings or not, therefore no answer. A column with a null is
known to be absent,
because the column has no value because column has not yet been assigned. Sometimes I think of null as »No
data« or »No value« or »Missing« or »Nothing«. When I receive a Christmas gift in a
box with something inside, I do not know the contents of the box, therefore the
gift is unknown to me, and known to the giver. I will not say that the gift
is null for me, okay maybe null if the box is empty but I only know that when
I open the box and I could say the gift is missing or is nothing. A primary key that is an Identity or
a Sequence column is usually a surrogate key. A primary key is a unique
identifier for all rows in a table and the column can not contain null. A secondary
key is also a unique identifier and the column can contain null in one
row only, but we can make an exception in a Patient table with a column Social
Security Number to be unique and contain several rows with null for patients
that is registered with a missing SSN for a while until it is available and known: CREATE UNIQUE NONCLUSTERED INDEX
IX_Patient_SSN ON dbo.Patient (SocialSecurityNumber ASC) WHERE
(SocialSecurityNumber IS NOT NULL). A relationship is implemented by
including the primary key in the related table and calling it the foreign
key to make sure of the consistency in database. When a database is consistent
we can navigate with a join among tables and relationships become navigation
paths. A foreign key can be null to indicate of no existing relationship. The Concat function can string
concatenation nullable column to a new string. A Null value is differ from an empty
string '' value or zero value. A null string is different than an empty string
'', because a null string doesn’t point to anything in memory. A design
pattern could be to let a string (varchar, nvarchar) column use empty string
'' as default value and not allow null. To
treat null, nothing, blank and empty string as equal to null in sql: WHERE
(NULLIF(TRIM(CustomerAddress),'') IS NULL) In
a division it is nice to use Null functions to avoid division by zero error
like this: SELECT
ISNULL(Amount / NULLIF(NumberOf,0), 0) We
also use Null e.g.: t1 Left Outer Join t2 On t1.id = t2.id Where t2.id Is
Null. Datatypes
text and ntext has been deprecated. Find
the biggest amount among the columns with a name that is including Amount: SELECT
GREATEST(* ILIKE '%Amount%') FROM
fact.Sales I
in ILIKE stands for insensitive of case string matching. From Snowflake. Please visit my homepage for the
english part: |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||