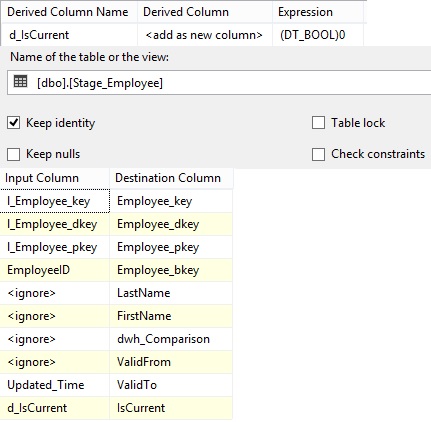
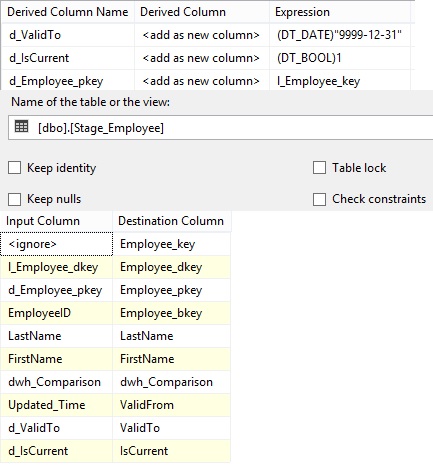
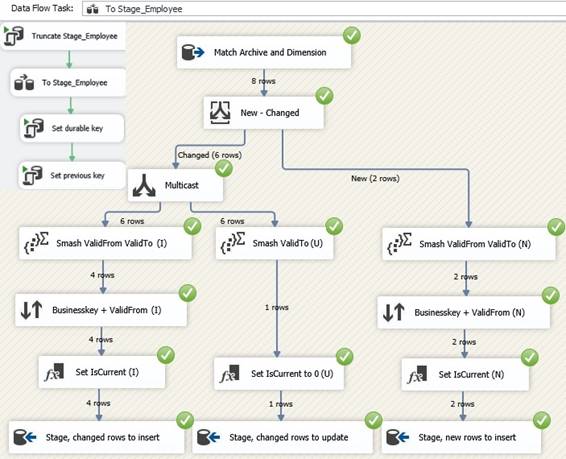
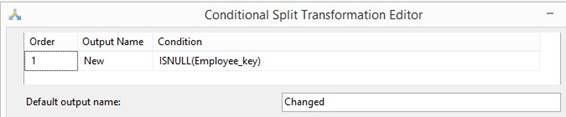
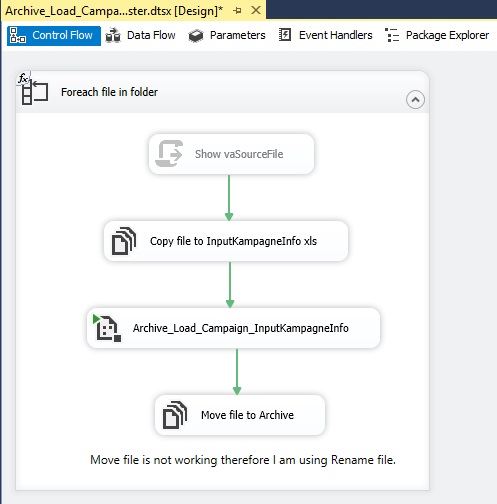
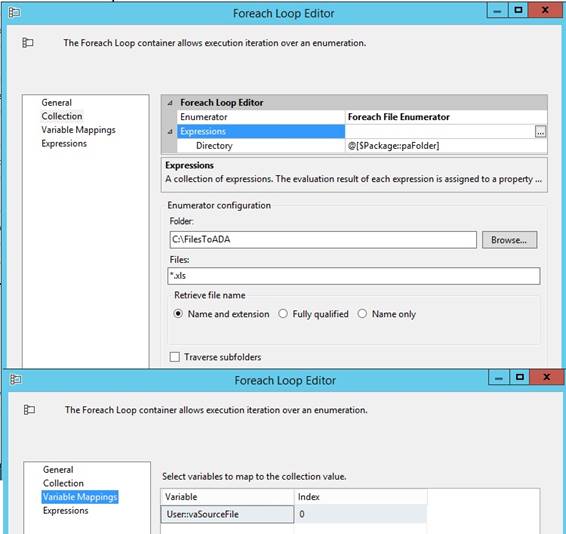
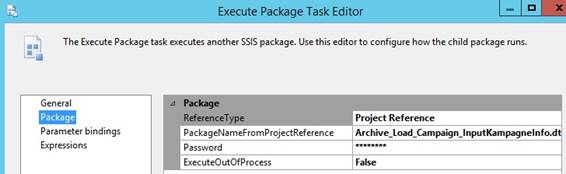
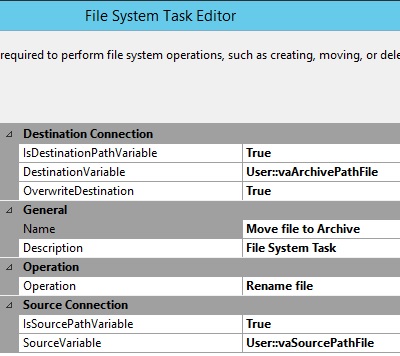
|
Tips for SSIS SQL
Server Integration Services by Joakim Dalby 1.
Introduction Best
Practices of making SSIS Integration Services package in form of some tips
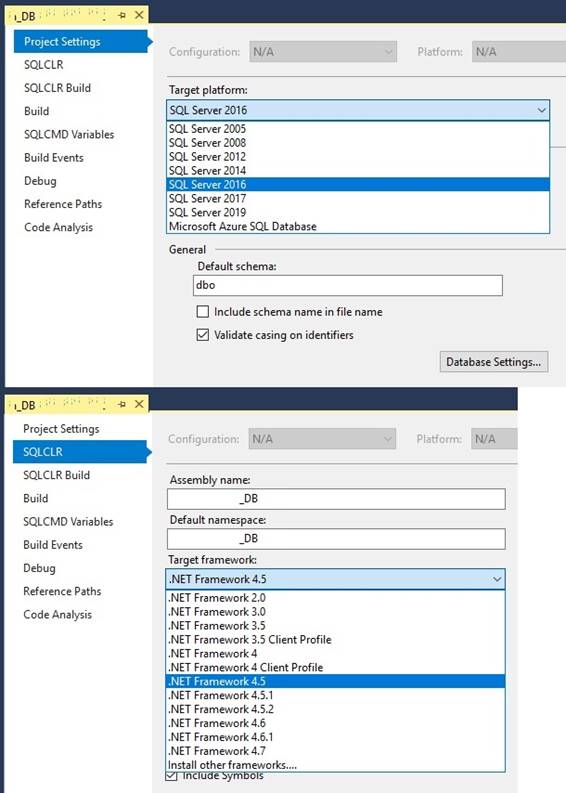
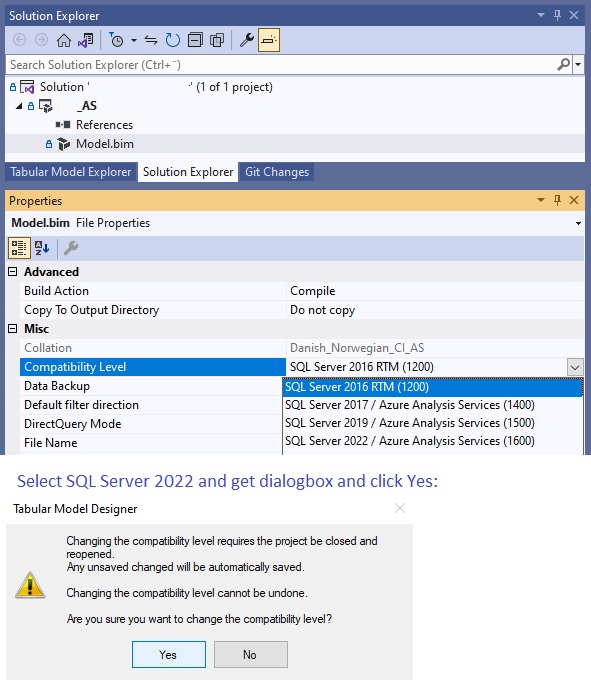
shown by examples. In my article about SQL Server 2014 I describe deployment
methods of SSIS project and package on different servere using parameter for connection
string and Environment variable inside the SSISDB catalog: SQL
Server 2014, read chapter 3 and 8. Download SSDT data tools for Visual Studio Download the latest OLE DB driver called
Microsoft OLE DB Driver for SQL Server (MSOLEDBSQL) to Native OLE DB
connection in Data Flow Task. Don’t use SQL Server Native Client 11.0
anymore: https://aka.ms/downloadmsoledbsql Read introductory text about: Microsoft OLE DB Driver for SQL Server Download the latest ODBC driver 18
for SQL Server: https://aka.ms/downloadmsodbcsql Download
the latest Microsoft OLE DB Provider for Analysis Services MSOLAP to be able
to process a cube from a SSIS package: https://learn.microsoft.com/en-us/analysis-services Analysis
Service Execute DDL Task under DLL Connection with a package variable: RIGHT(@[System::PackageName],
FINDSTRING(REVERSE(@[System::PackageName]), "_", 1) - 1) in
the Expression as @[User::CubeName] to do a full cube processing: "{\"refresh\": {\"type\":
\"full\",\"objects\":[{\"database\":\""+@[User::CubeName]+"\"}]}}" Avoid
using SqlPackage.exe from folder C:\Program Files\Microsoft Visual Studio\2022
\Community\Common7\IDE\Extensions\Microsoft\SQLDB\DAC. Instead install SqlPackage
from here using Windows (.NET Framework) DacFramework.msi to
folder C:\Program
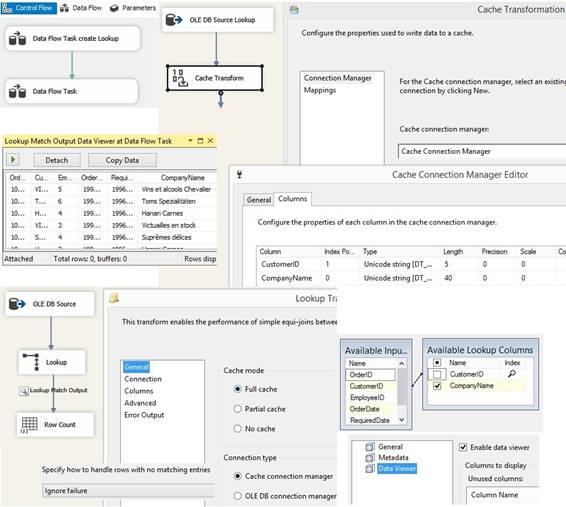
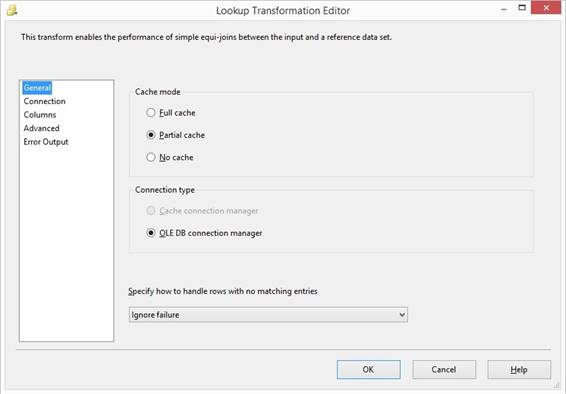
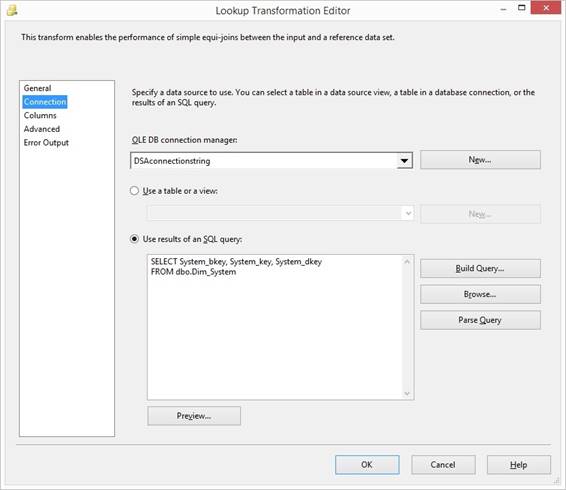
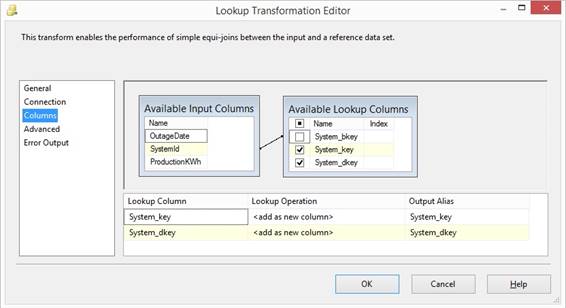
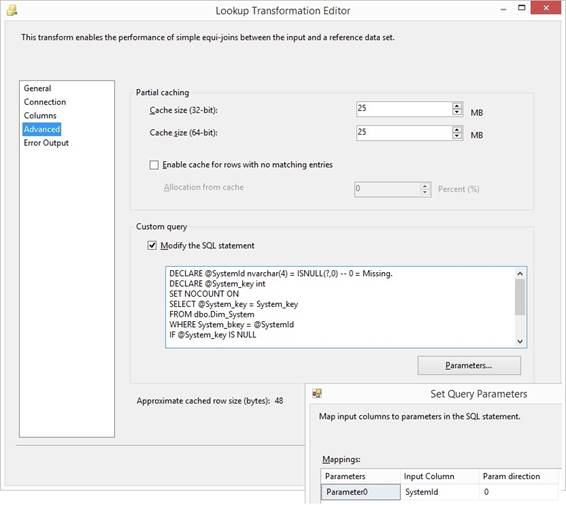
Files\Microsoft SQL Server\160\DAC\bin. Read about Deploy Integration Services SSIS Lookup performance tuning techniques
REPLACENULL(Customer_Key,-1) In
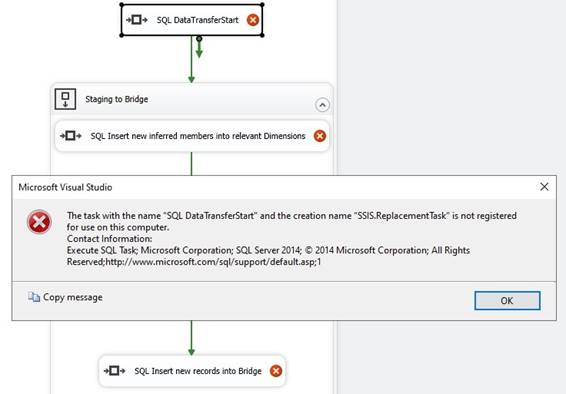
case you see one of these error message: · Failed
to save modifications to the server. Error returned: 'OLE DB or ODBC error: A
network-related or instance-specific error has occurred while establishing a
connection to SQL Server. Server is not found or not accessible. Check if
instance name is correct and if SQL Server is configured to allow remote
connections. For more information see SQL Server Books Online.; 08001; SQL
Server Network Interfaces: The handle specified is invalid; 08001; Client
unable to establish connection; 08001; SQL Server Network Interfaces: The
handle specified is invalid; 08001. A connection could not be made to the
data source with the Name of '<database>'. · Object
reference not set to an instance of an object when execute a SSIS-package. I
recommend to update to the latest OLE DB driver and to the latest ODBC
driver. A
solution in SQL Server Data Tools for Visual Studio can contain severals
projects for different data layer in a data warehouse for SSIS package, SSRS report,
SSAS olap cube, SSAS tabular cube and export to Excel file and so on. It is
almost like a .NET solution with projects that become different dll files,
but normally the dll files belong together and is called from the same exe
file. If you like to show solution node in Solution Explorer: Tools, Options,
Projects and Solutions and checkmark in 'Always show solution'. I recommand
a SSIS project per data layer in a data warehouse like for doing extraction
from source systems, for doing archive or ods, for dsa, for edw and for each data
mart. A SSIS project properties is shown
from Solution Explorer pane by rightclick the project name and select
{Properties}. I always set ProtectionLevel to DontSaveSensitive so other developers can access the SSIS
package therefore no depending of the creator user and a password. When a package
is saved, sensitive password values will be removed. This will result in
passwords needing to be supplied to the package through a configuration file
or by the user. All new IS package inherits the protection level. More reading with different approaches. An example of a SSIS design pattern parent-child. SSIS vs Azure Data Factory vs Azure Databricks Please remember to consider MaxConcurrentExcecutables property in
the SSIS package, more at this links Data Flow Performance Features and Performance Tuning Techniques. When SSIS package runs on a
dedicated server and there are a lot of operations that run in parallel, it
can be beneficial to increase this setting if some of the operations
(threads) do a lot of waiting for external systems to reply. A Data Flow Task
has property for EngineThreads, DefaultMaxBufferRows and DefaultMaxBufferSize
and by using the property AutoAdjustBufferSize
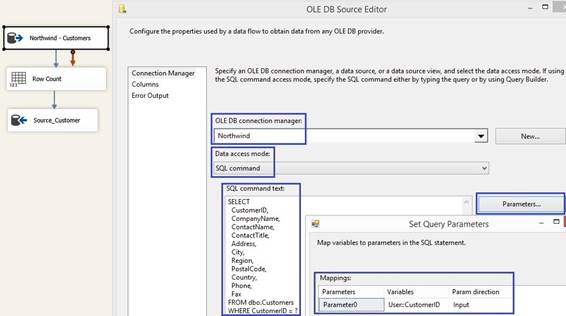
set to True it will improve SSIS data flow buffer performance. When a OLE DB Source wants to fetch
data from a view in a database, use SQL command with Select * From <view> that will give better
performance. A
SSIS project has a Connection Managers where all connectionsstring to files
and database should be, so they can be reused in all the SSIS packages in the
project. Rightclick
at Connection Managers and select {New Connection Manager} and for connection
to a SQL Server database select OLEDB and click [Add] and [New], typein SQL
Server name, normally use Windows Authentication and select the database in
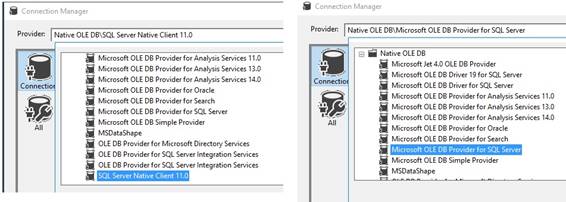
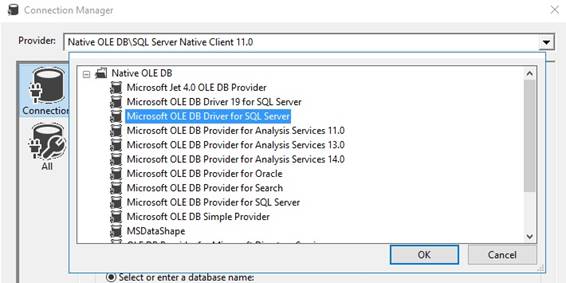
the dropdown. OLEDB data provider was Native OLE DB\SQL Server Native Client 11.0. This connection is
used in Control Flow at Execute SQL Task and in Data Flow Task at OLE DB
Source, OLE DB Destination and Lookup. The SQL Server Native Client has been
removed from SQL Server 2022 (160) and SQL Server Management Studio 19. The
SQL Server Native Client (SQLNCLI or SQLNCLI11) and the legacy Microsoft OLE
DB Provider for SQL Server (SQLOLEDB) are not recommended for new
development. OLEDB data provider must be Microsoft OLE DB Driver for SQL Server
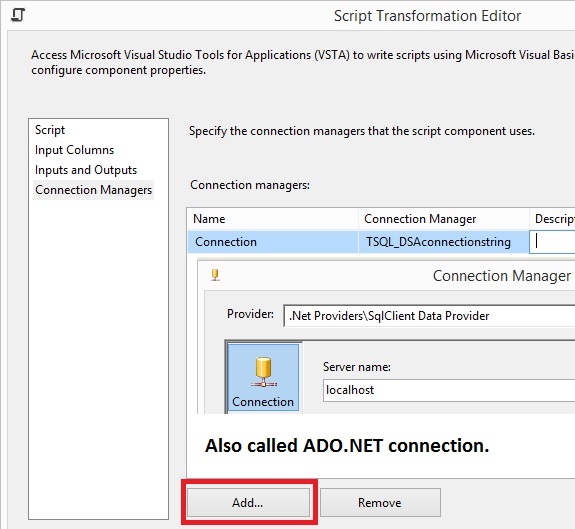
(MSOLEDBSQL) or the latest Microsoft ODBC Driver for SQL Server. ADO.NET connection manager type .Net Providers\SqlClient Data Provider. This
connection is used in Execute T-SQL Statement Task, Execute SQL Task and when
Script Component wants to read directly from a sql server via SqlCommand. A
connection manager used inside a SSIS package has a property Expression that for a flat file which
name include a date yyyy-mm-dd can have an expression that assign the right
filename at runtime mode for a dynamic connection like this with a double backslash
in the file path: "C:\\File\\Customer"+LEFT((DT_WSTR,30)GETDATE(),10)+".csv" Want
a " inside a "…string…" use a backslash before " e.g. in
a variable assigment: "<root
xmlns:joda=\"www.joda.xml\"/>" To
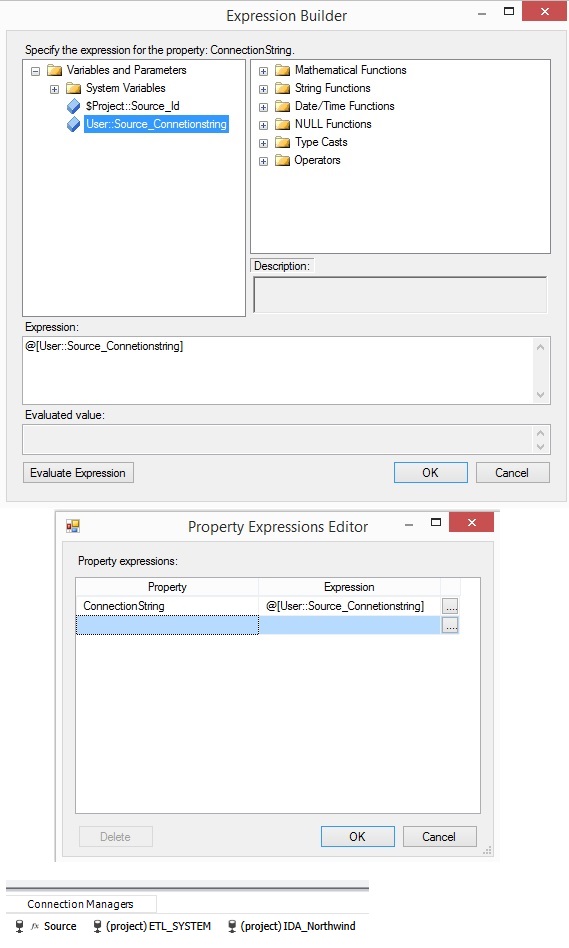
a connection manager e.g. a SQL Server database with SQL Server Authentication
you can assign server name, database name, username and password to package variables (user::) and add
the variables to the connection manager property Expression so you can insert
OLE DB Source or OLE DB Destination in same way as the Windows Authentication
and the best part it is still working together with DontSaveSensitive, only
the button [Test connection] is not working, but no problem with that. Config
file can assign the variables for running mode at the production server etc. Schema Compare i
Visual Studio mellem et database projekt og en database Kræver SQL Server
"view definition" så Visual Studio kan udføre korrekt Schema
compare for at kunne se definition af tabel struktur, view struktur, stored
procedure kode, etc. Læs mere GRANT
VIEW DEFINITION TO [user]; Show SSIS Toolbox In
menubar select View and Other Windows and SSIS Toolbox and you have it in the
left side of your screeen showing the tools or components depends of you are
in a control flow or a data flow canvas. To delete a row in a component Like
'Derived Column' or 'Union All', first left click at another row and then set
mouse over the want-to-delete row and right click and select {Delete} in the
menu. ID of package Make
sure the package ID guid number is unique if you using a template or have
copied a package, go to property ID and click dropdown and select Generate
New ID. Get the ID by parameter System::PackageID. Also a
System::PackageName. More about System Variables in SSIS package. Execute and format a SSIS package Normally
I run a SSIS packages from the design mode by clicking at Start button, but sometimes
it will evaluate and syntax check all files in the project and in the
solution. To avoid that it is better to close all tabs (or documents as SQL
Server Data Tools for Visual Studio call them) and right click the package
and choose {Execute Package} like this:
Layout of a SSIS package In
case you like to organized the layout of a SSIS package, Format can helps:
Some of the components
2.
Control Flow and Data Flow components A
SSIS package has a 'Control Flow' canvas
or design surface which is using 'Task' components to display the steps
of a process and is the task workflow engine that coordinates the business
process flow logic for a package. The 'Data Flow' is the data processing
engine that handles data movement, transformation logic, data organization,
and the extraction and commitment of the data to and from sources and
destinations.
Some of the components and the usage
"N'"+@[$Project::BackupDirectory]+"\\Backup_"+@[User::Name]
+".bak'"
@[User::Counter]
= @[User::Counter] + 1 Only
one package variable can be assigned a value in a 'Expression Task', so with
multiple variable I need to make multiple 'Expression Task's or instead make
a 'Script Task' what can do multiple variables in a C# program. Building
a dynamic sql statement to a variable and use it in 'OLE DB Source' e.g. to
fetch delta data for incremental load, Where Id > max value. ·
Script
Task do C# programming at package variable
like show the value in debug runtime mode, remember to set property ReadOnlyVariables: using
System.Windows.Forms;
// a namespace in top of the code MessageBox.Show(Dts.Variables["User::CustomerName"].Value.ToString()); or System.Windows.Forms.MessageBox.Show(Convert.ToString(Dts.Variables["User::Num"].Value)); if
the variable can be null. Examples with the three types of variable: MessageBox.Show(Dts.Variables["User::PackageVariable"].Value.ToString()); MessageBox.Show(Dts.Variables["$Package::PackageParameter"].Value.ToString()); MessageBox.Show(Dts.Variables["$Project::ProjectParameter"].Value.ToString()); Script
can do calculations with programming or build a dynamic sql statement to a
variable and use it in 'Execute SQL Task' to store a value in a table with sql
Insert or Update. In 'Execute SQL Task' set SQLSourceType to Variable and at
SourceVariable pick a package variable like User::TSQLSaveCalculation
when it is a dynamic build sql statement.
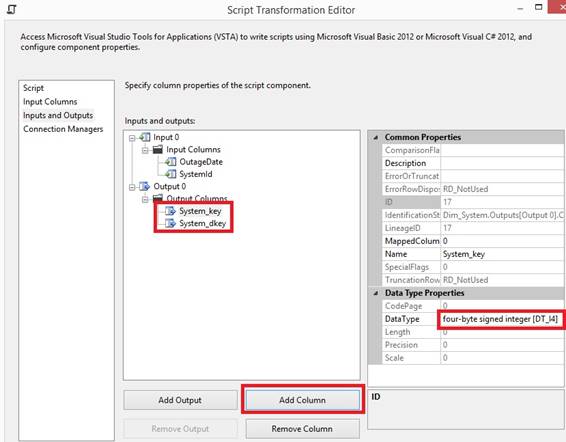
And
open 'OLE DB Source Output' and open 'Output Columns' and select the first
column from ORDER BY and set property SortKeyPosition to 1:
Continue
with next column from ORDER BY that is set to 2 and so on. When a column is DESC
SortKeyPosition gets a minus in front as a negative value. Read more. When data source can’t be ORDER BY like a flat
file but data is delivered sorted, use SortKeyPosition on the columns that is
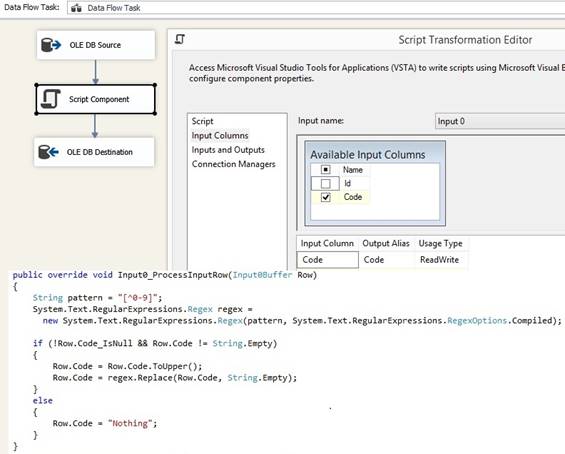
actually sorted. 'Sort' removes duplicate values of sort key from a flat file. From
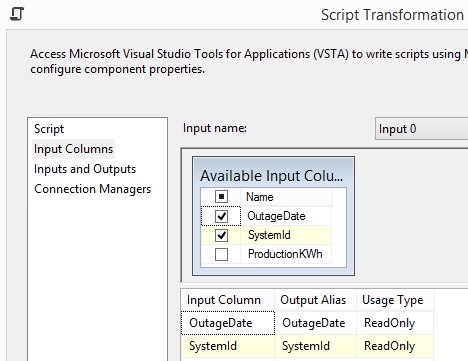
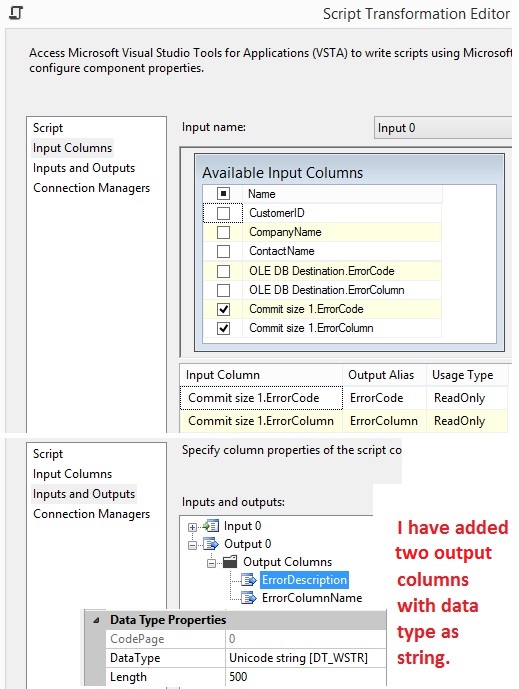
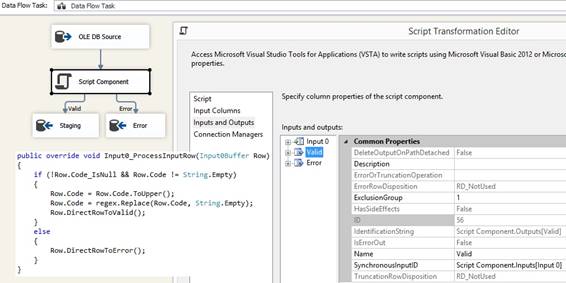
a OLE DB Source make a Script Component type Transformation to do filter duplicates in C# and remember
to set property at page Inputs and Outputs at Output 0 set ExclusionGroup from
0 to 1. Filter on CustomerName: using System; using System.Data; using
Microsoft.SqlServer.Dts.Pipeline.Wrapper; using Microsoft.SqlServer.Dts.Runtime.Wrapper; using System.Collections.Generic; [Microsoft.SqlServer.Dts.Pipeline. SSISScriptComponentEntryPointAttribute] public class ScriptMain : UserComponent { public HashSet<string> Customers = new HashSet<string>(); // int, script
task variable public override void Input0_ProcessInputRow(Input0Buffer Row) { if (Row.CustomerName_IsNull) return; if (!Customers.Contains(Row.CustomerName)) { Customers.Add(Row.CustomerName); // only unique values is added. Row.DirectRowToOutput0(); } } }
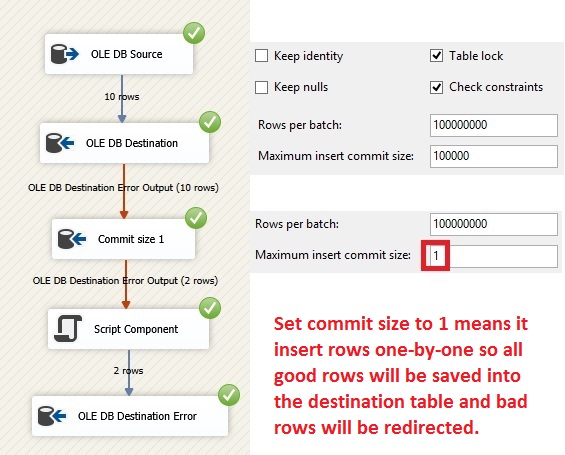
OLE
DB Destination has a property FastLoadOptions that normally shows TABLOCK,
CHECK_CONSTRAINTS. Four extra options can be added there: ROWS_PER_BATCH
= <number> <number>
indicates that destination is configured to use batches of rows. KILOBYTES_PER_BATCH
= <number> <number>
specifies the size in kilobytes to insert. FIRE_TRIGGERS Specifies
whether triggers fire on the insert table because of fast load/bulk. ORDER(<columnname>
ASC, <columnname> DESC) Specifies
how the output data is sorted. If sort order is omitted, the insert operation
assumes the data is unsorted. Performance can be improved if you use the
ORDER option to sort the output data according to the clustered index on the
table. For clarity, the ORDER hint needs to exactly match the clustering column
of the destination table. ORDER is specially good when OLE DB Source is a
flat file. E.g. Id is a clustered index on the destination table, the FastLoadOption
property will have this statement: TABLOCK,ROWS_PER_BATCH
= 100000000,ORDER(Id) Another
example has no tablock because pipeline stop inserting data when someone
select from the table and it has a three column composite primary key that is
non-clustered because there is a unique clustered index on a Identity
column that just grow for each inserted row and since the OLE DB Source has a
Order By in select statement and property IsSorted is True and 1 column is Date,
2 is SeqNo and 3 is DeviceNo because I want that sort order for the OLE DB
Destination table rows, I am using this FastLoadOption: ROWS_PER_BATCH
= 100000000,ORDER(Date,SeqNo,DeviceNo) Remember
to set database property Recovery model to Simple. Remember also to look at
index to get faster load performance like this: *
Disable/drop non-clustered indexes before bulk load. *
Rebuild/create non-clustered indexes
after bulk load. The Data Loading Performance Guide
3.
Data type and Expression Data Conversation is not using SQL
Server database table data type and SSIS package variable and SSIS project
parameter has their own data type, the map is:
Script Task C# datetime, string, byte, short (int16), int
(int32) og long (int64). (DT_WSTR, <length>) unicode
string, length of characters, for nvarchar or nchar, e.g. (DT_WSTR,30) for
nvarchar(30). (DT_STR, <length>, <codepage>)
ansi string with codepage 1252 for varchar or char, e.g. (DT_STR,30,1252) for
varchar(30). When you have a nvarchar column in a
source table and you want only the first three letters and save it in a
varchar column in a destination table, do this in a Derived Column to cast
the value to codepage 1252 = ansi = varchar data type: (DT_STR,3,1252)SUBSTRING(<columnname>,1,3) Or save it in a nvarchar column in a
destination table: (DT_WSTR,3)SUBSTRING(<columnname>,1,3) Illegal characters are replaced to
empty string varchar(100) for ansi: (DT_STR,100,1252)REPLACE(investmentdecisionwithinfirm,"�","") ANSI has code page 1252 as standard
for the SSIS pipeline to a SQL Server table. UTF-8 has code page 65001 is often the
encoding for a csv file. Derived Column will be added for
each column from a csv file to do a conversion to codepage 1252 ANSI with
cast like this for a column called clientidcode: clientidcode_ = (DT_STR,100,1252)clientidcode to a new derived column called
clientidcode_.
DT_NUMERIC(<precision, scala>)
precision tells the max number of digits in the number value both left and
right of decimal point, scale tells the number of digits right of decimal
point. Like DT_NUMERIC(5,2) is max 999.99. (DT_DECIMAL,2) cast string to
decimal value with 2 digits after decimal point. Read more about Integration Services Data Types DateTransaction
with data type date has derived column expression: ISNULL(TransactionDatetime)
? (DT_DBDATE)"1900-01-01" : (DT_DBDATE)TransactionDatetime DateTimeTransaction
with data type datetime has derived column expression: ISNULL(TransactionDatetime)
? (DT_DATE)"1900-01-01 00:00:00.000" : (DT_DATE)TransactionDatetime Date with data type integer as
yyyymmdd has derived column expression: (DT_I4)((YEAR(OrderDate)
* 10000) + (MONTH(OrderDate) * 100) + DAY(OrderDate)) (DT_I4)(REPLACE((DT_WSTR,
12) (DT_DBDATE)GETDATE(),"-","")) (DT_WSTR,4)YEAR(GETDATE())
+ RIGHT("0" + (DT_WSTR,2)MONTH(GETDATE()),2) +
RIGHT("0" + (DT_WSTR,2)DAY(GETDATE()),2) Active Player Day as CustomerId
concat with yyyymmdd as bigint value: (CustomerId *
(DT_I8)100000000) + ((YEAR(PlayDate) *
10000) + (MONTH(PlayDate) * 100) + DAY(PlayDate)) Time_key with date type smallint
where null value become -1 and time 10:34:45 become 1034 has derived column
expression: ISNULL(TransactionDatetime)
? (DT_I2)-1 : (DT_I2)DATEPART("hh",TransactionDatetime) * 100 +
DATEPART("mi",TransactionDatetime) (DT_DBTIME2, «scale») e.g.
(DT_DBTIME2,2)TransactionDateTime has between 0 and 7 digits specified
for fractional seconds. 24-hour
clock in the format HH:mm:ss. 12-hour
clock in the format hh:mm:ss. mm
for minutes and MM for number of month. string dt = DateTime.Now.ToString("yyyyMMddTHHmmss"); string dt =
DateTime.UtcNow.ToString("yyyy-MM-ddTHH:mm:ss.fffZ"); Z
indicates Zero time zone, i.e. that the time is in UTC time zone e.g. 2014-05-26T22:17:38.549Z Variable name is case-sensitive like
in C#. Using a variable in script C#
programming: Dts.Variables["User::Number"].Value; Using a variable in an Expression: @[User::Name] MONTH(@[User::Birthdate]) == 5
? "May" : "Another
month" Using a package parameter in an
Expression: @[$Package::Keyvalue] Using a project parameter in an
Expression: @[$Project::BackupDirectory] Using a system variable in an
Expression: @[System::PackageName] Cast always a value,
Return null value cast to the right data type
Expression that cast or convert an integer value to concatenate to a string: OrderDate is a datetime2(7) column
to set to a fixed value: (DT_DBTIMESTAMP2,7)"2013-05-27
16:42:37.4900000" OrderDate is a datetime, cast it to
a dbdate and to a date that has time 00:00:00 (DT_DBDATE)OrderDate
results in a date. ISNULL(OrderDate) ?
NULL(DT_DBDATE) : (DT_DBDATE)(OrderDate) (DT_DATE)(DT_DBDATE)OrderDate
results in a datetime with 00:00:00. If column OrderDateDatetime is null
then use a fixed date else the column: ISNULL(OrderDatetime)
? (DT_DATE)"2000-01-01 00:00:00.000" : (DT_DATE)OrderDatetime Fetch out each part of a date as
dd-mm-yyyy to become yyyy-mm-dd: (DT_DATE)(SUBSTRING(OrderDatetime,7,4)
+ "-" +SUBSTRING(OrderDatetime,4,2) + "-" + SUBSTRING(OrderDatetime,1,2)) Get OrderDate as the first day of
the month: (DT_DBDATE)((DT_WSTR,4)(YEAR(OrderDate))
+ "-" +
(DT_WSTR,2)(MONTH(OrderDate)) + "-01") (DT_WSTR,4) is C# way to cast a
value to a nvarchar(4). (DT_WSTR, 10)
(DT_DATE) DATEADD("dd", –
@[$Package::DaysAgo] , GetDate()) Make a filename with number of
current month: "C:\\File\\Data_"+RIGHT("0"+
(DT_WSTR,2) MONTH(GETDATA()), 2)+".txt" (DT_WSTR,2) is C# way to cast a
value to a nvarchar(2). (DT_DECIMAL,2) cast string to decimal
value with 2 digits after decimal point. Get Filename from column
PathFileName: RIGHT([PathFileName],FINDSTRING(REVERSE([PathFileName]),
"\\",1) – 1) Get Folderpath from column
PathFileName: SUBSTRING([PathFileName],
1, LEN([PathFileName]) – FINDSTRING(REVERSE([PathFileName] ), "\\"
,1 ) + 1) Get Foldername from column
PathFileName: TOKEN[PathFileName],”\\”,TOKENCOUNT([PathFileName], "\\")
– 1) FINDSTRING(ReceiptNumber,"-",1)
>= 1 ? ReceiptNumber :
LEFT(TransactionIdentification,17) != LEFT(LinkTransactionIdentification,17)
?
LEFT(LinkTransactionIdentification,17) : NULL(DT_WSTR,17) SSIS package parameter is called
with or is using a default value: SourceFolderPathName = \\fileserver\Landingzone\CRM\SourceZipFiles\20220627 A SSIS package variable has an expression to fetch the date e.g. 20220627: SourceFolderName
= REVERSE(LEFT(REVERSE(@[$Package::SourceFolderPathName]), FINDSTRING(REVERSE(@[$Package::SourceFolderPathName]), "\\", 1) - 1)) Guid variable with data type Object Dts.Variables["User::Guid"].Value
= "{" + Guid.NewGuid().ToString() + "}"; Expression is useful in Derived
Column but can also be used in Send Mail Task for property Subject like "ETL
done at: " + (DT_WSTR,30) @[System::StartTime] +"." Or in Execute SQL Task at property
SqlStatementSource to make a dynamic sql statement but be careful because it
can be hard to read, understand and maintain. I think it is better using a variable
for dynamic sql so I can messagebox it for syntaks and correctness before it
is send to the database server to pull or fetch data to a resultset inside Execute
SQL Task or before to a 'Source' but SSIS now prefer a variable. I can make
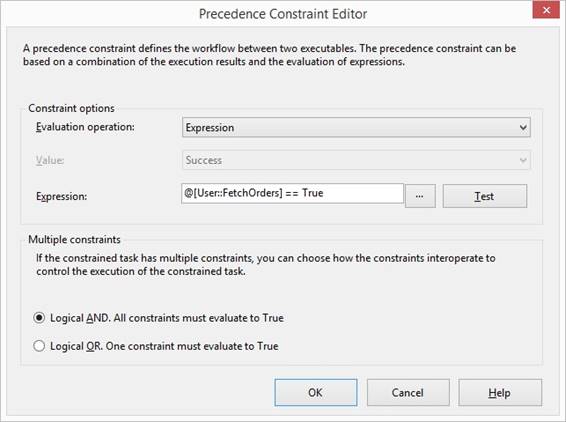
an expression at the Data Flow Task to Disable it, in case a previous step
had put pipeline Row Count to a variable: @[User::NOBills] == 0, or at Precedence
constraint green arrow
for continue when @[User::NOBills]
> 0 and a fx logo is shown. Expression operators taken from C#:
SUBSTRING,
UPPER, LOWER, TRIM, LEN, DATEDIFF, CEILING for round up, FLOOR for round
down, REPLACENULL(<columnname>, 0) for if null replace zero in SSIS. SWITCH / CASE expression becomes a
if-elseif-else statement like this: (condition1) ? (true value1) :
(condition2) ? (true value2) : (false value) A
boolean value is either True or False. A bit value is either 0 or 1. ISNULL(Keep) ? NULL(DT_BOOL) : (DT_BOOL)(Keep
== "false" ? 0 : 1) anything
else becomes true. ISNULL(Keep) ? NULL(DT_BOOL) : (DT_BOOL)(Keep
== "false" ? 0 :
(Keep == "true" ? 1 :
NULL(DT_BOOL))) anything else becomes null. ISNULL(Keep) ? NULL(DT_BOOL) :
(DT_BOOL)(REPLACE(REPLACE(Keep,"false","0"),"true","1")) Example of how to calculate number of
days in a derived column expression: ContiguousDayCounter=DATEDIFF("dd",(DT_DBDATE)"1979-12-31",(DT_DBDATE)TransactionDatetime) Or a special number with value e.g.
12031-852356-21 up to 30 characters length: SpecialNumber =
(DT_WSTR,30)((DT_WSTR,10)DATEDIFF("dd",(DT_DBDATE)"1979-12-31",
(DT_DBDATE)TransactionDatetime) + "-" + (DT_WSTR,12)SEQNO +
"-" + REPLACENULL(DEVICEN0,"00")) VB example in a Script Component that
build up a large string with errors: Public Class ScriptMain Inherits
UserComponent
Dim errorMessages As StringBuilder = New StringBuilder()
Public Overrides Sub Input0_ProcessInputRow(ByVal Row As Input0Buffer)
errorMessages.AppendLine( String.Format("Key
value {0} not found in the reference table.", Row.KEY))
End Sub Unnatural NULL Behaviour in SQL server
In SSIS C# Script component Any
equality or non-equality comparison with null (==, !=) works as expected, i.e.: null
== null //true null
!= null //false null
== nonNull //false null
!= nonNull //true Any
inequality comparison with null (>=, <, <=, >) returns false even
if both operands
are null, i.e.: null
> anyValue //false null
<= null //false IsNullOrEmpty
function checks whether or not a string is empty or null. DBNull is not null
(Nothing) but rather is a class that indicates a value from a database does
not exist. IsDbNull checks for whether or not a value equals DBNull. IIf(String.IsNullOrEmpty(DBNull.Value.ToString),
"", DBNull.Value) Derived column ISNULL(SalesPersonName) ? "Missing"
: SalesPersonName better with: REPLACENULL(SalesPersonName,
"Missing") (or use "N/A"). REPLACENULL(SalesAmount, (DT_CY)0) REPLACENULL(SalesDate, (DT_DBDATE)"1900-01-01") REPLACENULL(SalesDateTime,
(DT_DATE)"1900-01-01
00:00:00.000") In case of null value or a zero length empty
string value: (ISNULL(SalesPersonName) || TRIM(SalesPersonName)
== "") ?
"Missing" : TRIM(SalesPersonName) ISNULL(DrawNumber) ? "-" :
TRIM(DrawNumber) Make sure of the data type, works also
for decimal with 2 decimals: ISNULL(Amount) ? (DT_NUMERIC,15,2)0 :
(DT_NUMERIC,15,2)Amount (DT_STR, 4, 1252)([Amount] < 300 ?
"Low" : "High") to
a varchar(4) column. (DT_WSTR, 4)([Amount] < 300 ?
"Low" : "High") to a nvarchar(4) column. Making a derived column d_Number
from a Number column nvarchar(50) with null or empty string because it gives:
failed because error code 0xC0049064 and failed with error code 0xC0209029 : TRIM(Number) ==
"" ? NULL(DT_I8) : (DT_I8)Number Making a new Id as first 17 digits
from a string and cast it to bigint: (DT_I8)REPLACENULL(LEFT(LinkId,17),
LEFT(Id,17)) But if the both text column can contain
an emtpy string: ISNULL(LinkId)
|| TRIM(LinkId) == "" ? (ISNULL(Id) || TRIM(Id) == "" ?
NULL(DT_I8) : LEFT(Id,17)) : (DT_I8)LEFT(LinkId,17) Derived
column does not have a sql try_cast
but Derived column has a button called Configure Error Output and in the
dialogbox you can change to 2 x Ignore failure when you like to cast or convert
a text/string with digits to a real number with a data type as bigint: NationalIdentification_Integer =
(DT_I8)NationalIdentification_Text If
column NationalIdentification_Text has a 007 it becomes a 7 and has a JB007
becomes a NULL in the new derived column NationalIdentification_Integer in
the pipeline to a destination/target table to be saved in a table in a bigint
column. A script component has a tryparse to
check if LinkId or Id contain a not valid number e.g. 101A or BC123456-7. Active Player Day as CustomerId
concat with yyyymmdd as bigint value: (CustomerId *
(DT_I8)100000000)+ ((YEAR(PlayDate) *
10000) + (MONTH(PlayDate) * 100) + DAY(PlayDate)) Compare two columns that might have a Null in a Conditional
Split I always replace Null with this character
¤ because very rare a text in a column only has this value. Then I can
compare columns that has checkmark in 'Allow Nulls'. For nvarchar I can replace Null to ¤
because columns are already a string: REPLACENULL(s_Name,"¤") !=
REPLACENULL(d_Name,"¤") For int, bigint, tinyint, smallint,
decimal, float, real, numeric, money, and date, datetime and time, I first
cast column to a string with 30 characters: REPLACENULL((DT_WSTR,30)s_Number,"¤")
!= REPLACENULL((DT_WSTR,30)d_Number,"¤") A CustomerNo is a bigint and when it is
null I want to -1 instead of null: REPLACENULL(CustomerNo, (DT_I8)-1) or (DT_I8)REPLACENULL(CustomerNo,-1) If an OrderDate column in pipeline is
null then change it to January 1, 1900: REPLACENULL(OrderDate, (DT_DBDATE)"1900-01-01") If an OrderDate column with data type datetime
as time 00:00:00.000 in this date 2016-12-31, I cast the date with (DT_DATE)
to make it 2016-12-31 00:00:00.000 so the two dates can be compared, then
give true else false: OrderDate == (DT_DATE)"2016-12-31"
? (DT_BOOL)1 : (DT_BOOL)0 If a ValidTo date column with no time I
cast the date with (DT_DBDATE): (DT_DBDATE)ValidTo
== (DT_DBDATE)"9999-12-31" ? (DT_BOOL)1 : (DT_BOOL)0 If divide by zero then let the result be
0 else calculate the ratio: REPLACENULL(Quantity,0) == 0 ? 0.0 :
Price / Quantity Other string functions Replace in a string or if integer, cast
first: REPLACE((DT_WSTR,8)NumberOfDays,"6","5") Replace zero (0) with NULL: REPLACE((DT_WSTR,8)<IntegerColumn>,"0",NULL(DT_I4)) Convert an empty string to NULL in a derived column as varchar: TRIM(<TextColumn>) == ""
? (DT_STR, 4, 1252)NULL(DT_STR, 4, 1252) : <TextColumn> Replace an integer column with NULL if
the value is negative: (<IntegerColumn> < 0) ?
NULL(DT_I4) : <IntegerColumn> Replace an double column with NULL if the
value is negative: (<DoubleColumn> < 0) ?
NULL(DT_NUMERIC,3,2) : <DoubleColumn> Replace a date column with NULL if the
value is »in the future«: (<DateColumn> > GETDATE()) ?
NULL(DT_DATE) : <DateColumn> LEFT(<string>,
<number-of-chars>) A shorthand way of writing SUBSTRING(<string>,
1, <number-of-chars>) TOKEN(<string>, <delimiter>,
N) Returns the Nth token in <string> when it is split by
<delimiter> TOKENCOUNT(<string>,
<delimiter>) Returns the total number of tokens in <string> as
determined by <delimiter> TOKEN(,,) will be particularly useful
when manually parsing columns from a flat file. When used in conjunction with TOKENCOUNT
it can be used to return the last token in a string like so: TOKEN(<TextColumn>, ",", TOKENCOUNT(<TextColumn>,
",") ) Compare
with a string use " around the text like: @[User::Name] == "Paris"
in a 'Conditional
Split'.
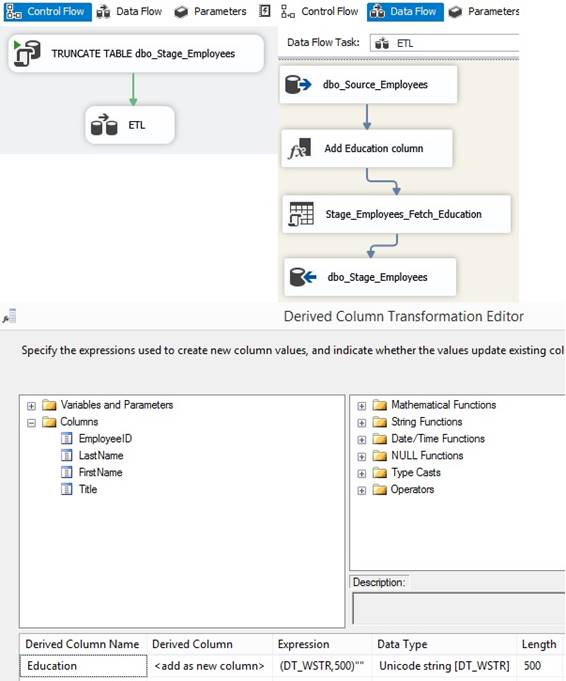
Use [ ] around a column that contains space or start with a digit. Inside Data Flow Task the Derived Column do the manipulation
of data When
data from a OLE DB Source goes to a pipeline the columns can be derived to
new columns with new column name that exists in table of OLE DB Destination, or
the columns values can be replaced by cleansing rule expression together with
? condition (if-then-else) and cast to get the right data type and length of
text, here is some examples:
Expression:
'Discount != 0 ? (DT_BOOL)1 : (DT_BOOL)0' means when the pipeline column
Discount has a value different from 0, a new column in the pipeline called
DiscountStatus with datetype bit (DT_BOOL in SSIS) is assigned value 1 = true
else value 0 = false and saved into a column in the table of 'OLE DB
Destination'. (DT_BOOL)([Discount]
== "Y" ? 1 : 0) has the advantage of automatically setting the data
type of the derived column correctly. Expression:
'Quantity > 0 && Quantity < 50 ? Quantity : NULL(DT_I2)' means when
the pipeline column Quantity has a value between 1 and 49, the value will be
passed through, but if the column value is less than or equal to 0 or greater
than or equal to 50 it will be replaced to a null value because theses values
is wrong from the source system and can give wrong summary and average in a
data warehouse reporting. The
new columns NumberOfAbroad and NumberOfDomestic will get value 1 or 0 depends
of the business logic rule of column Place and since a sql statement, column
in a report or a measure in a cube will do a summary and total of NumberOf,
it is important that the derived column has the right data type that will
cover the range of the total value, therefore I cast value 1 and 0 to DT_I4
that is int data type in the table of OLE DB Destination. The
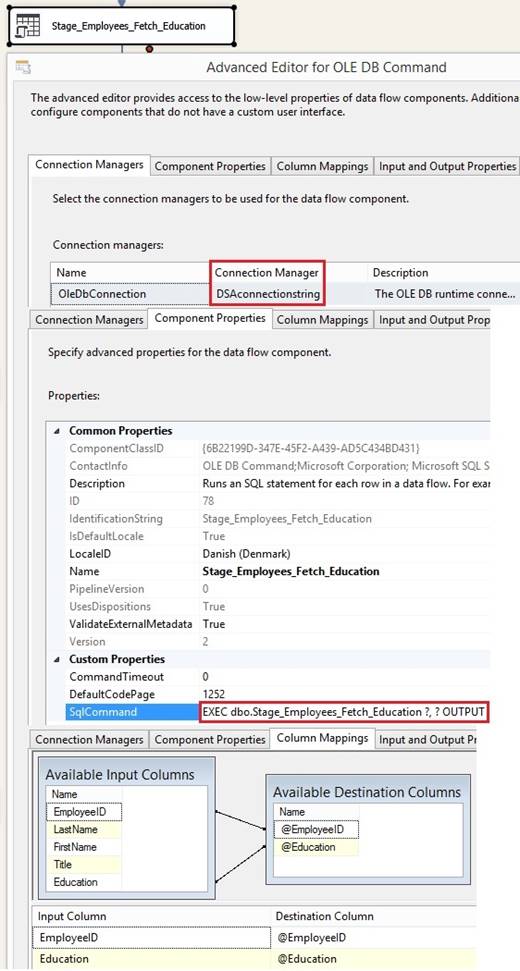
SSIS package has a int32 variable called Batchnumber and the variable has
been assigned a value in the 'Control Flow'. The variable value can be added
to the pipeline inside the 'Derived Column Transformation' with this syntax
notation: @[User::Batchnumber] and saved into a column in the table of 'OLE
DB Destination'. By
Edit the 'OLE DB Destination' I can click New button and typein a good table
name to be created automatically when I click OK, so I will change the [OLE
DB Destination] to table name like [Stage_OrderDetails], and the pipeline
will map the columns from the source table and from the derived columns to
the new destination table columns:
The
new table will allow null in all columns and that can be good for a source
input table therefore normally there is no need for check at 'Check
constraints' above. Cast
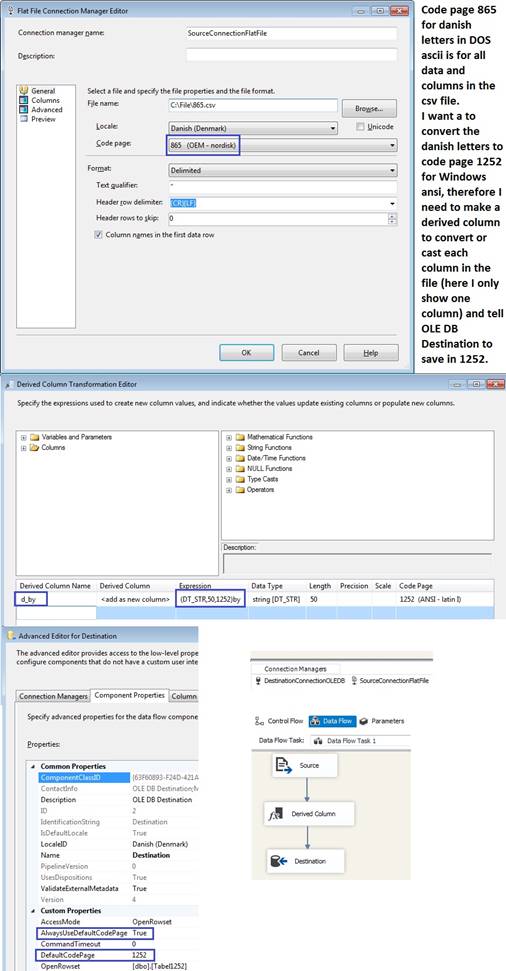
or convert danish letter from code page 865 DOS ASCII to code page 1252
Windows ANSI to a varchar column Cannot be processed because more
than one code page means, that data in OLE DB Destination is using a
different codepage than 1252. Here is an example to cast or convert between
code pages, here I am using: DT_STR(50, 1252) as a cast in front of the
column name, important in derived column to make a new column in the
pipeline, like this where the column name is »by« meaning city:
When column is an unicode with nvarchar(50) use then
(DT_WSTR,50). 4.
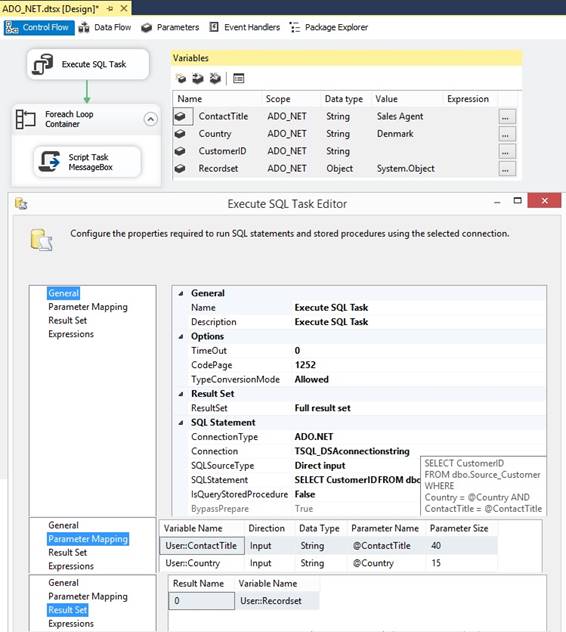
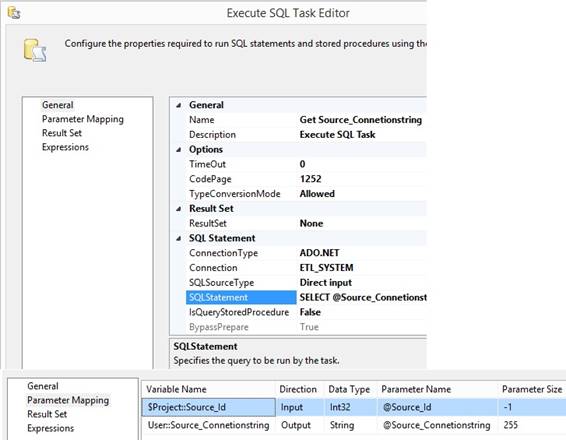
Execute SQL Task to assign a variable to use in Control Flow A SQL statement will query a
database table and will only return one row and the two columns will be
assigned to two SSIS package variables: SELECT StatusId, StatusDateTime
-- int and datetime FROM dbo.STATUS WHERE Status = 0 In a SSIS package in Control Flow I
rightclick the canvas and select {Variables} and in the window I click the
small left side button [Add Variable] to insert a new row and type in the
variable name and data type where sql int is a package Int32. Since my sql
statement has two columns I also make two variables with a default value, but
the default value will be override by the value from the sql statement:
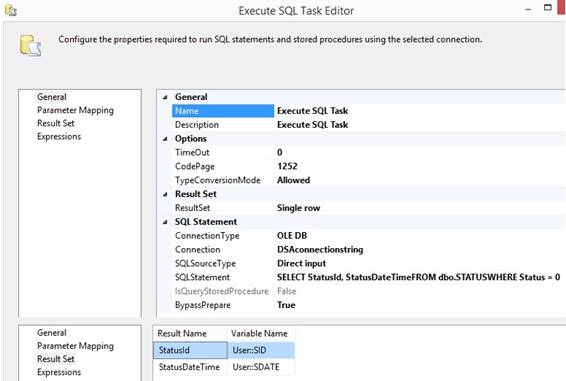
In Control Flow I drag in a 'Execute
SQL Task' and I edit it and choose a Connection and type in the sql statement
at the property SQLStatement. I set property ResultSet to 'Single row' and
at the page 'Result Set', I click the [Add] button and override 'NewResultName'
with the first column name or just 0 for first column and 1 for second
column. I also choose the right package variable:
To test if the assignment of the two
variable has been done, I drag in a 'Script Task':
I edit it 'Script Task' and at
property ReadOnlyVariables I click the […] and checkmark the two package
user variables I like to use later inside the script. I click at [Edit Script]
button and typein a MessageBox line above the Success line like this: MessageBox.Show(Dts.Variables["User::SID"].Value.ToString()
+ "
- " + Dts.Variables["User::SDATE"].Value.ToString()); Dts.TaskResult
= (int)ScriptResults.Success; I start the package and see the
messagebox showing the values from the row in the status table in the
database. When the sql statement does not
return a row, an error occurred while assigning a value to variable: "Single
Row result set is specified, but no rows were returned." Therefore I
need to extend the sql statement so it will always return a row and I will
make a stop constraint so Control Flow goes to another script. In 'Execute SQL Task' I change the
sql statement to control if there is a row and if the exists become false I
create a row with default values for the two columns: IF EXISTS(SELECT 1 FROM
dbo.STATUS WHERE Status
= 0) SELECT StatusId, StatusDateTime FROM dbo.STATUS WHERE Status
= 0 ELSE SELECT 0 AS StatusId, '1900-01-01 00:00:00' AS
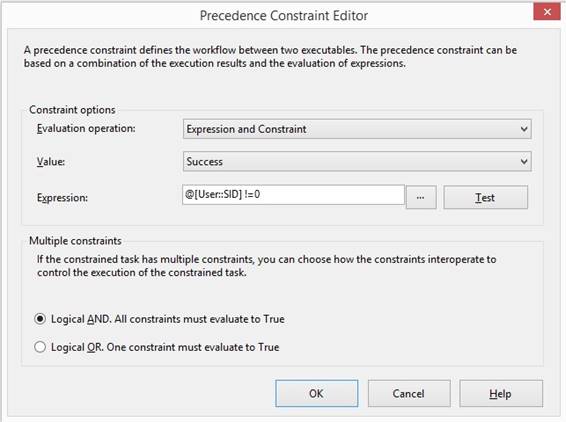
StatusDateTime I edit the green 'Precedence
constraint'
arrow
between 'Execute
SQL Task' and 'Script Task',
because I can extend the constraint with an logical boolean expression, so I
change 'Evaluation
operation'
from "Constraint" to "Expression and Constraint". In the expression I’m using
the SID variable with a C# notation for comparison for equivalent:
@[User::SID] != 0
A fx logo is shown at the green 'Precedence
constraint'
arrow
telling there is an expression included in the criteria for successful and continuation.
When the sql statement does not
return a row the 'Precedence constraint' will not continue and
the SSIS package does not failed. But if I want the 'Control Flow' to
continue, I drag in another 'Script Task', rename it to 'No Row' and typein a
MessageBox "No row". I edit the green 'Precedence
constraint'
arrow
between 'Execute
SQL Task' and 'No row'
using: @[User::SID]
== 0
The 'Control Flow' will always
continue the task of the SSIS package and the two variables has a value that
can be used in the package later like in a 'Data Flow Task'. Assign
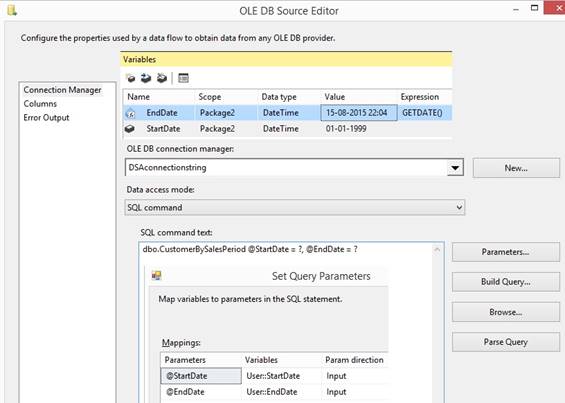
a datetime variable for fixed value
Drag in an 'Execute SQL Task' and at
edit then typein a sql statement to get the date and time from the SQL
Server, you can also use GETUTCDATE() for London time without summertime,
like this for normal local time with summertime: SELECT GETDATE() AS
CurrentDateTime Change ResultSet to 'Single row' and
select a Connection and at ResultSet page typein the columnname from the sql
statement and select the variable:
Then you can use the package
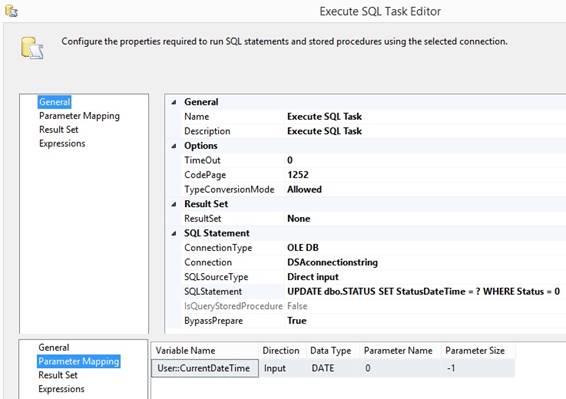
variable User::CurrentDateTime in a 'Script Task' MessageBox.Show(Dts.Variables["User::CurrentDateTime"].Value.ToString()); Then you can use the package
variable User::CurrentDateTime in a 'Execute SQL Task' as a input parameter
to make a dynamic sql statement in a where part or in a set part of a update
statement like this:
Please remark to use DATE as Date
Type for Input Direction, because OLE DB DATE do also cover a time as a datetime.
For Output Direction use a DBTIMESTAMP. If you typein an Expression for the variable in the
variables window like this:
the variable CurrentDateTime will change value each
time it is used, like it is execute the expression. Execute
SQL Task does not failed with no row In
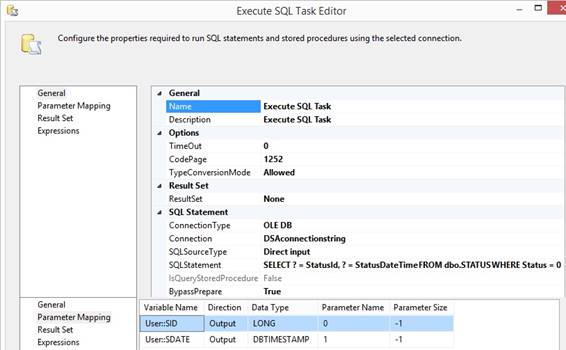
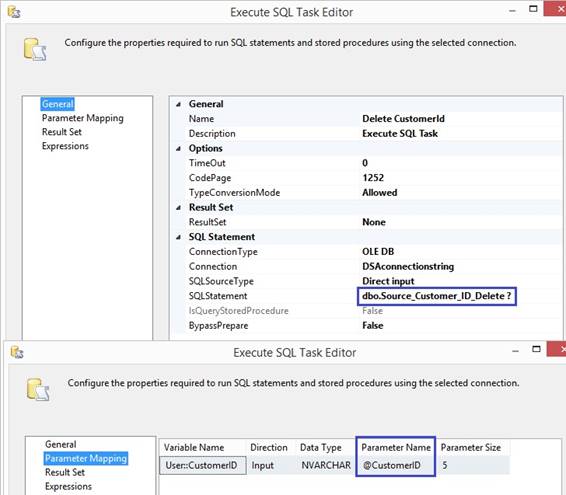
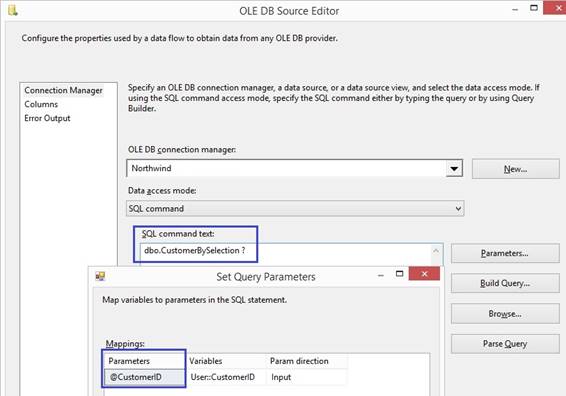
case you does not like the sql statement starting with IF EXISTS(SELECT 1 the 'Execute SQL Task' can be changed for using 'Parameter
Mapping' which means that the sql statement will have two output parameters
like this where question mark is a
output parameter: SELECT ? = StatusId, ? = StatusDateTime FROM dbo.STATUS WHERE Status = 0 Other examples: SELECT TOP 1 ? = CustomerId or SELECT
? = MAX(System_key) 'Parameter
Mapping' does not use property ResultSet, therefore I will set it to 'None'
and the 'Execute SQL Task' will not failed when there is no row. At
page 'Parameter Mapping' I connect each variable with each output
parameter where Parameter Name 0 is the first ? as StatusId and second ? is
StatusDateTime. The Data Type for the output or input parameter is OLE DB as
shown in chapter 3.
I
still keep the two 'Precedence constraint' green arrows so the 'Control
Flow' will do different tasks depending of a row or no row, because when
there is no row the 'Pameter Mapping' will assign the SID variable to value 0. Control
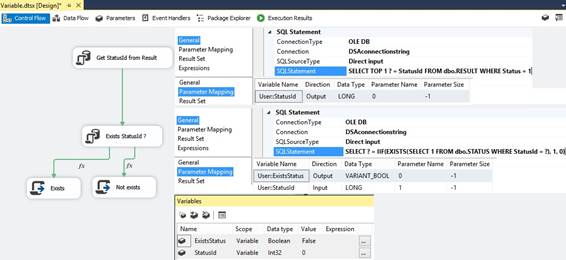
flow depends of exists a value in a table In a Result table I like to get a StatusId that has
a status as true and the StatusId I like to check if it exists in a Status
table. In a SSIS package I will use two 'Execute SQL Task' to get values
from the database tables into SSIS package variables and let one variable ExistsStatus
to control the flow by two fx expressions: @[User::ExistsStatus] == True // for Exists @[User::ExistsStatus] == False // for Not exists
Get StatusId from Result Variable @[User::StatusId] becomes the output
parameter for the question mark at left side of equal sign: SELECT TOP
1 ? = StatusId FROM dbo.RESULT WHERE Status = 1 In case there is no row then @[User::StatusId] get
value 0. Exists StatusId ? Variable @[User::ExistsStatus] becomes the output
parameter for the first question mark at left side of equal sign and variable
@[User::StatusId] becomes the input parameter of the second question mark at
the right side of the equal sign SELECT ? =
IIF(EXISTS( SELECT
1 FROM
dbo.STATUS WHERE
StatusId = ?),
1, 0) -- 1 = True, 0 = False Fx expressions The left fx is using the logical
expression: @[User::ExistsStatus] == True and when the condition is fulfilled
the left green 'Precedence constraint' will continue the
control flow. The right fx is using the logical
expression: @[User::ExistsStatus] == False and when the condition is fulfilled
the right green 'Precedence constraint' will continue the
control flow. Insert
into a table 'Execute
SQL Task' can do an insert into sql statement with input parameter: INSERT INTO
dbo.RESULT(StatusId, Status) VALUES(?,0) Update
of a table 'Execute
SQL Task' can do an update sql statement with two input parameters: UPDATE dbo.RESULT UPDATE
r SET Status = ? SET Status = ? WHERE StatusId = ? FROM dbo.RESULT r WHERE r.StatusId = ? Delete
in a table 'Execute
SQL Task' can do a delete sql statement with input parameter: DELETE FROM dbo.RESULT WHERE StatusId = ? Call stored
procedure to do update and get the result back I
like to update a column NumberOf for a specific OrderId and get the result
I
make the business logic in a stored procedure with two input parameter and
one output parameter with the result of the updating that is assigned
together with UPDATE sql statement: ALTER PROCEDURE
[dbo].[Order_NumberOf] (@OrderId
int, @Extra int, @NumberOf int OUTPUT) AS BEGIN BEGIN
TRANSACTION
UPDATE dbo.OrderNumber SET
@NumberOf = NumberOf =
NumberOf + @Extra WHERE
OrderId = @OrderId COMMIT
TRANSACTION
END
Dts.Variables["User::OrderId"].Value = 2; Dts.Variables["User::Extra"].Value = 3; Dts.TaskResult
= (int)ScriptResults.Success; MessageBox.Show(Dts.Variables["User::NumberOf"].Value.ToString()); Dts.TaskResult
= (int)ScriptResults.Success; After
running the SSIS package it will show in messagebox 23 and table look like:
Parameter Names must be a 0, 1, 2
and showing as ? parameter within same order. Named @parameter requires an ADO.NET
Connection. In case I do not like to do the two
package variable assignment in a 'Script Task', I can
replace it with two 'Expression Task's that do each package variable
assignment:
Read variable
values from a table to SSIS packages variable Table called SSIS_Variable has a row
for each variable with a datatype and a value:
A SSIS package has same variables
that will be assigned with the values from the table by a Script Task:
Assign variable has a C# program that
connect to the database and to the table and loop for each row and assign
each variable with the right data type: #region Namespaces using System; using System.Data; using
Microsoft.SqlServer.Dts.Runtime; using
System.Windows.Forms; //For
connection to SQL Server using
System.Data.SqlClient; using
Microsoft.SqlServer.Dts.Runtime; using
System.Text.RegularExpressions; #endregion namespace ST_cad614c72d4f4a1ab407b6cb5a7ec482 { [Microsoft.SqlServer.Dts.Tasks.ScriptTask. SSISScriptTaskEntryPointAttribute] public partial class ScriptMain :
Microsoft.SqlServer.Dts.Tasks. Script Task.VSTARTScriptObjectModelBase { public void Main() { try { //String connectionstring = "Server=<server>;Database=<db>; // Trusted_Connection=Yes;Connect
Timeout=30"; //Better using the Connection Manager from the
package to get connection: String connectionstring = Dts.Connections["DSAconnectionstring"].ConnectionString.ToString(); //Cleansing the connectionstring so it can
be used for SqlConnection below: Regex regProvider = new Regex("Provider=([^;]*);"); Regex regTranslate = new Regex("Auto
Translate=([^;]*);"); connectionstring =
regProvider.Replace(connectionstring, ""); connectionstring =
regTranslate.Replace(connectionstring, ""); SqlConnection connection = new SqlConnection(connectionstring); SqlCommand command = new SqlCommand(); SqlDataReader reader; command.Connection = connection; connection.Open(); command.CommandType = CommandType.Text; command.CommandText = "SELECT
Variable,Datatype,Value FROM dbo.SSIS_Variable"; reader = command.ExecuteReader(); if (reader.HasRows) { while (reader != null &&
reader.Read()) { //For debugging: //if
(reader["Variable"].ToString() == "Year") //{ //MessageBox.Show(reader["Variable"].ToString()+reader["Value"].ToString()); //} //For convert or parse to the
right data type for the package variables: switch (reader["Datatype"].ToString()) { case "Boolean": Dts.Variables[reader["Variable"]].Value = Boolean.Parse(reader["Value"].ToString()); break; case "DateTime": Dts.Variables[reader["Variable"]].Value = DateTime.Parse(reader["Value"].ToString()); break; case "Decimal": Dts.Variables[reader["Variable"]].Value = Decimal.Parse(reader["Value"].ToString()); break; case "Int32": Dts.Variables[reader["Variable"]].Value = Int32.Parse(reader["Value"].ToString()); break; default: //For String Dts.Variables[reader["Variable"]].Value =
reader["Value"].ToString(); break; } } } reader.Close(); reader.Dispose(); reader = null; command.Dispose(); command = null; connection.Close(); connection.Dispose(); connection = null; } catch(SqlException ex) { MessageBox.Show("No connection"); } Dts.TaskResult = (int)ScriptResults.Success; } } } Show
variable has
a C# program: public void Main() { MessageBox.Show(Dts.Variables["User::Year"].Value.ToString()); MessageBox.Show(Dts.Variables["User::Weight"].Value.ToString()); MessageBox.Show(Dts.Variables["User::EndDate"].Value.ToString()); MessageBox.Show(Dts.Variables["User::Type"].Value.ToString()); if ((bool)Dts.Variables["User::Summertime"].Value == true) MessageBox.Show("Summertime"); else MessageBox.Show("Wintertime"); Dts.TaskResult = (int)ScriptResults.Success; } Package parameter
in child package to be assigned from a parent package A SSIS package can be parameterized
like a stored procedure by using parameters that is places at the tab next to
Control Flow and Data Flow and parameters can also have a default value which
is useful under develop execute the package. The SSIS package parameter has Required
= True, meaning that the calling parent SSIS package need to provide a
parameter value to its child. In case the parent does not always has a
parameter value, Required should be set to False and then Value will be the
default parameter value. Inside a package I can use a
parameter like it was variable in an Expression Task or a Script Task where I
write like this: $Package::FromYearMonth. But a package parameter is a
readonly variable therefore it can not be assigned in an Expression Task like
this: @[$Package::FromYearMonth] =
201512 But a parameter can be used at the
right side of the equal sign like this:
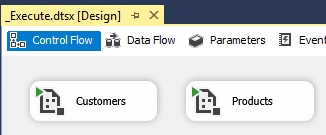
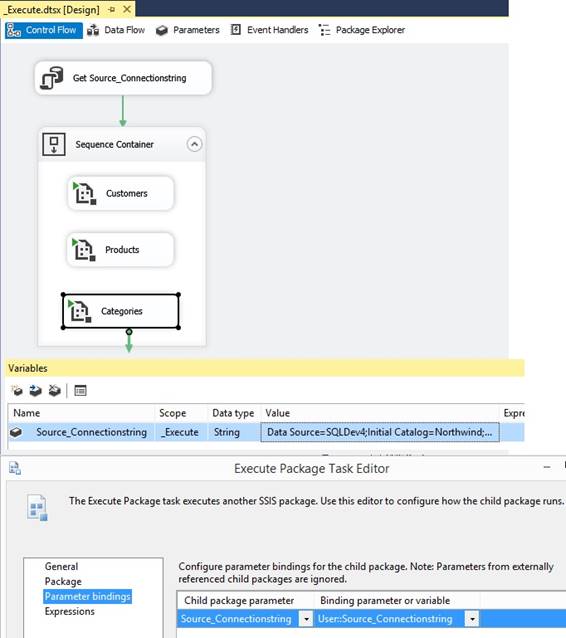
A SSIS package as a parent package when
it execute or call another SSIS package as a child package and pass by value
to the parameter through a 'Execute Package Task' like this:
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
5.
Control Flow, workflow in design mode and runtime mode When I open a SSIS package in design
mode for development, I like to see the control flow as it will be in
runtime mode, therefore I do not like a package to do dynamically disable 'Data
Flow Task' by expression fx mark at 'Data Flow Task' or by script task
programming to do disabling 'Data Flow Task' DFT. I like to use Precedence constraints
green arrow with expression fx to show the control flow or workflow of the
package in a self-explanatory graphical user interface perspective where the control
flow determine the order in which executables (tasks and containers) will run
and the control flow determines under what conditions they are executed. In
other words, certain executables will run only when a set of defined
conditions are met in an expression fx at precedence constraints green arrows. Setting Precedence Constraints on
Tasks and Containers for a linear or branching control flow like this where I
fetch two boolean values from a table into two packages variable and let them
with true/false do the runtime workflow:
·
Precedence
constraint green arrow has an expression,
showned by a fx logo. ·
Solid arrow meaning AND, that all
precedence constraints that point to the constrained executable must evaluate
to true in order for that executable to run. ·
Dotted arrow meaning OR, that only
one precedence constraint that points to the constrained executable must evaluate
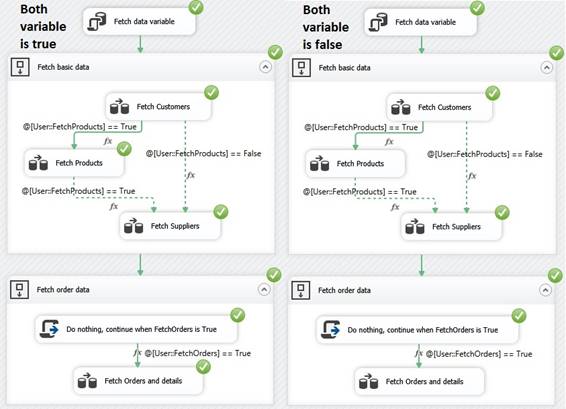
to true in order for that executable to run. In runtime mode
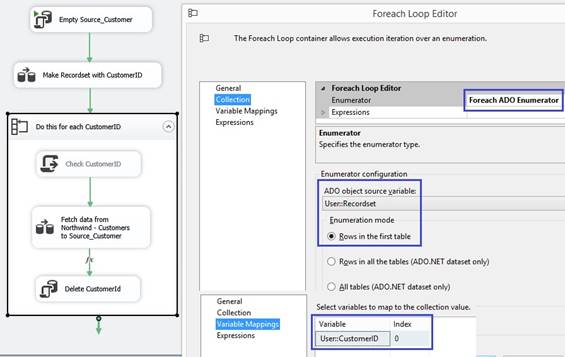
Fetch data variable I have made a table FetchData with
columns of bit data type to control the flow that will be fetch into two
packages variables through an 'Execute SQL Task':
From FetchCustomers to FetchProducts When the package variable FetchProducts
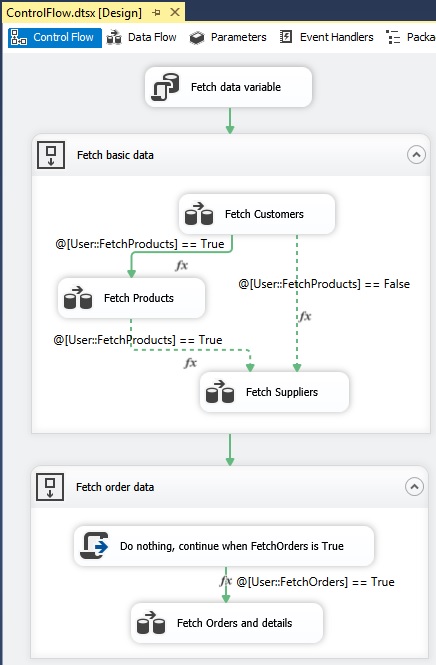
has value True from the table, the workflow will do FetchProducts. I connect the two tasks with a precedence
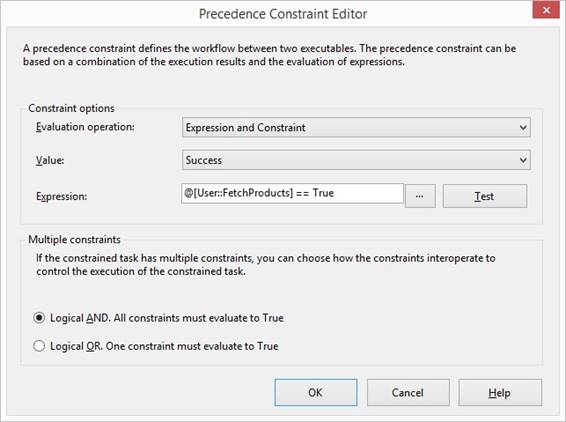
constraint green arrow and I right click at the arrow and select {Edit}, in
first dropdown I select 'Expression and Constraint' so both the Expression »@[User::FetchProducts]
== True« and Constraint of »FetchCustomers« must be true and success to
continue with FetchProducts task. I use default Logical AND and is giving a
solid arrow:
From FetchProducts to Fetch
Suppliers I do the same as above and I still
using Logical AND and get a solid arrow. From FetchCustomers to Fetch
Suppliers When the package variable FetchProducts
has value False from the table, the workflow will only do FetchSuppliers,
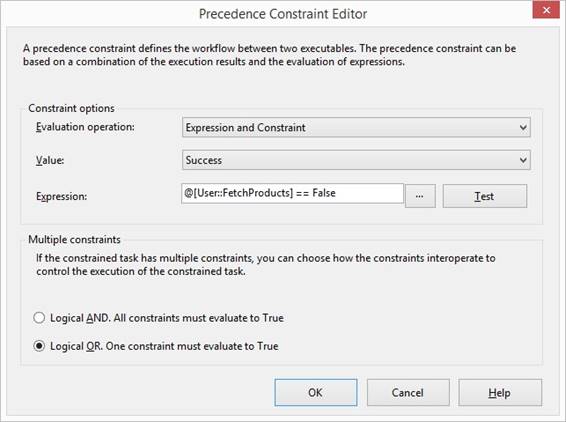
therefore the above path is shipped so no go for FetchProducts. I connect the two tasks with a precedence
constraint green arrow and I right click at the arrow and select {Edit}, in
first dropdown I select 'Expression and Constraint' so both the Expression »@[User::FetchProducts]
== False« and Constraint of »FetchCustomers« must be true and success to
continue with FetchProducts task. I use now Logical OR and is giving a dotted
arrow:
The solid arrow from FetchProducts
to Fetch Suppliers become dotted automatically to show in the self-explanatory
graphical user interface that Fetch Suppliers is only depends of either been
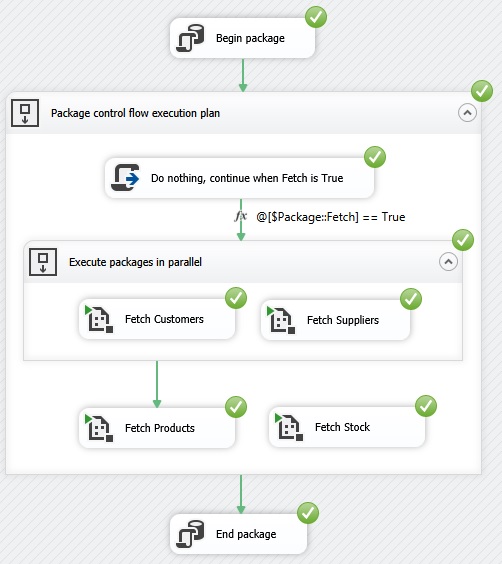
doing FetchProducts or FetchCustomers. To Fetch Orders and details / Do
nothing, continue when FetchOrders is True Task Fetch Orders and details will
only be done if the package variable FetchOrders has value true. To show this
in a self-explanatory graphical user interface perspective I am using an
empty 'Script Task' that has no variable and has no programming, and from 'Script
Task' to Fetch Orders and details I add this Expression: »@[User::FetchOrders]
== True« and no need for Constraint because 'Script Task' will never failure:
Do nothing,
continue when package parameter is True A SSIS package can receive a value
from another package through a parameter and then the package can control the
flow depends of value of parameter. An empty 'Script Task' »Do nothing,
continue when Fetch is True« has no variable and has no programming, it is
just placed there as a dummy object, so I can make a Precedence constraint green arrow that has an expression showned by a fx logo fx: @[$Package::Fetch] == True for programming a self-explanatory
graphical user interface of the control flow of the package like this:
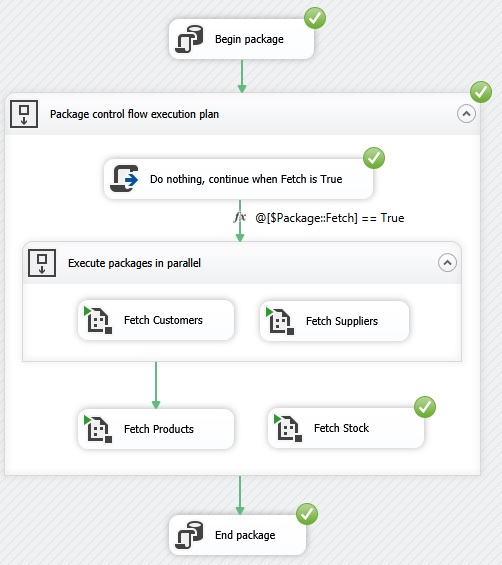
When
the fx expression condition is right/true, the
job will enter the 'Sequence Container'.
When
the fx expression condition is wrong/false, the
job will not enter the 'Sequence Container'.
Both 'Execute SQL Task' for »Begin
package« and »End package« for log registration will be done and »Fetch
Stock« will also be done because it is independent of the Fetch package
parameter. When a package variable or a package
parameter has data type Int32 and a default value as 0, the Expression for continuation
with the task can be like this: @[$Package::parameter] != 0 && !ISNULL(@[$Package:: parameter]) When a package variable or a package
parameter has data type String and a default value as 0000 (from nchar(4)
column in a table), the Expression for continuation with the task can be like
this: @[$Package::param]
!= "0000" && !ISNULL(@[$Package::param]) &&
@[$Package::param] != "" |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
6.
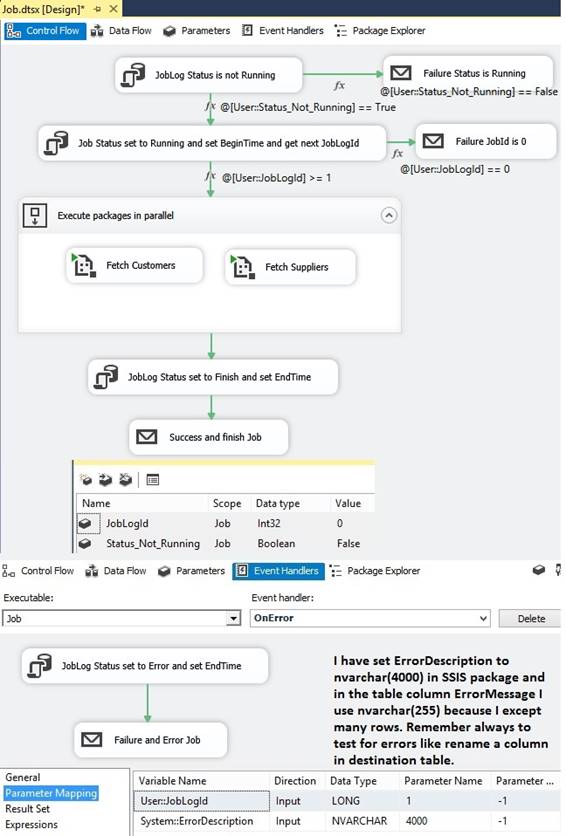
Package Job Log for raise and catch error failure When I have parents
and children packages, I like to wrap them all into one Job package with a
simple joblog table that take care of controlling that the job can not be
running two times at the same time and has few status state like 'Running',
'Finish' and 'Error'. To catch an error in the Job package or the below
parent and child package I will use Event Handlers that is a tab next to
Control Flow, Data Flow and Parameters. The main Job package can look like
this where I using fx expression to control the process flow:
A JobLog table has
some columns:
Execute SQL: JobLog
Status is not Running To control that the
job is not running or has status 'Running': SELECT ? = IIF(EXISTS(SELECT 1 FROM dbo.JobLog WHERE Status = 'Running'), 0, 1) and set package
variable Status_Not_Running to output value True or False. fx: @[User::Status_Not_Running]
== True to continue the job control flow. fx:
@[User::Status_Not_Running] == False to send a failure email cos Running. Execute SQL: Job
Status set to Running and set BeginTime and get next JobLogId To insert a new row in
JobLog and fetch the next JobLogId from Identity number and set Status to 'Running'
and set BeginTime datetimestamp: BEGIN TRANSACTION DECLARE @InsertedRow TABLE (JobLogId int) INSERT INTO dbo.JobLog (Status, BeginTime) OUTPUT inserted.JobLogId INTO
@InsertedRow VALUES ('Running', Getdate()) SELECT ? = JobLogId FROM @InsertedRow COMMIT TRANSACTION and set package
variable JobLogId to output value. fx: @[User::JobLogId]
>= 1 to continue the job control flow. fx: @[User::JobLogId]
== 0 to send a failure email cos no new JobLogId. Sequence Container: Execute
packages in parallel The Sequence Container
execute multiple packages in parallelism at same time. Execute SQL: JobLog
Status set to Finish and set EndTime To update the new row
in JobLog and set Status to 'Finish' and set EndTime: BEGIN TRANSACTION UPDATE dbo.JobLog SET Status = 'Finish', EndTime = Getdate() WHERE JobLogId = ? COMMIT TRANSACTION with package variable JobLogId
as input value. Event
Handlers I click at tab Event
Handlers, and in left dropdown I select the name of the package that
represent package level scope for the event. In right dropdown I select 'OnError'
to catch an error in the process or children packages. To get a canvas or design
surface to drag in SSIS components, I click at line link: Click here to create an
'OnError' event handler The canvas will become
dark gray and I can drag in an 'Execute SQL Task' or copy one from 'Control
Flow' tab: Execute SQL: JobLog
Status set to Error and set EndTime To update the new row
in JobLog and set Status to 'Error' and set EndTime and get system error
message from the package: BEGIN TRANSACTION UPDATE dbo.JobLog SET Status = 'Error', EndTime = Getdate(), ErrorMessage
= ? WHERE JobLogId = ? COMMIT TRANSACTION with package variable JobLogId
as input value and the first ? parameter with index 0 to system variable as
input for System::ErrorDescription shown in picture before. Event Handlers has
many properties like OnPreExecute and OnPostExecute that can do things before
and after the package process. Of course the Event
Handlers can also be placed in each parent and child packages to fetch a
better System::ErrorDescription message to be register in JobLog. Beside System::ErrorDescription
is System::SourceName, System::TaskName and System::EventHandlerStartTime (ErrorTime)
to other columns in JobLog table. A SQL Server Agent Job
will in case of a failure be red with a message 'The step failed' when the
Job package raise an error. Great tip Using an event handler
OnPreExecute or OnPostExecute in SSIS to log execution data into a audit job
execute table, an event can be fired multiple times in SSIS, but we want it
to be fire only once. Add this to the event handler:
@[System::PackageName]
!= @[System::SourceName]
Every time SSIS
package like to call the event handler, the Disable property expression is
evaluated and will become true therefore the event handler is disabled.
SourceName is the executable that raised the event and when that is the
PackageName, which we are interessing in, the expression becomes false,
meaning disable becomes false, meaning event handler becomes enabled and will
execute the canvas. Normally I do not add the above tip to the OnError Event
Handler. Catch an error – alternative to OnError A Sequence Container
can be used for many different tasks, and in case you like to catch error
failure inside the Sequence Container it can be done like this:
The database SSISDB
has views to show data about the SSIS package execution: SELECT E.execution_id, E.project_name, E.package_name, S.start_time, S.end_time, S.execution_result FROM
[SSISDB].[catalog].[executions] E JOIN
[SSISDB].[catalog].[executables] EX ON E.execution_id = EX.execution_id JOIN
[SSISDB].[catalog].[executable_statistics] S ON E.execution_id = S.execution_id SSIS error
codes in daily running is because of a bad connection at the server, that
often is solved by it self: 0x80004005 or 0xC0202009. |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
7.
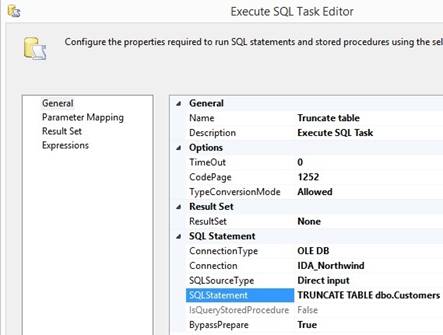
Execute T-SQL Statement Task At Control Flow drag in 'Execute
T-SQL Statement Task' and rightclick {Edit} and click [New] when first time
using in a project. Call the connection TSQL<databasename> and typein
SQL Server name (or use . or localhost). Typein a sql statement like a
UPDATE, DELETE, TRUNCATE, EXEC stored procedure or a dummy like »print
'hello'«. A new connection is shown in the buttom of the package at
Connection Managers and it is a new connection because this
task is using ADO.NET connection manager type with '.Net Providers\SqlClient
Data Provider'.
Rightclick the TSQL connection and choose {Convert to Project Connection}. In
Solution Explorer open the connection and select a database for the sql
statement else the database name has to be part of the statement FROM
<database>.dbo.<table>. Back in package rightclick the TSQL
connection {Parameterise} then the connection string becomes a project
parameter, the value in the dialogbox only needs to be: Data
Source=<server>;Initial Catalog=<database>;Integrated
Security=True;Connect Timeout=30; Remember to click [Save All] and the
parameter can be map to an Environment variable in SSISDB catalog. I can go
back now and typein the right sql statement. A project will have two connections
to the same database for Data Flow Task and for Execute T-SQL Statement Task. 8.
Kimball SCD type 7 dimension I will show a way to implement type
7 dimension in a SSIS package fetching data from a source table from a source
system to be stored in a dimension table with ten metadata columns that
support type 7, that is an extension of type 1 and type 2 plus handling
deleted values. There is an example in my article Dimensional
modeling that is good to read before programming the package that will
perform the ETL process from source to dimension. In case you don’t like the Previous reference
_pkey column in the dimension table from the article, you can skip the _pkey
column in the table and SSIS package implementation, because I will in
the end of this tip show an alternative sql update without _pkey. For my self
I have nice usage of the _pkey column in fetching from a dimension. The two table structures for this
example: CREATE TABLE [dbo].[Source_System] ([Id] [int] NOT NULL,
-- Business
key in source system therefore primary key here. [Name] [nvarchar](50)
NULL, [Version] [decimal](5,
2) NULL, CONSTRAINT
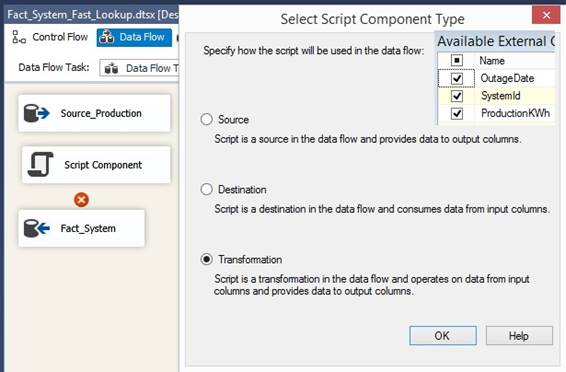
[PK_Source_System] PRIMARY KEY CLUSTERED ([Id] ASC) ) ON [PRIMARY] GO CREATE TABLE [dbo].[Dim_System] ([System_key] [int] IDENTITY(1,1) NOT NULL, [System_dkey] [int] NOT
NULL, [System_pkey] [int] NOT
NULL, [System_bkey] [int] NOT
NULL, [System] [nvarchar](50)
NULL, [Version] [decimal](5,
2) NULL, [ValidFrom] [datetime]
NOT NULL, [ValidTo] [datetime]
NOT NULL, [IsCurrent] [bit] NOT
NULL, [IsDeleted] [bit] NOT
NULL, [InsertTime] [datetime]
NOT NULL, [UpdateTime] [datetime]
NOT NULL, CONSTRAINT
[PK_Dim_System] PRIMARY KEY CLUSTERED ([System_key] ASC) ) ON [PRIMARY] GO CREATE NONCLUSTERED INDEX [IX_Dim_System_bkey] ON
[dbo].[Dim_System] ([System_bkey] ASC) ON [PRIMARY] GO CREATE NONCLUSTERED INDEX [IX_Dim_System_dkey] ON
[dbo].[Dim_System] ([System_dkey] ASC) ON [PRIMARY] GO CREATE NONCLUSTERED INDEX [IX_Dim_System_pkey] ON
[dbo].[Dim_System] ([System_pkey] ASC) ON [PRIMARY] GO Remark: datetime2(n) has a date
range of 0001-01-01 through 9999-12-31 while datetime starts from 1753-01-01.
datetime takes 8 bytes in storage size. datetime2 takes 6 bytes for
precisions less than 3; 7 bytes for precisions 3 and 4 else 8 bytes. datetime2(3) has same precision as
datetime. smalldatetime has a date range of 1900-01-01 through 2079-06-06 and
00 second in the timepart and takes 4 bytes in storage size and I could use
»the forever date« like 2070-12-31. I choose datetime and let ValidFrom
default at 1900-01-01 and ValidTo default at 9999-12-31. The source system does not provide
any datetime column when data is valid from or any status flag for New,
Created, Changed, Updated or Deleted data, therefore the SSIS package has to
do the data detection of New, Changed or Deleted data in the source system
and reflect it to the dimension table. In the SSIS package I’m not using 'OLE
DB Command' instead the sql update of metadata columns in previous rows will
be done by a sql statements that don’t need variable therefore I’m placing
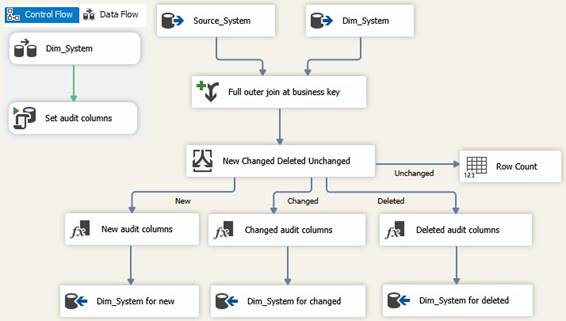
them in 'Execute T-SQL Statement Task' to get the best performance. Based on full load from source. I use 'Data Flow Task', 'Execute
T-SQL Statement Task', 'OLE DB Source', 'Merge Join', 'Conditional Split', 'Derived
Column' and 'OLE DB Destination' in flow of data from a source system from
table Source_System to a type 7 dimension table Dim_Source in a datamart:
I will make a SSIS package where
data in a Source_System table will do a Kimball SCD type 7 at a Dim_System
table. From Source_System table package will do data detection of :
The package will insert row from
Source_System table into Dim_System table together with metadata columns. The
package will end up with updating rows in table Dim_System to set _dkey
column and other metadata columns. Since the metadata columns will use
default values, I can either typein the default values for each metadata
columns in the table design of Dim_System, or I can make them as parameters
and variables for the SSIS project and the SSIS package like this:
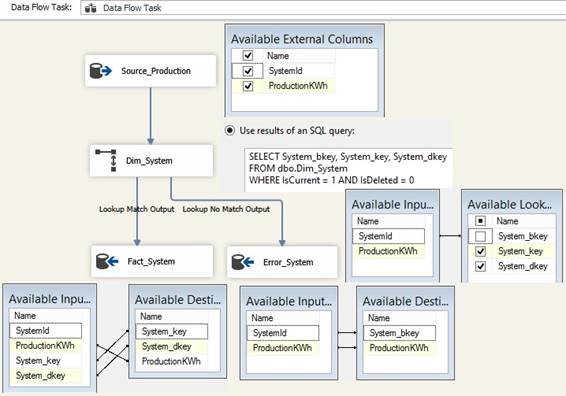
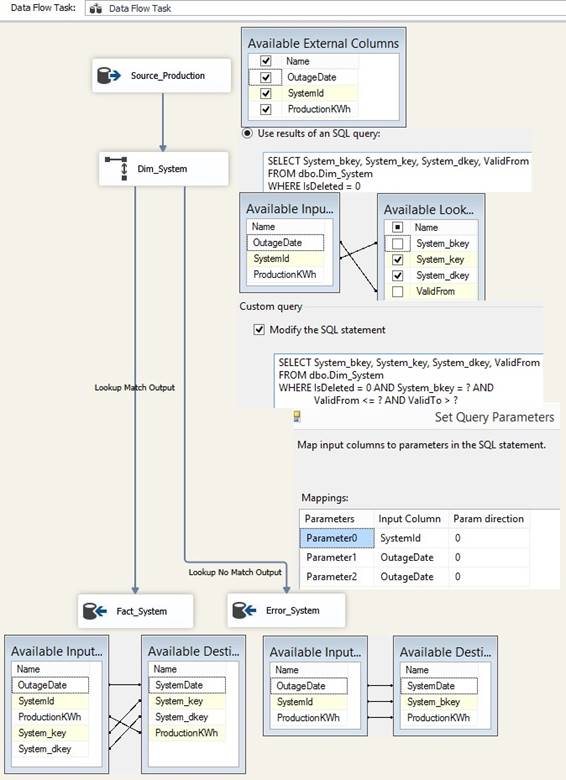
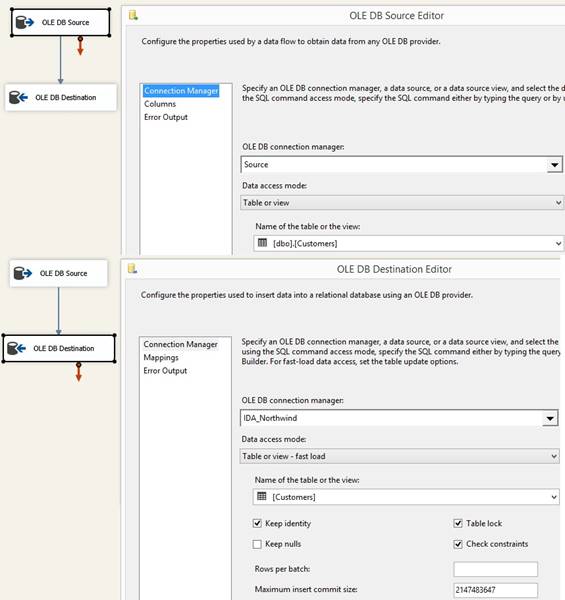
In 'Control Flow' I drag in a 'Data
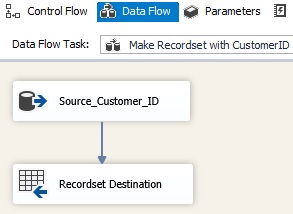
Flow Task' and inside I drag in two 'Source' for tables Source_System and
Dim_System with sql statements to make sure that data has the right sortorder
for a later of 'Merge Join' that will join over the business keys therefore
order by business keys in both sql statements where I only include the
columns the package need, like this:
When sql statement takes data from
an archive there will be a WHERE Active = 1. Since both 'Source' tables are using
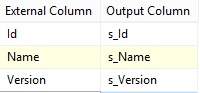
same column name, I will rename the columns of the Source_System table by
Edit the 'Source', go to Columns page and typein a prefix s_ to the output
columns like this:
At both 'Source' rightclick {Show
Advanced Editor}, tab 'Input and Output Properties', click at 'OLE DB Source
Output' and set property IsSorted to True and open
'OLE DB Source Output' and open 'Output Columns' and select the first column
from ORDER BY and set property SortKeyPosition to 1, see previous tip about
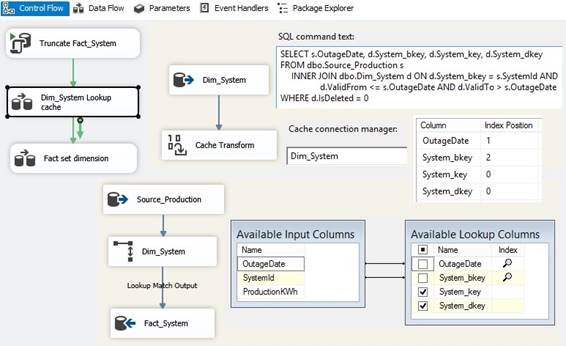
this. Drag in 'Merge Join' and connect the
two 'Source' tables as 'Merge Join Left Input' but in real I want a 'Full
outer join' because it will give me all rows from both 'Source' and Dimension
table, and both business keys will be null if there is no match. I include
all columns from both tables because:
I rightclick {Edit} and select join
type 'Full outer join' and select all columns:
Full outer join merge two datasets and
return all rows from both datasets into a new result dataset. 'Full outer join' will provide data
for four situations called:
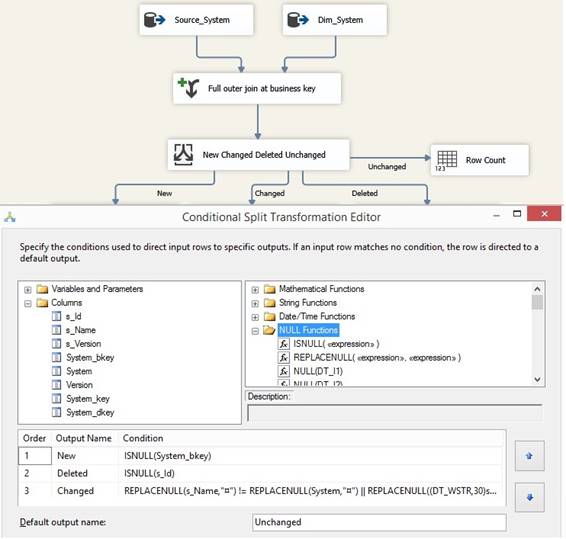
I will devide or filtering data to
each own pipeline through a 'Conditional Split' with three conditions using
the business key and the columns of values from source table (prefix s_) and
dimension table.
The order (rank) of rules is
important else Changed must starts with a condition to make sure that both
business keys has a value and therefore exists in both tables: !ISNULL(System_bkey)
&& !ISNULL(s_Id) && (<rule as above>).
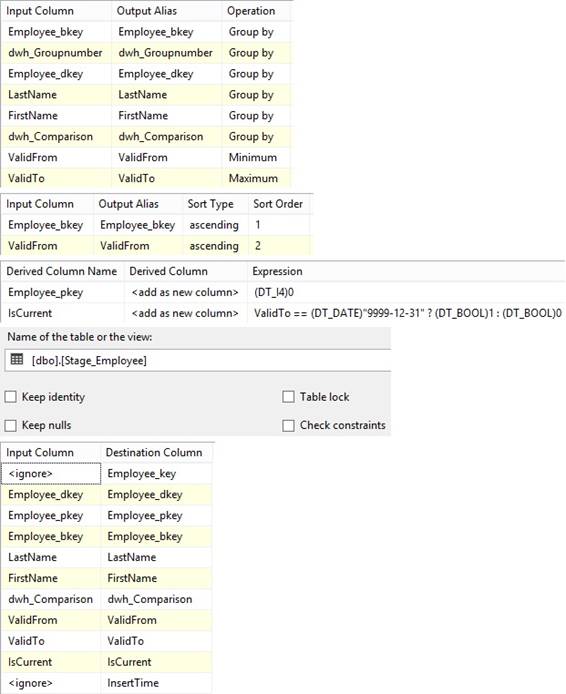
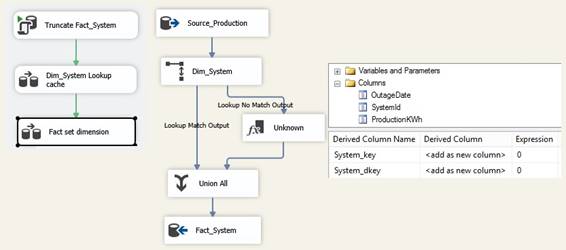
New
pipeline
will insert new rows into Dim_System table, therefore the package has to set
default values for metadata columns using the project parameters and package
variable. I do it in a 'Derived Column' that will add extra columns to the
New pipeline with a default value typein as an Expression refering to
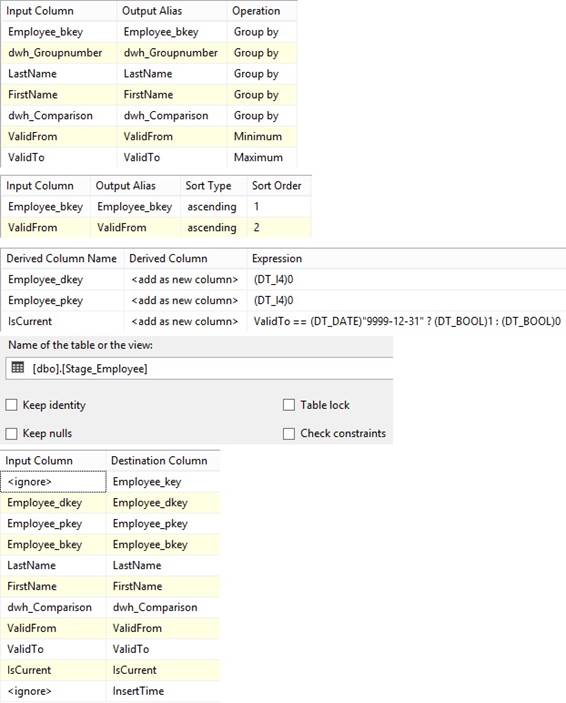
parameters and variable. ValidFrom is set to its general »begindate« because
the data is new in Dim_System table and ValidTo is set to its general enddata
called »forever enddate«. Sometimes the source system provides ValidFrom
when the data was been new/created/born inside the system:
I don’t like a metadata column to be
Null or n/a, therefore UpdateTime gets the same datetime stamp as InsertTime,
so both columns has the same value until data in the row will be either
changed or deleted in the source system.
The New pipeline with metadata
columns default values can now be insert into Dim_System table, I drag in a
'Destination' and connect new pipeline to it and select Dim_Source table as
fast load. There is a default mapping that match columns with same name
because the pipeline contains columns from both tables Source_System and
Dim_System after the full outer join:
But the source columns (left side) has
prefix s_ and they need to be map to the right columns in destination table
for Dim_System (right side), so I rearrange the mapping:
Metadata columns System_dkey and System_pkey
for the new rows will be set to the right value in a sql update statement in
the end of the ETL process. After I have deleted the map lines
and drag new map lines I rearrange the mapping, where I can’t use the input
distination columns because data is new in the source and therefore is Null
in the new pipeline so all the metadata columns comes from the default values
to be insert into Dim_System table as new rows:
Metadata column System_dkey
will be set to the value of System_key in a sql update statement in the end
of the ETL process, because System_key is an Identity sequential number that
first get its value after the row has been inserted. Then System_dkey will inherited
the number, so in the first row both columns has the same number. When the
data later will be changed or deleted, it become a new row in Dim_System
table with a new number in System_key and metadata column System_pkey will
have a value as previous reference back to the number of System_key for the
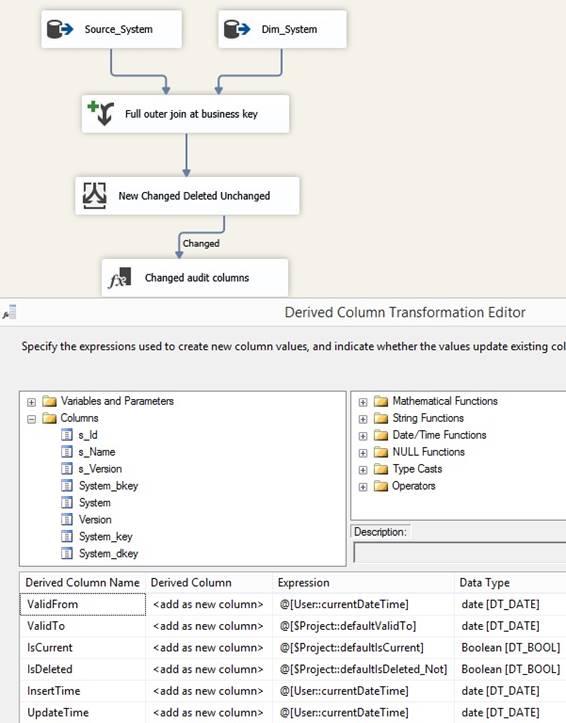
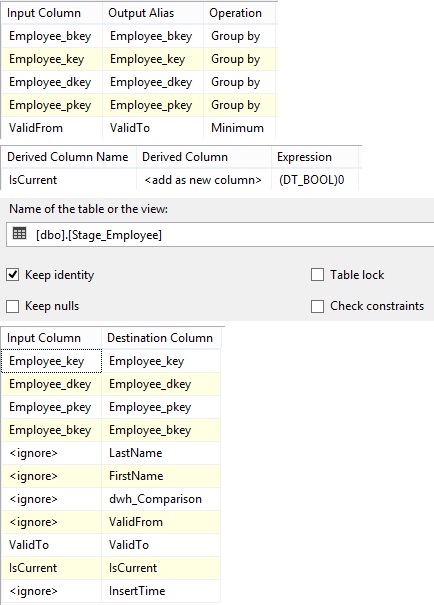
previous row before data was changed or deleted. Changed pipeline will insert new rows
into Dim_System table, therefore the package has to set default values for
metadata columns through 'Derived Column' where ValidFrom is set to
currentdatetime because that is the time where Dim_System receive a changed
data from Source_System. Sometimes the source system provides ValidFrom when
the data was been changed/updated inside the system, can be called Date of
change.
Metadata columns System_dkey and System_pkey
will inherited the values from the existing rows in Dim_System table.
The Changed pipeline with metadata
columns default values can now be insert into Dim_System table, I drag in a
'Destination' and connect changed pipeline to it and select Dim_Source table
as fast load. I rearrange the mapping:
Metadata columns ValidTo, IsCurrent
and UpdateTime for the old previous rows will be set to the right value in a
sql update statement in the end of the ETL process. Deleted pipeline will insert new rows
into Dim_System table, therefore the package has to set default values for
metadata columns through 'Derived Column' where ValidFrom is set to
currentdatetime because that is the time where Dim_System found out that data
has been deleted in the Source_System. Sometimes the source system provides
ValidFrom via a Date of change when the data was been deleted inside the system.
The new row will be mark with IsDeleted = 1 = true because the row represent
the deleted data in the source system, therefore I use another parameter
default value here:
Metadata columns System_dkey and System_pkey
will inherited the values from the existing rows in Dim_System table.
The Deleted pipeline with metadata
columns default values can now be insert into Dim_System table, I drag in a
'Destination' and connect deleted pipeline to it and select Dim_Source table
as fast load. I rearrange the mapping, where I can’t use the prefix s_
columns because data has been deleted in the source and therefore is Null in
the deleted pipeline:
Metadata columns ValidTo, IsCurrent
and UpdateTime for the old previous rows will be set to the right value in a
sql update statement in the end of the ETL process. Metadata
columns The SSIS package control flow is
ending with a TSQL statement that has two sql update statements.
UPDATE d SET System_dkey =
d.System_key FROM dbo.Dim_System d WHERE d.System_key > 0
AND d.System_dkey = 0
* Set ValidTo to same datetimestamp that new
row got in ValidFrom. * Set IsCurrent = 0 = false because it is
new row that is current row. * Set UpdateTime to the current datetime
when previous row was updated. The
sql statement is using a self-join
between the new row with alias n and the previous row in the dimension with
alias d with joining from new row column System_pkey to previous row column
System_key where both has IsCurrent = 1 to fetch the new row and the last
previous row and not older historical rows, but then the updating will set IsCurrent
= 0 for the previous row, therefore there will be only one row with IsCurrent
= 1 per data value: UPDATE d SET ValidTo = n.ValidFrom,
IsCurrent = 0, UpdateTime = Getdate() FROM dbo.Dim_System d
INNER JOIN dbo.Dim_System n ON n.System_pkey = d.System_key WHERE d.System_key > 0
AND n.IsCurrent = 1 AND d.IsCurrent = 1 In case you don’t like to
use the Previous reference _pkey metadata column in a dimension table, the
second sql update statement will use System_dkey to perform the self-join together
with two extra conditions that new row System_key must be greater than
previous row System_key to avoid a row joining to itself: UPDATE d SET ValidTo = n.ValidFrom,
IsCurrent = 0, UpdateTime = Getdate() FROM dbo.Dim_System d INNER JOIN dbo.Dim_System n ON
n.System_dkey = d.System_dkey AND n.System_key >
d.System_key WHERE d.System_key > 0
AND n.IsCurrent = 1 AND d.IsCurrent = 1
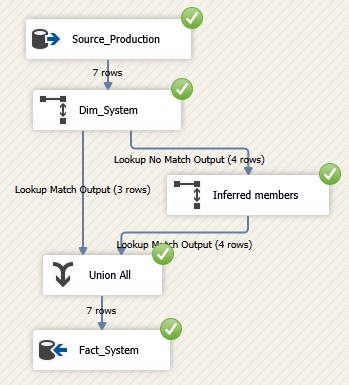
The SSIS package is ready to be
testet. Approaches
for writing to the dimension table The approach above starts with
inserting the rows into the dimension table and hereafter updating the
metadata columns. Another approach would be using a staging table which
contains changed and deleted data and a ValidFrom column that is assigned
inside the staging table, and hereafter the ValidFrom will be used to update
the previous rows ValidTo column in the dimension table together with the
other metadata columns, and hereafter inserting the rows from the staging
table into the dimension table. Merge
in T-SQL The process can also be solve by
T-SQL programming with INSERT INTO and UPDATE or with a MERGE but it needs
two updates afterwards like this where Target is table Dim_System and Source
is table Source_System where Merge compare business key between source and
target. Remarks that (ISNULL(Source.Name,'¤')
<> ISNULL(Target.System,'¤') is not working for Merge when a value
change to null. Based on full load from source. |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
DECLARE @defaultdkey int = 0 DECLARE @defaultpkey int = 0 DECLARE @defaultIsCurrent bit
= 1 DECLARE @defaultIsDeleted bit
= 1 DECLARE @defaultIsDeleted_Not bit
= 0 DECLARE @defaultIsInferred bit
= 0 DECLARE @defaultValidFrom datetime
= '1900-01-01
00:00:00' DECLARE @defaultValidTo datetime
= '9999-12-31 00:00:00' DECLARE @currentDateTime datetime
= GETDATE() -- IdaInsertTime or Date of Change from source INSERT INTO dbo.Dim_System -- Insert rows for updated and deleted data into Target
table (System_bkey, [System],
[Version], System_dkey, System_pkey, ValidFrom, ValidTo, IsCurrent, IsDeleted, IsInferred,
InsertTime, UpdateTime) SELECT System_bkey, [Name], [Version],
System_dkey, System_key, @currentDateTime, @defaultValidTo, @defaultIsCurrent,
@defaultIsDeleted_Not, @defaultIsInferred, @currentDateTime, @currentDateTime FROM – the columns in select comes from output
action columns, System_key is for System_pkey ( MERGE dbo.Dim_System AS [Target] USING (SELECT [Id], [Name], [Version] FROM
dbo.Source_System)
AS [Source] ON [Target].System_bkey
= [Source].Id WHEN NOT MATCHED BY TARGET -- Insert rows for new data
into Target table THEN INSERT (System_bkey,
[System], [Version],
System_dkey, System_pkey, ValidFrom,
ValidTo, IsCurrent,
IsDeleted, IsInferred, InsertTime, UpdateTime) VALUES ([Source].[Id], [Source].[Name], [Source].[Version], @defaultdkey,
@defaultpkey, @defaultValidFrom, @defaultValidTo,
@defaultIsCurrent, @defaultIsDeleted_Not, @defaultIsInferred, @currentDateTime, @currentDateTime) WHEN MATCHED AND [Target].IsCurrent
= 1 AND
[Target].IsDeleted =
0 AND ((([Target].[System] <> [Source].[Name]) OR ([Target].[System] IS NOT NULL AND
[Source].[Name] IS
NULL) OR ([Target].[System] IS NULL AND [Source].[Name] IS NOT NULL)) OR (([Target].[Version] <>
[Source].[Version])
OR ([Target].[Version]
IS NOT NULL AND
[Source].[Version] IS
NULL) OR ([Target].[Version] IS NULL AND
[Source].[Version] IS
NOT NULL))) -- Update rows
in Target table because rows is not current anymore because Source change
value THEN UPDATE SET
ValidTo = @currentDateTime, IsCurrent = 0, UpdateTime =
@currentDateTime WHEN NOT MATCHED BY SOURCE AND [Target].IsCurrent
= 1 AND
[Target].IsDeleted =
0 AND [Target].IsInferred = 0 -- Update rows
in Target table because rows has been deleted in Source table. THEN
UPDATE SET
ValidTo = @currentDateTime, IsCurrent = 0, UpdateTime =
@currentDateTime -- The updated
rows in Target become output and inserted as new rows in Target via INSERT
INTO OUTPUT $Action AS ActionOutput,
inserted.System_key,
inserted.System_bkey,
inserted.System_dkey, [Source].[Name], [Source].[Version] ) AS MergeOutput WHERE
MergeOutput.ActionOutput = 'UPDATE' -- For the new rows in Target set System_dkey as
same value as the given Identify for System_key UPDATE d SET System_dkey = d.System_key FROM dbo.Dim_System d WHERE d.System_key > 0 AND d.System_dkey = 0 -- For the new rows in Target that is deleted set
IsDeleted and fetch values from previous row UPDATE d SET IsDeleted =
@defaultIsDeleted, [System] = p.[System], [Version] = p.[Version] FROM dbo.Dim_System d INNER
JOIN dbo.Dim_System
p ON p.System_key
= d.System_pkey WHERE d.System_key > 0 AND d.IsCurrent = 1 AND d.IsDeleted = 0 AND d.[System] IS NULL AND d.[Version] IS NULL MERGE is most for
insert new data and update existing data as in Kimball type 1. For Kimball
type 2 and type 7 that wants to insert a new current row, merge has an OUTPUT
commando to fetch these rows and an INSERT INTO statement around the MERGE
statement, so the rows will be inserted into Target table as new rows
inclusive a new row when data do not exists in source. Insert
and Update instead of Merge in T-SQL stored procedure Based on full load from source. CREATE PROCEDURE [dbo].[DimensionT7_InsertUpdate] AS BEGIN SET NOCOUNT ON DECLARE @defaultValidFrom datetime
= '1900-01-01
00:00:00' DECLARE @defaultValidTo datetime = '9999-12-31 00:00:00' DECLARE @currentDateTime datetime = GETDATE() -- IdaInsertTime or
Date of Change from source DECLARE @New_ROW_COUNT
int =
0 DECLARE @Deleted_ROW_COUNT int
= 0 DECLARE @Changed_ROW_COUNT int
= 0 -- I am using a @table_variable instead of a #temporary_table
or a real_stage_table inside db or -- a memory optimized table. I have added primary
key index on the columns I will join to later. DECLARE @NewRows TABLE (System_key int NOT NULL PRIMARY KEY CLUSTERED) DECLARE @DeletedRows TABLE (System_key int, System_dkey int, System_bkey int, System
nvarchar(50), Version decimal(5, 2)) DECLARE @ChangedRows TABLE (System_key int, System_dkey int, System_bkey int NOT NULL PRIMARY KEY CLUSTERED) -- bkey is not in dimension, therefore row is new in
source, that will be marked as current row. INSERT INTO dbo.Dim_System (System_bkey, System, Version, System_dkey,
System_pkey, ValidFrom, ValidTo, IsCurrent, IsDeleted,
InsertTime, UpdateTime) OUTPUT inserted.System_key
INTO @NewRows SELECT DISTINCT s.Id, s.Name, s.Version, 0, 0, @defaultValidFrom, @defaultValidTo,
1, 0, @currentDateTime, @currentDateTime FROM dbo.Source_System s WHERE NOT EXISTS(SELECT 1 FROM dbo.Dim_System
d WHERE d.System_bkey
= s.Id) SET
@New_ROW_COUNT = @New_ROW_COUNT + @@ROWCOUNT /* For new rows to set System_dkey as same value as
the given Identify for System_key. */ UPDATE d SET System_dkey = d.System_key FROM dbo.Dim_System d INNER
JOIN @NewRows n ON
n.System_key =
d.System_key /* bkey is not in source, therefore the row is
deleted in source, that will be marked in dimension
in current row and an extra row is inserted. */ UPDATE d SET IsCurrent = 0, ValidTo =
@currentDateTime, UpdateTime = @currentDateTime OUTPUT inserted.System_key, inserted.System_dkey, inserted.System_bkey, inserted.System, inserted.Version INTO
@DeletedRows FROM dbo.Dim_System d WHERE d.System_key > 0 AND d.IsCurrent = 1 AND d.IsDeleted = 0 AND NOT
EXISTS(SELECT
1 FROM dbo.Source_System
s WHERE s.Id = d.System_bkey) INSERT INTO dbo.Dim_System (System_bkey,
System, Version, System_dkey, System_pkey,
ValidFrom, ValidTo, IsCurrent,
IsDeleted, InsertTime,
UpdateTime) SELECT DISTINCT d.System_bkey, d.System, d.Version, d.System_dkey, d.System_key, @currentDateTime, @defaultValidTo,
1, 1,
@currentDateTime, @currentDateTime FROM @DeletedRows d --FROM dbo.Dim_System d --WHERE d.IsCurrent = 0 AND d.IsDeleted = 0 AND
d.ValidTo = @currentDateTime AND -- NOT
EXISTS(SELECT 1 FROM dbo.Source_System s WHERE s.Id = d.System_bkey) SET
@Deleted_ROW_COUNT = @Deleted_ROW_COUNT + @@ROWCOUNT /* bkey is marked deleted in dimension but exists
now again in source, reappearing, that will be marked in
dimension in current/deleted row and an extra row is inserted. Keep
IsDeleted = 1 to show it was deleted in a period. */ UPDATE d SET IsCurrent = 0, ValidTo =
@currentDateTime, UpdateTime = @currentDateTime OUTPUT inserted.System_key, inserted.System_dkey, inserted.System_bkey
INTO @ChangedRows FROM dbo.Dim_System d INNER
JOIN dbo.Source_System
s ON s.Id = d.System_bkey WHERE d.IsCurrent = 1 AND d.IsDeleted = 1 /* bkey's values is changed in source, that will be
marked in dimension in current row and an extra row is inserted. */ UPDATE d SET IsCurrent = 0, ValidTo =
@currentDateTime, UpdateTime = @currentDateTime OUTPUT inserted.System_key, inserted.System_dkey, inserted.System_bkey
INTO @ChangedRows FROM dbo.Dim_System d INNER
JOIN dbo.Source_System
s ON s.Id = d.System_bkey WHERE d.IsCurrent = 1 AND d.IsDeleted = 0 AND (ISNULL(s.Name,'¤') <> ISNULL(d.System, '¤') OR ISNULL(s.Version,0) <> ISNULL(d.Version, 0)) --
d.dwh_Comparison != s.dwh_Comparison INSERT INTO dbo.Dim_System (System_bkey, System, Version, System_dkey,
System_pkey, ValidFrom, ValidTo, IsCurrent, IsDeleted,
InsertTime, UpdateTime) SELECT DISTINCT s.Id, s.Name, s.Version, c.System_dkey, c.System_key, @currentDateTime, @defaultValidTo,
1, 0,
@currentDateTime, @currentDateTime FROM dbo.Source_System s INNER
JOIN @ChangedRows c ON
c.System_bkey =
s.Id --WHERE NOT EXISTS(SELECT 1 FROM dbo.Dim_System d
WHERE d.System_bkey = s.Id AND d.IsCurrent = 1) --Because source table contains rows that has not
been changed and must be skipped in the ETL. SET
@Changed_ROW_COUNT = @Changed_ROW_COUNT + @@ROWCOUNT END |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
9.
Lookup, Cache Connection Manager Transform, Data Viewer In case the ETL process needs to do
two or more lookups to same table or sql statement by adding the same
Lookup in several Data Flow Tasks, data will be reloaded which can cost
performance. Instead data can be loaded one time and added to a cache and multiple
Lookup can use same cache. Lookup is a join between two tables
in a one-to-many relationship, from a many-table to a one-table for adding
extra columns to the pipeline build on many-table.
10.
Kimball SCD type 7 dimension through DSA layer It is nice to have a Data Staging
Area (DSA) layer in the ETL process between Source data and a dimension like
type 7 from Kimball. A very strict ETL flow is first to have all data ready
at DSA layer before start to update and insert data in dimensions and facts.
Instead of compare columns if values has changed I make a checksum hashbytes
column called dwh_Comparison that contains the compared columns which is the normal
columns and not included the primary key (business key). 10.1
Using Lookup For a new employee I let ValidFrom
start from 1900-01-01 and for the current row I let ValidTo stop at
9999-12-31. Dim_Employee
From the source system the ETL fetch
employees as full dump (delta data see 10.3) with an Updated_Time column that
I will use for ValidFrom and ValidTo because the HR people is used to do ad
hoc queries in the source system. Therefore the source will give 5 employees Source_Employees
2 employees has changed last name
(ID = 125 Janet and 126 Margaret) and 1 new employee (ID = 127 Steven) has
started. ETL process to a Stage_Employee
table in a self-explanatory graphical user interface where I use Lookup to
devide into existing employees (match output) and new employees (no match
output) and I use a Conditional Split to only continue with changed employees
where I compare the values in dwh_Comparison. The changed rows will be added
two times in the stage and later in the dimension because of the ValidFrom
and ValidTo, therefore I use a Multicast to copy the pipeline and save the
rows with different metadata columns values. The data flow from source to
stage table:
Multicast do a duplicate for Update
and Insert of the pipeline of changed rows. The »2 rows« is from Janet and Margaret
that has created new key numbers, the »2 rows« is key 3 and 4 from existing
row in dimension and the »1 rows« is from Steven that will be new member in
the dimension. Stage_Employee (order by bkey +
ValidFrom)
Key 3 and 4 rows is for update same
rows in the dimension where ValidTo and IsCurrent will be changed, therefore
no need for names in these rows. The same business keys is repeated in key 6
and 7 rows for insert into the dimension with the new names. Key 5 is the new
employee ready to be inserted into dimension. So the SSIS package has made the
staging data ready to be launched into the dimension and that should be done
in another SSIS packages that can do it parallel for all dimensions and facts
from DSA to DMA a data mart. 2 rows updated with a new ValidTo from the
source with 2014-10-09 and 3 new rows added because there was a new employee
too:
Dim_Employee (order by bkey +
ValidFrom)
Table Stage_Employee where some columns allow null value because these
values is not needed to update ValidTo in the dimension table, and _key is
an Identity to create the new key numbers for the dimension: CREATE TABLE [dbo].[Stage_Employee]( [Employee_key] [int] IDENTITY(1,1) NOT NULL, [Employee_dkey] [int] NOT NULL, [Employee_pkey] [int] NOT NULL, [Employee_bkey] [int] NOT NULL, [LastName] [nvarchar](20) NULL, [FirstName] [nvarchar](10) NULL, [dwh_Comparison] [binary](32) NULL, [ValidFrom] [datetime] NULL, [ValidTo] [datetime] NOT NULL, [IsCurrent] [bit] NOT NULL, [InsertTime] [datetime] NOT NULL CONSTRAINT [DF_Stage_Employee_InsertTime] DEFAULT (getdate()), CONSTRAINT
[PK_Stage_Employee] PRIMARY KEY CLUSTERED ([Employee_key] ASC) ) ON [PRIMARY] GO Employee_key is an
Identity because it will calculate the new numbers for the new rows, and
later the new rows will be inserted into dimension table Dim_Employee. Insert the Missing row into the dimension
table: TRUNCATE TABLE dbo.Dim_Employee -- SET IDENTITY_INSERT dbo.Dim_Employee ON INSERT INTO dbo.Dim_Employee (Employee_key,
Employee_dkey, Employee_pkey, Employee_bkey,
LastName, FirstName, dwh_Comparison, ValidFrom,
ValidTo, IsCurrent) VALUES (-1, -1, 0, 0, 'Missing', 'Missing', 0x0000000000000000000000000000000000000000000000000000000000000000, '1900-01-01', '9999-12-31', 1) -- SET IDENTITY_INSERT dbo.Dim_Employee OFF GO When I have a DSA layer and a staging table, there
is no need to have an Identity in dimension table Dim_Employee. Hash column
dwh_Comparison using HASHBYTES('SHA2_256') that become data type binary(32)
or char(64) and I just give the Missing a default value that never will come
from the source system. ETL
for staging table into DSA layer The Truncate Stage_Employee makes empty staging table and copy the max
key number value from the dimension table, so new inserted rows into staging
table will get new identity number that later can be bulk insert to
dimension: TRUNCATE TABLE dbo.Stage_Employee DECLARE @maxKey int SELECT @maxKey = ISNULL(MAX(Employee_key),0) + 1 FROM dbo.Dim_Employee DBCC CHECKIDENT (Stage_Employee,
RESEED, @maxKey)
The Source_Employees makes a comparison column for the columns to
compare with to the dimension, here FirstName and LastName is concatenate: SELECT EmployeeID, LastName, FirstName, Updated_Time, dwh_Comparison =
CAST(HASHBYTES('SHA2_256', CONCAT(UPPER(RTRIM(LTRIM(FirstName))), ';',UPPER(RTRIM(LTRIM(LastName))))) AS binary(32)) FROM dbo.Source_Employees The cast makes sure the default data type
binary(8000) is not used because that would take a lot of memory for the pipeline. Concat takes care of null value in column else
isnull(firstname, ''). The Dim_Employee makes a lookup to the dimension to fetch the key
columns and the comparison column for the current dimension rows: SELECT Employee_key, Employee_dkey, Employee_pkey, Employee_bkey, dwh_Comparison FROM dbo.Dim_Employee WHERE IsCurrent = 1
The Lookup No Match Output means that the business key from source
EmployeeID does not exists in the dimension. Derived Column extends the
pipeline with extra column values that will be inserted into the staging
table in Stage_Employee new rows with
new identity number values of the _key column:
The Lookup Match Output means that the business key from source
EmployeeID do exists in the dimension but then only continue with the rows
where source has changed FirstName or LastName by compare the comparison
column from source and dimension that was included in the Lookup in Find changed rows Conditional Split
with the criteria not to be equal:
A changed row meaning source has
updated FirstName or LastName will result in two rows in staging table, one
row for update ValidTo/IsCurrent=0 and one row for insert new row with
ValidFrom/IsCurrent=1, therefore a Multicast
double the pipeline. Derived Column extends the pipeline with extra column
values that will be inserted into the staging table in Stage_Employee existing rows but keep the identity number value
of the _key column for doing a sql update later by joine the _key columns,
and ValidTo gets its value from Updated_Time:
Stage_Employee
changed rows
with new identity number values of the _key and the _dkey gets the value from
the dimension from the Lookup above and the _pkey gets the value from the
dimension _key because _pkey is a reference back to previous row in the
dimension, it is made as a column copy in Derived Column, and ValidFrom gets
its value from Updated_Time:
The Stage_Employee set durable key update the _dkey for the new rows: UPDATE dbo.Stage_Employee
WITH(TABLOCK) SET Employee_dkey
= Employee_key WHERE IsCurrent = 1 AND
Employee_dkey = 0 ETL
from staging table in DSA layer into the dimension The Update Dim_Employee to set ValidTo/IsCurrent for the old current
row: UPDATE d SET ValidTo
=
s.ValidTo, IsCurrent
= s.IsCurrent, UpdateTime = Getdate() FROM dbo.Dim_Employee d WITH(TABLOCK) INNER
JOIN dbo.Stage_Employee
s WITH(TABLOCK) ON s.Employee_key = d.Employee_key WHERE s.IsCurrent = 0 The Insert Dim_Employee for insert new row with ValidFrom/IsCurrent=1
from Stage_Employee: SELECT Employee_key, Employee_dkey, Employee_pkey, Employee_bkey, LastName,
FirstName, dwh_Comparison, ValidFrom, ValidTo, IsCurrent FROM dbo.Stage_Employee WHERE IsCurrent = 1 Into table Dim_Employee:
A SSIS package for update and insert
data from staging tables to dimensions and fact tables can use BEGIN
TRANSACTION and COMMIT TRANSACTION or ROLLBACK TRANSACTION with failure to
secure that all will be loaded or nothing will happen. 10.2
Not using Lookup I think it is important to make a
SSIS package in a self-explanatory graphical user interface
way where the
Dim_Employee lookup and two
pipelines tells a lot. But with many rows in a dimension Lookup is slow and
use a lot of memory, therefore I can drop the Lookup and inside 'OLE DB
Source' Source_Employees I make a sql
that do a kind of lookup through Left Outer Join and it will perform inside
the database at SQL Server: ;WITH source AS ( SELECT
EmployeeID, LastName,
FirstName, Updated_Time, dwh_Comparison = CAST(HASHBYTES('SHA2_256', CONCAT(UPPER(RTRIM(LTRIM(FirstName))), ';',UPPER(RTRIM(LTRIM(LastName))))) AS binary(32)) FROM dbo.Source_Employees WITH(TABLOCK) ) SELECT s.EmployeeID, s.LastName, s.FirstName, s.Updated_Time, s.dwh_Comparison, d.Employee_key, d.Employee_dkey, d.Employee_pkey FROM source s LEFT
OUTER JOIN
dbo.Dim_Employee d WITH(TABLOCK) ON d.Employee_bkey = s.EmployeeID WHERE d.dwh_Comparison IS NULL OR (d.IsCurrent = 1 AND d.dwh_Comparison <>
s.dwh_Comparison) ·
Left
outer join + d.dwh_Comparison IS NULL fetchs new rows from source with a
business key that does not exist in the dimension, so all d. columns has null
value. ·
d.IsCurrent
= 1 AND d.dwh_Comparison <> s.dwh_Comparison fetchs changed rows from
source that does not compare to the current rows in the dimension. A Conditional Split has an output
called New for ISNULL(Employee_key) and the default output is called Changed.
The New pipeline is 'Lookup No Match Output' and the Changed pipeline goes to
'Multicast'. The data flow from source to stage table:
Multicast do a duplicate for Update
and Insert of the pipeline of changed rows. Here is only 3 rows coming out of Source_Employees
because 1 is new and 2 is changed, but as the first data flow shown there was
5 rows from source. There is always pros and cons to self-explanatory
graphical user interface and performance. 10.3
Source data into an Archive with repeating members The data warehouse fetchs source
data and add them all to the archive also when source gives revision of rows,
or rows that seams not to have been changed, I call it repeating members e.g.
Fullor in three rows: Archive_Employee
In the dimension Andrew’s name is
Fuller, but above there is a revision row with an unchanged name, later many
rows with changed name and the last change is back to the original name
Fuller. Buchanan is a new employee and the first row is a wrong typing of his
first name. »End Of The Day« for each data
revision in Archive is easy by select the max time of Updated_Time from the
source, but in this approach I will respect all the changes in the source
with these rules:
The result for a stage table in DSA
where ValidFrom and ValidTo is smashed and null key will be set by Identity.
The SQL that do the magic where dwh_Sortorder
take care of the last row of Fuller and dwh_Groupnumber take care of the
double change of Fullar and smashing the Fullor rows is done by using Min and
Max: ;WITH source AS ( SELECT
EmployeeID, LastName, FirstName,
Updated_Time, dwh_Sortorder =
ROW_NUMBER()
OVER(PARTITION BY EmployeeID
ORDER BY Updated_Time), dwh_Comparison =
CAST(HASHBYTES('SHA2_256', CONCAT(UPPER(RTRIM(LTRIM(FirstName))), ';',UPPER(RTRIM(LTRIM(LastName))))) AS binary(32)) FROM ARC.dbo.Archive_Employee WITH(TABLOCK) ), datarow AS ( SELECT
s.LastName, s.FirstName, s.dwh_Comparison, d.Employee_key, d.Employee_dkey, d.Employee_pkey, Employee_bkey = s.EmployeeID, ValidFrom = s.Updated_Time, ValidTo =
LEAD(s.Updated_Time, 1, '9999-12-31') OVER(PARTITION BY s.EmployeeID
ORDER BY
s.Updated_Time), dwh_Groupnumber = ( ROW_NUMBER() OVER(ORDER BY s.EmployeeID, s.Updated_Time) ) - ( ROW_NUMBER() OVER(PARTITION BY s.EmployeeID, s.dwh_Comparison ORDER BY s.Updated_Time) ) FROM
source s LEFT
OUTER JOIN
dbo.Dim_Employee d WITH(TABLOCK) ON d.Employee_bkey = s.EmployeeID WHERE
d.dwh_Comparison IS
NULL OR (d.IsCurrent = 1 AND (d.dwh_Comparison <> s.dwh_Comparison
OR (d.dwh_Comparison = s.dwh_Comparison AND s.dwh_Sortorder
<> 1))) ) -- New rows to insert into dimension repeating members
smash together timespan ValidFrom-To SELECT Employee_key = null, Employee_dkey =
0, Employee_pkey =
0, Employee_bkey,
LastName, FirstName,
dwh_Comparison, ValidFrom = MIN(ValidFrom),
ValidTo = MAX(ValidTo), IsCurrent = IIF(MAX(ValidTo) = '9999-12-31', 1, 0), Flag = 'New member for insert' FROM datarow WHERE Employee_key IS NULL GROUP BY Employee_bkey, dwh_Groupnumber,
LastName, FirstName,
dwh_Comparison UNION ALL -- Changed rows to update existing rows in dimension
set ValidTo=From IsCurrent=0 ValidFrom=null SELECT Employee_key,
Employee_dkey, Employee_pkey, Employee_bkey, LastName =
null, FirstName =
null, dwh_Comparison =
null, ValidFrom = null, ValidTo = MIN(ValidFrom), IsCurrent
= 0, Flag = 'Changed member for
update' FROM datarow WHERE Employee_key IS NOT NULL GROUP BY Employee_bkey, Employee_key, Employee_dkey, Employee_pkey UNION ALL -- Changed rows to insert into dimension repeating
members smash together timespan ValidFrom-To SELECT Employee_key = null, Employee_dkey,
Employee_pkey = 0,
Employee_bkey, LastName, FirstName,
dwh_Comparison, ValidFrom = MIN(ValidFrom),
ValidTo = MAX(ValidTo), IsCurrent = IIF(MAX(ValidTo) = '9999-12-31', 1, 0), Flag = 'Changed member for insert' FROM datarow WHERE Employee_key IS NOT NULL GROUP BY Employee_bkey, dwh_Groupnumber,
Employee_dkey, LastName, FirstName,
dwh_Comparison ORDER BY Employee_bkey, ValidFrom Of course the smashing of Min and
Max has no relevans if all rows are different i.e. when there is a Start
datetime column which is not used for ValidFrom/To. ETL
for staging table into DSA layer From the SQL I build this SSIS
package to fetch data from archive that is different compared to the
dimension and load data into the DSA stage table.
Multicast do a duplicate for Update
and Insert of the pipeline of changed rows. The »4 rows« is from Andrew that has
created new key numbers, the »1 rows« is key 2 from existing row in dimension
and the »2 rows« is from Buchanan that will be new in the dimension including
the wrong typing of his first name. Stage_Employee (order by bkey +
ValidFrom)
Truncate
Stage_Employee Empty staging table and copy the max
key number value from the dimension table, so new inserted rows into staging
table will get new identity number that later can be bulk insert to
dimension: TRUNCATE TABLE dbo.Stage_Employee DECLARE @maxKey int SELECT @maxKey = ISNULL(MAX(Employee_key),0) + 1 FROM dbo.Dim_Employee DBCC CHECKIDENT (Stage_Employee,
RESEED, @maxKey)
Match
Archive and Dimension To fetch data from Archive the 'OLE
DB Source' is using delta detection incremental load through a table Archive_DeltaDataDetection
that’s keep a datetime2(7) for the latest successfully load to EDW or Data
mart, e.g.
;WITH source AS ( SELECT EmployeeID, LastName, FirstName, Updated_Time, dwh_Sortorder = ROW_NUMBER() OVER(PARTITION BY EmployeeID ORDER
BY Updated_Time), dwh_Comparison = CAST(HASHBYTES('SHA2_256', CONCAT(UPPER(RTRIM(LTRIM(FirstName))),
';',UPPER(RTRIM(LTRIM(LastName))))) AS binary(32)) FROM
ARC.dbo.Archive_Employee WITH(TABLOCK) WHERE ARC_INSERT_TIME
> (SELECT
ARC_INSERT_TIME FROM dbo.Archive_DeltaDataDetection) ) SELECT s.LastName, s.FirstName, s.dwh_Comparison, d.Employee_key, d.Employee_dkey, d.Employee_pkey, Employee_bkey = s.EmployeeID, ValidFrom =
s.Updated_Time, ValidTo =
LEAD(s.Updated_Time, 1, '9999-12-31') OVER(PARTITION BY s.EmployeeID ORDER BY s.Updated_Time), dwh_Groupnumber = ( ROW_NUMBER() OVER(ORDER BY s.EmployeeID, s.Updated_Time) ) - ( ROW_NUMBER()
OVER(PARTITION BY s.EmployeeID, s.dwh_Comparison ORDER BY s.Updated_Time) ) FROM source s LEFT
OUTER JOIN
dbo.Dim_Employee d WITH(TABLOCK) ON d.Employee_bkey = s.EmployeeID WHERE d.dwh_Comparison IS NULL OR (d.IsCurrent = 1 AND (d.dwh_Comparison <>
s.dwh_Comparison OR (d.dwh_Comparison = s.dwh_Comparison AND s.dwh_Sortorder
<> 1))) ORDER BY s.EmployeeID, s.dwh_Sortorder When the ETL for DSA layer and EDW layer
or DMA layer is finished successfully, the Archive_DeltaDataDetection one row
will be changed to current datetime: UPDATE dbo.Archive_DeltaDataDetection SET ARC_INSERT_TIME = SYSDATETIME() Next time the ETL process begin, it
will fetch all the new data from archive since the last process. New -
Changed A Conditional Split has an output
called New for ISNULL(Employee_key) and the default output is called Changed.
New output
(N)
ValidTo ==
(DT_DATE)"9999-12-31" ? (DT_BOOL)1 : (DT_BOOL)0 Changed
output (U) – right multicast
Notes in Aggregate, it is minumum of
ValidFrom but it become output ValidTo as showned in the magic SQL statement. Changed
output (I) – left multicast
Set durable
key UPDATE s SET Employee_dkey = t.Employee_key FROM dbo.Stage_Employee
s WITH(TABLOCK) INNER
JOIN (SELECT
Employee_bkey, Employee_key = MIN(Employee_key) FROM
dbo.Stage_Employee WHERE Employee_dkey =
0 GROUP
BY Employee_bkey )
t ON t.Employee_bkey
= s.Employee_bkey
WHERE s.Employee_dkey = 0 Set
previous key UPDATE s SET Employee_pkey = t.Employee_pkey FROM dbo.Stage_Employee
s WITH(TABLOCK) INNER
JOIN (SELECT
Employee_key, Employee_pkey = LAG(Employee_key, 1, Employee_pkey) OVER(PARTITION BY Employee_bkey ORDER
BY ValidFrom) FROM
dbo.Stage_Employee )
t ON t.Employee_key
= s.Employee_key
WHERE s.ValidFrom IS NOT NULL ETL
from staging table in DSA layer into the dimension Almost the same as above, but now I
am using WHERE ValidFrom. The Update Dim_Employee to set
ValidTo/IsCurrent for the old current row: Update
Dim_Employee UPDATE d SET ValidTo
= s.ValidTo, IsCurrent = s.IsCurrent, UpdateTime =
Getdate() FROM dbo.Dim_Employee d WITH(TABLOCK) INNER JOIN dbo.Stage_Employee
s WITH(TABLOCK) ON s.Employee_key = d.Employee_key WHERE s.ValidFrom IS NULL Insert
Dim_Employee For new row with
ValidFrom/IsCurrent=1 from Stage_Employee: SELECT Employee_key,
Employee_dkey, Employee_pkey, Employee_bkey, LastName,
FirstName, dwh_Comparison, ValidFrom,
ValidTo, IsCurrent FROM dbo.Stage_Employee WHERE ValidFrom IS NOT NULL BIML to
generate multiple dimensions in multiple SSIS packages <Biml xmlns="http://schemas.varigence.com/biml.xsd"> <Connections> <OleDbConnection Name="DSA_DB" ConnectionString="Data Source=sqlservername;Initial
Catalog=DSA; Provider=SQLNCLI11.1;Integrated
Security=SSPI;Auto Translate=False;
Packet Size=32767; Application
Name=SSIS;" CreateInProject="true"/> <AdoNetConnection Name="DSA_ADO" ConnectionString="Data Source=sqlservername;Database=DSA; Integrated Security=SSPI;Connect
Timeout=30; Application Name=SSIS;" Provider="SQL" CreateInProject="true"/> </Connections> <Packages> <Package Name="Stage_Employee" ConstraintMode="Linear"> <Tasks> <ExecuteTSqlStatement Name="Empty Stage table" ConnectionName="DSA_ADO"> <SqlStatementSource> <![CDATA[ TRUNCATE TABLE dbo.Stage_Employee DECLARE @maxKey int SELECT @maxKey =
ISNULL(MAX(Employee_key),0) + 1 FROM dbo.Dim_Employee DBCC CHECKIDENT (Stage_Employee,
RESEED, @maxKey) ]]> </SqlStatementSource> </ExecuteTSqlStatement> <Dataflow Name="From Source to Stage"> <Transformations> <OleDbSource Name="Match Source and
Dimension" ConnectionName="DSA_DB"> <DirectInput> <![CDATA[ ;WITH s AS ( SELECT
-- Business key EmployeeID, -- Business columns LastName, FirstName, Updated_Time, dwh_Sortorder =
ROW_NUMBER() OVER(PARTITION BY EmployeeID ORDER BY Updated_Time), dwh_Comparison = CAST(HASHBYTES('SHA2_256',
CONCAT(UPPER(RTRIM(LTRIM(FirstName))), ';',UPPER(RTRIM(LTRIM(LastName)))))
AS binary(32))
-- Business columns above FROM ARC.dbo.Archive_Employee
WITH(TABLOCK) ) SELECT
-- Business columns s.LastName, s.FirstName, s.dwh_Comparison,
-- 5 x Business key d.Employee_key,
d.Employee_dkey, d.Employee_pkey, Employee_bkey = s.EmployeeID, ValidFrom = s.Updated_Time, ValidTo =
LEAD(s.Updated_Time, 1, '9999-12-31') OVER(PARTITION BY s.EmployeeID ORDER BY
s.Updated_Time), dwh_Groupnumber = (
ROW_NUMBER() OVER(ORDER BY s.EmployeeID, s.Updated_Time) ) – ( ROW_NUMBER()
OVER(PARTITION BY s.EmployeeID, s.dwh_Comparison ORDER BY s.Updated_Time) ) FROM s LEFT OUTER JOIN
dbo.Dim_Employee d WITH(TABLOCK) ON d.Employee_bkey = s.EmployeeID WHERE d.dwh_Comparison IS
NULL OR (d.IsCurrent = 1 AND (d.dwh_Comparison <> s.dwh_Comparison OR (d.dwh_Comparison = s.dwh_Comparison AND
s. dwh_Sortorder <> 1))) ORDER BY s.ID, s.dwh_Sortorder ]]> </DirectInput> </OleDbSource> <ConditionalSplit Name="New - Changed"> <InputPath OutputPathName="Match Source and
Dimension.Output"/> <OutputPaths> <OutputPath Name="New"> <Expression>ISNULL(Employee_key)</Expression> </OutputPath> <OutputPath Name="Changed"> <Expression>!ISNULL(Employee_key)</Expression> </OutputPath> </OutputPaths> </ConditionalSplit> <!--New pipeline (N) --> <Aggregate Name="Smash ValidFrom
ValidTo (N)"> <InputPath OutputPathName="New - Changed.New"/> <OutputPaths> <OutputPath Name="Output"> <Columns> <Column SourceColumn="Employee_bkey" Operation="GroupBy"/> <Column SourceColumn="dwh_Groupnumber" Operation="GroupBy"/> <Column SourceColumn="dwh_Comparison" Operation="GroupBy"/> <Column SourceColumn="ValidFrom" Operation="Minimum"/> <Column SourceColumn="ValidTo" Operation="Maximum"/> <!—Business columns --> <Column SourceColumn="LastName" Operation="GroupBy"/> <Column SourceColumn="FirstName" Operation="GroupBy"/> </Columns> </OutputPath> </OutputPaths> </Aggregate> <Sort Name="Businesskey +
ValidFrom (N)"> <InputPath OutputPathName="Smash ValidFrom ValidTo
(N).Output"/> <Columns> <Column Sort="true" SourceColumn="Employee_bkey"/> <Column Sort="true" SourceColumn="ValidFrom"/> </Columns> </Sort> <DerivedColumns Name="Set IsCurrent (N)"> <InputPath OutputPathName="Businesskey +
ValidFrom (N).Output"/> <Columns> <Column Name="Employee_dkey" DataType="Int32">(DT_I4)0</Column> <Column Name="Employee_pkey" DataType="Int32">(DT_I4)0</Column> <Column Name="IsCurrent" DataType="Boolean"> ValidTo ==
(DT_DATE)"9999-12-31" ? (DT_BOOL)1 : (DT_BOOL)0</Column> </Columns> </DerivedColumns> <OleDbDestination Name="Stage, new rows to
insert" ConnectionName="DSA_DB" UseFastLoadIfAvailable="true" TableLock="false" CheckConstraints="false" KeepIdentity="false" KeepNulls="false"> <InputPath OutputPathName="Set IsCurrent
(N).Output"/> <ExternalTableOutput Table="dbo.Stage_Employee"/> </OleDbDestination> <!--Changed pipeline --> <Multicast Name="Duplicate for Update
and Insert"> <InputPath OutputPathName="New -
Changed.Changed"/> <OutputPaths> <OutputPath Name="Update"/> <OutputPath Name="Insert"/> </OutputPaths> </Multicast> <!--Update pipeline (U) --> <Aggregate Name="Smash ValidTo (U)"> <InputPath OutputPathName="Duplicate for Update
and Insert.Update"/> <OutputPaths> <OutputPath Name="Output"> <Columns> <Column SourceColumn="Employee_bkey" Operation="GroupBy"/> <Column SourceColumn="Employee_key" Operation="GroupBy"/> <Column SourceColumn="Employee_dkey" Operation="GroupBy"/> <Column SourceColumn="Employee_pkey" Operation="GroupBy"/> <Column SourceColumn="ValidFrom" TargetColumn="ValidTo" Operation="Minimum"/> </Columns> </OutputPath> </OutputPaths> </Aggregate> <DerivedColumns Name="Set IsCurrent to 0
(U)"> <InputPath OutputPathName="Smash ValidTo
(U).Output"/> <Columns> <Column Name="IsCurrent" DataType="Boolean">(DT_BOOL)0</Column> </Columns> </DerivedColumns> <OleDbDestination Name="Stage, changed rows
to update" ConnectionName="DSA_DB" UseFastLoadIfAvailable="true" TableLock="false" CheckConstraints="false" KeepIdentity="true" KeepNulls="false"> <InputPath OutputPathName="Set IsCurrent to 0
(U).Output"/> <ExternalTableOutput Table="dbo.Stage_Employee"/> </OleDbDestination> <!--Insert pipeline (I) --> <Aggregate Name="Smash ValidFrom
ValidTo (I)"> <InputPath OutputPathName="Duplicate for Update
and Insert.Insert"/> <OutputPaths> <OutputPath Name="Output"> <Columns> <Column SourceColumn="Employee_bkey" Operation="GroupBy"/> <Column SourceColumn="dwh_Groupnumber" Operation="GroupBy"/> <Column SourceColumn="Employee_dkey" Operation="GroupBy"/> <Column SourceColumn="dwh_Comparison" Operation="GroupBy"/> <Column SourceColumn="ValidFrom" Operation="Minimum"/> <Column SourceColumn="ValidTo" Operation="Maximum"/> <!—Business columns --> <Column SourceColumn="LastName" Operation="GroupBy"/> <Column SourceColumn="FirstName" Operation="GroupBy"/> </Columns> </OutputPath> </OutputPaths> </Aggregate> <Sort Name="Businesskey + ValidFrom
(I)"> <InputPath OutputPathName="Smash ValidFrom
ValidTo (I).Output"/> <Columns> <Column Sort="true" SourceColumn="Employee_bkey"/> <Column Sort="true" SourceColumn="ValidFrom"/> </Columns> </Sort> <DerivedColumns Name="Set IsCurrent (I)"> <InputPath OutputPathName="Businesskey +
ValidFrom (I).Output"/> <Columns> <Column Name="Employee_pkey" DataType="Int32">(DT_I4)0</Column> <Column Name="IsCurrent" DataType="Boolean"> ValidTo ==
(DT_DATE)"9999-12-31" ? (DT_BOOL)1 : (DT_BOOL)0</Column> </Columns> </DerivedColumns> <OleDbDestination Name="Stage, changed rows
to insert" ConnectionName="DSA_DB" UseFastLoadIfAvailable="true" TableLock="false" CheckConstraints="false" KeepIdentity="false" KeepNulls="false"> <InputPath OutputPathName="Set IsCurrent
(I).Output"/> <ExternalTableOutput Table="dbo.Stage_Employee"/> </OleDbDestination> </Transformations> </Dataflow> <ExecuteTSqlStatement Name="Set durable key" ConnectionName="DSA_ADO"> <SqlStatementSource> <![CDATA[ UPDATE s SET Employee_dkey =
t.Employee_key FROM dbo.Stage_Employee s
WITH(TABLOCK) INNER JOIN (SELECT Employee_bkey,
Employee_key = MIN(Employee_key) FROM dbo.Stage_Employee WHERE Employee_dkey = 0 GROUP BY Employee_bkey ) t ON t.Employee_bkey =
s.Employee_bkey WHERE s.Employee_dkey = 0 ]]> </SqlStatementSource> </ExecuteTSqlStatement> <ExecuteTSqlStatement Name="Set previous key" ConnectionName="DSA_ADO"> <SqlStatementSource> <![CDATA[ UPDATE s SET Employee_pkey = t.Employee_pkey FROM dbo.Stage_Employee s
WITH(TABLOCK) INNER JOIN (SELECT Employee_key,
Employee_pkey = LAG(Employee_key, 1, Employee_pkey)
OVER(PARTITION BY Employee_bkey ORDER BY ValidFrom) FROM dbo.Stage_Employee ) t ON t.Employee_key =
s.Employee_key WHERE s.ValidFrom IS NOT
NULL ]]> </SqlStatementSource> </ExecuteTSqlStatement> </Tasks> </Package> <Package Name="Dim_Employee" ConstraintMode="Linear"> <Tasks> <Container Name="Stage_Employee ->
Dim_Employee" ConstraintMode="Linear"> <Tasks> <ExecuteTSqlStatement Name="Update ValidTo and
IsCurrent in Dim_Employee" ConnectionName="DSA_ADO"> <SqlStatementSource> <![CDATA[ UPDATE d SET ValidTo = s.ValidTo, IsCurrent = s.IsCurrent, UpdateTime = Getdate() FROM dbo.Dim_Employee d
WITH(TABLOCK) INNER JOIN
dbo.Stage_Employee s WITH(TABLOCK) ON s.Employee_key = d.Employee_key WHERE s.ValidFrom IS NULL ]]> </SqlStatementSource> </ExecuteTSqlStatement> <Dataflow Name="Insert Dim_Employee
from Stage_Employee" DefaultBufferSize="104857600" DefaultBufferMaxRows="10000"> <Transformations> <OleDbSource Name="Stage_Employee" ConnectionName="DSA_DB"> <DirectInput> <![CDATA[ SELECT Employee_key, Employee_dkey,
Employee_pkey, Employee_bkey, -- Business columns LastName, FirstName, dwh_Comparison,
ValidFrom, ValidTo, IsCurrent FROM dbo.Stage_Employee WHERE ValidFrom IS NOT
NULL ]]> </DirectInput> </OleDbSource> <OleDbDestination Name="Dim_Employee" ConnectionName="TEST_DB" UseFastLoadIfAvailable="true" TableLock="true" CheckConstraints="false" KeepIdentity="true" KeepNulls="false" BatchSize="10000" MaximumInsertCommitSize="2000000"> <InputPath OutputPathName="Stage_Employee.Output"/> <ExternalTableOutput Table="dbo.Dim_Employee"/> </OleDbDestination> </Transformations> </Dataflow> </Tasks> </Container> </Tasks> </Package> </Packages> </Biml> Download and
install BIDSHelperSetup to extend SQL Server Data Tools for Visual Studio
with BIML support https://bidshelper.codeplex.com/. Tutoring
to your first biml file and how to generate a SSIS package at this link: https://bidshelper.codeplex.com/wikipage?title=Biml%20Package%20Generator.
11.
Fact data connected to Kimball SCD type 7 dimension A data mart is first loaded with
data to the dimension tables as shown in chapter 5 and after that the data to
fact tables will be loaded where the metadata columns _key and _dkey will be
added to the fact data to create the connection to the values in a dimension
for current and historical purpose. A System dimension type 7 with metadata and descriptive
columns:
_key stands for a primary key as a surrogate increment
sequential number. _dkey stands
for a durable key is a integer representation of a business key. _pkey stands
for a previous key is reference to a _key value for the previous. _bkey stands
for a business key is the primary key in the source data. Column _key
is an unique primary key of the dimension table and the combination of
_bkey + ValidFrom or _bkey + ValidTo is unique too. 11.1
No transaction date then fact connect to current data When fact data have no transaction
date, the fact data will be connected to the current and not deleted data in
a dimension where business key match. It can be implemented by a Lookup in a
Data Flow Task that fill out a pipeline to be stored in the fact table. Same
for a Kimball type 1.
SELECT
System_bkey, System_key, System_dkey FROM
dbo.Dim_System WHERE IsCurrent
= 1 AND IsDeleted = 0
Example of a source data row:
Become a fact data row that use the
current dimension data reference:
11.2
With a transaction date then fact connect to historical data When fact data have a transaction
date, the fact data will be connected to the historical data in a dimension
where a business key match and where a transaction date is between ValidFrom
and ValidTo. Same for a Kimball type 2. It can be implemented by a Lookup in
a Data Flow Task that will fill out a pipeline to be stored in the fact
table. It can be named Date Range
Lookup. In this example a transaction date is called OutageDate in the
source data and is called SystemDate in the fact data because the date is
connected to a dimension called System.
SELECT
System_bkey, System_key, System_dkey, ValidFrom FROM
dbo.Dim_System WHERE IsDeleted
= 0
WHERE IsDeleted
= 0 AND System_bkey = SystemId AND ValidFrom <= OutageDate AND ValidTo
> OutageDate But the sql statement has
to use question mark ? input parameter for all
source data to make a dynamic sql statement where I using same selected
columns as above. I typein into the Lookup Advanced page 'Modify the sql
statement' this date range lookup sql statement (range filtering): SELECT
System_bkey, System_key, System_dkey, ValidFrom FROM
dbo.Dim_System WHERE IsDeleted
= 0 AND System_bkey = ? AND ValidFrom <= ? AND ValidTo >
? First ? parameter
represent SystemId and second and third ? parameter represent OutageDate. I
click [Parameters] and I can choose OutageDate in the dropdown because I
before made a fake match from OutageDate to ValidFrom.
Example of two source data rows:
Become two fact data rows that use
the historical dimension data reference:
In runtime mode the sql statement
and ? parameters from the source will be used to make a Date Range Lookup (Range
Filtering) but it puts the Lookup into a row-by-row operation and is calling
SQL Server for each row from the source with data as parameter values: exec sp_executesql
N'SELECT System_bkey, System_key, System_dkey, ValidFrom FROM dbo.Dim_System WHERE IsDeleted = 0
AND System_bkey = @P1 AND ValidFrom <= @P2 AND ValidTo > @P3', N'@P1 int,@P2 datetime2(3),@P3
datetime2(3)','76CB','2015-05-25 10:22:43','2015-05-25 10:22:43' exec sp_executesql
N'SELECT System_bkey, System_key, System_dkey, ValidFrom FROM dbo.Dim_System WHERE IsDeleted = 0
AND System_bkey = @P1 AND ValidFrom <= @P2 AND ValidTo > @P3', N'@P1 int,@P2 datetime2(3),@P3
datetime2(3)','76CB','2015-08-02 15:47:10','2015-08-02 15:47:10' That is not good for performance with
a large number of rows from the source. To avoid row-by-row operation the
Lookup needs a Cache Connection
Manager Transform as shown in earlier chapter with a sql statement that
do the connection and fetching of data from source and dimension like this: SELECT s.OutageDate,
d.System_bkey, d.System_key, d.System_dkey FROM dbo.Source_Production
s INNER JOIN dbo.Dim_System d ON
d.System_bkey = s.SystemId AND d.ValidFrom <=
s.OutageDate AND d.ValidTo > s.OutageDate WHERE d.IsDeleted = 0 Of course it will take some seconds
to perform this query and save the result in the cache but indexes at
business key, OutageDate, ValidFrom and ValidTo helps a lot. This Lookup method will not use fake
match or sql statement with ? parameter and from a self-explanatory
graphical user interface perspective this lookup match looks nice and add
columns _key and _dkey to the pipeline for the fact table into OLE DB
Destination.
To avoid Lookup you can use a
combination of Merge and Conditional split. I still like the idea of doing a
lookup to find the right row of the dimension but when I have million of rows
in the source, I need to speed up lookup with a C# script I will show in
section 11.4. 11.3
Inferred member when source data doesn't exist in dimension A dimension has a member value of
»Unknown«, »Missing«, »N/A«, »-« etc. to handle source data that is going to
be loaded into a fact table:
Approach: Handling null business key as
a missing member.
Approach: Late arriving dimension or
Early arriving fact as an unknown member, meaning a member value is an
orphan child because there is no parent member value in the corresponding
dimension table. A forthcoming fact row has a member
value that will infer a new dimension value, therefore it is called inferred
member. Approach to handle business key as an Unknown
dimension value Lookup
catch both situations in the 'Lookup No Match Output' pipeline where I add
two extra columns _key and _dkey and set them to default value 0 for Unknown through a 'Derived Column'.
I use a Union
All to put the pipelines together to insert all source data into the fact
table. The SSIS package will have this control flow and data flow:
Approach to handle business key as a New
dimension value I
am using the example from my
article Dimensional modeling which describes a Kimball type 7
dimension called Dim_System, data example:
Example
of table Source_Production with business key called SystemId:
All
data rows in table Source_Production will be loaded to table Fact_System
where the business key SystemId will be transformed to the dimension key
System_key in table Dim_System. There is three values in SystemId (90AA, 91KL, NULL) in four rows that does not exist
in Dim_System, therefore they are inferred members and will be infer to
Dim_System where NULL will be transformed to System_key -1 for »Missing«, and
90AA and 91KL will be inferred to two new data rows in
Dim_System as »Unknown 90AA«
and »Unknown 91KL«
with new numbers in System_key that will be used in loading data rows into
Fact_System table. After running the SSIS package the
table Dim_System will have new inferred rows:
The table Fact_System is loaded with
all the data rows from Source_Production and is also using the new inferred numbers
of System_key from the table Dim_System:
SSIS
package execution mode shows the number of rows in the pipelines with four
rows from Source_Production that is inferred members and they will be handled
in the Lookup 'Inferred members' with programming I will describe below:
When
a data row in Lookup 'Dim_System' can not match business key SystemId from
table Source_Production with System_bkey in table Dim_System, the data row
will be handled as a inferred member in Lookup 'Inferred members' like this: 1. In
the data Flow Task I drag in a Lookup and I edit it for 'Inferred members'. 2. In
page General I select 'Partial cache' and 'Ignore failure'. 3. In
page Connection I connect to the database at OLE DB connection manager and I
select 'Use results of an SQL query' because I want to limit the columns from
table Dim_System with a sql statement: SELECT
System_bkey, System_key, System_dkey FROM dbo.Dim_System I
select column System_bkey because it will be joined to the business key SystemId
from table Source_Production. I select columns System_key and System_dkey
because theses columns will be added to the pipeline to be loaded into the
Fact_System table. 4. In
page Columns I join business key SystemId with System_bkey and I checkmark
System_key and System_dkey. 5. In
page Advanced I select 'Modify the SQL statement' because I will do T-SQL
programming but first I will make a parameter ? to represent business key SystemId
from Source_Production by click [Parameters]. I
replace the default sql statement: select * from (SELECT System_bkey,
System_key, System_dkey from dbo.Dim_System) [refTable] where [refTable].[System_bkey] = ? with
a real T-SQL programming where parameter ? represent the business key
SystemId that I check for NULL and replace to -1 for »Missing« value in the dimension
that has _key value -1. When the business key does not exist in the dimension
table Dim_System, the variable @System_key will be null and I will insert a
new data row into the dimension table Dim_System: DECLARE @SystemId nvarchar(4)
= ISNULL(?,-1) -- -1 = Missing. DECLARE @System_key int SET NOCOUNT ON –- To check if @SystemId exists in dimension because
with multiple same inferred –- members I will only insert one new data row in
the dimension for the first –- inferred member. Therefore this T-SQL is a
row-by-row operation. SELECT @System_key =
System_key FROM dbo.Dim_System WHERE System_bkey =
@SystemId IF @System_key IS NULL -- True when
business key does not exist in dimension table. BEGIN INSERT
INTO dbo.Dim_System
(System_dkey, System_pkey, System_bkey, System, ValidFrom, ValidTo, IsCurrent, IsDeleted, IsInferred, InsertTime, UpdateTime )
VALUES
(0, 0, @SystemId, --
System_dkey, System_pkey, System_bkey, CONCAT('Unknown', ' ', @SystemId), -- mix of Unknown with business key to System, '19000101', '99991231', -- ValidFrom, ValidTo, 1, 0, 1, --
IsCurrent, IsDeleted, IsInferred, Getdate(), Getdate() --
InsertTime, UpdateTime )
–- Grap the newly
inserted and generated surrogate identity number of System_key. SET
@System_key = SCOPE_IDENTITY() –- Set
System_dkey to the new surrogate identity number. UPDATE dbo.Dim_System SET
System_dkey = System_key WHERE
System_key = @System_key END -- Give back value to Lookup therefore this select
match the select in Connection. SELECT System_bkey =
@SystemId, System_key = @System_key, System_dkey = @System_key When
SSIS package has been saved and open again, the above sql statement has been
formatet with no line breaks, therefore I can copy-paste it to a sql format
site like http://www.sql-format.com sql-format and get a nice readable sql statement like I
type it in when I made the package.
In
case you like to put the T-SQL programming in a stored procedure, you can
call it from 'Modify the SQL statement' with EXECUTE dbo.Dim_System_Inferred
?. Read more about the theory in my
article Dimensional modeling. Approach to handle business key as an missing
dimension value T-SQL
in a stored procedure gives best performance and is easy to write without a
lot of property settings and mouse clicks: CREATE PROCEDURE [dbo].[Fact_System_Insert] AS BEGIN SET NOCOUNT ON TRUNCATE TABLE dbo.Fact_System INSERT INTO dbo.Fact_System
(SystemDate, System_key,
System_dkey, ProductionKWh) SELECT s.OutageDate, d.System_key, d.System_dkey, s.ProductionKWh FROM dbo.Source_Production s INNER JOIN dbo.Dim_System
d ON d.System_bkey
= s.SystemId AND d.ValidFrom <= s.OutageDate AND d.ValidTo > s.OutageDate WHERE d.IsDeleted = 0 UNION ALL SELECT
s.OutageDate,
-1 AS System_key,
-1 AS System_dkey,
s.ProductionKWh FROM dbo.Source_Production s WHERE NOT EXISTS(SELECT 1 FROM dbo.Dim_System d WHERE d.System_bkey =
s.SystemId AND
d.ValidFrom <= s.OutageDate AND d.ValidTo > s.OutageDate AND d.IsDeleted =
0) ORDER BY OutageDate,
System_key END The stored
procedure will be executed from a SSIS package by a 'Execute T-SQL Statement
Task', therefore no data reading through a OLE DB Source into a SSIS pipeline
and later write pipeline data back to the database through a OLE DB
Destination because T-SQL do all the data extraction, transformation and
loading inside the database using the query optimizer. With T-SQL I can
do Left outer join together with theta join for <= or > as another algorithm
for inserting all source data rows into the fact table with Missing as -1
done by IsNull function: CREATE PROCEDURE [dbo].[Fact_System_Insert] AS BEGIN SET NOCOUNT ON TRUNCATE TABLE dbo.Fact_System INSERT INTO dbo.Fact_System
(SystemDate, System_key,
System_dkey, ProductionKWh) SELECT s.OutageDate, ISNULL(d.System_key,-1), ISNULL(d.System_dkey,-1), s.ProductionKWh FROM dbo.Source_Production s LEFT OUTER JOIN dbo.Dim_System d ON d.System_bkey = s.SystemId AND d.ValidFrom <= s.OutageDate AND d.ValidTo > s.OutageDate AND d.IsDeleted = 0 ORDER BY s.OutageDate, d.System_key END SSIS package Merge join can’t do theta join. 11.4
Date Range Lookup with script in C# for very fast performance A SSIS package
will query the source rows as »Full load« or as »Incremental load from an
archive by delta data in stream« and the rows will be inserted into the
pipeline and a lookup will fetch the right dimension value according to the
business key e.g. SystemId and to the transactiondatatime e.g. OutageDate with
this criteria that is called a Date Range Lookup because of the >= and
< (or called Range Filtering): System_bkey = SystemId
AND OutageDate >= ValidFrom
AND OutageDate < ValidTo Alternative as
used before in this article: System_bkey = SystemId
AND ValidFrom <= OutageDate
AND ValidTo > OutageDate It will be done
as a row-by-row operation and the pipeline stream of rows ends into the fact
destination table (target table). The SSIS Lookup component is too slow as
mention in 11.2, therefore I will here make a Lookup as a Script Component that will be added
between Source and Destination with properties:
Select relevant
columns from source in the pipeline to do the lookup in the table Dim_System.
SystemId is the business key in the source and OutageDate is going to be used
like this: System_bkey = SystemId
AND OutageDate >= ValidFrom
AND OutageDate < ValidTo Therefore I
select columns SystemId and OutageDate from the source pipeline as input
columns to the script component:
From the table Dim_System
I want the two columns System_key and System_dkey (the type 2 key and the
durable key for type 1) to the fact table as type 7, therefore I add both of
them as output columns to the script component, so they will be added to the
pipeline and saved into the destination fact table. In the dialog box
click at page »Inputs and Outputs« and in the tree click at »Output Columns«
and click at button [Add Column] and type in Name System_key and select the
right data type (int = DT_I4). I repeat it all again for the other column
System_dkey, and I get this:
Since the script
is going to read and cache all rows from the table Dim_System, I add the
ADO.NET connection to the component. Script component can not use OLEDB connection.
Connection TSQL_DSAconnectionstring is an ADO.NET connection I used for Truncate
Table Fact_System in Control Flow at Execute T-SQL Statement Task, therefore
I reuse the ADO.NET connection:
At page Script, I
click the button [Edit Script] and type in this C# program, and after the typing
I will in the menubar click Build and Build SC_ and look at status message in
left bottom corner says Build succeeded. I leave the coding window through menubar
by click File and Exit. In the C# program
code I am using a data structure called Dictionary that is a very fast load
and search in-memory cache to store the values of the dimension that I read
from the database with a sql statement. using System; using System.Data; using
System.Data.SqlClient; using
System.Collections.Generic; // for Dictionary as array/container data structure. using
System.Windows.Forms; // for MessageBox.Show. using
Microsoft.SqlServer.Dts.Pipeline.Wrapper; using
Microsoft.SqlServer.Dts.Runtime.Wrapper; [Microsoft.SqlServer.Dts.Pipeline. SSISScriptComponentEntryPointAttribute] public class ScriptMain : UserComponent { private Dictionary<Data, Keys> dictionary; // the cache to contain the sql output rows. public override void PreExecute() { base.PreExecute(); // sql to fetch data from a Kimball type 7 dimension with key and durable
key _dkey. // and data rows marked deleted is not included because not relevant for
fact rows in // the pipeline inside the SSIS from a Source to a Destination (target) fact
table. string sql = @"SELECT System_key,
System_dkey, System_bkey, ValidFrom, ValidTo FROM dbo.Dim_System WHERE IsDeleted =
0"; IDTSConnectionManager100 manager; SqlConnection connection; SqlCommand command; SqlDataReader reader; // ADO.NET connection in SSIS package, the last word
Connection is from // the Name column of the
Script Component Connection Managers. manager = this.Connections.Connection; connection = (SqlConnection)manager.AcquireConnection(null); command = new SqlCommand(sql,
connection); reader = command.ExecuteReader(); dictionary = new Dictionary<Data, Keys>(); // create cache in memory for adding rows. int bkey; // when System_bkey
is varchar, we
convert=parse to int to fit ProcessInputRow. // for each row the script
creates two data objects and add them to the cache in memory. while (reader.Read()) { Data d = new Data(); // business key and validfrom and validto for range
lookup. Keys k = new Keys(); // the keys to be
returned back into the pipeline. //d.Bkey = int.Parse(reader["System_bkey"].ToString()); // when _bkey
is int. if (int.TryParse(reader["System_bkey"].ToString(), out bkey)) { // _bkey = "172-9" try
becomes false and the row is not added to dictionary. d.Bkey = bkey; // the output value from TryParse is assigned to the d object. d.ValidFrom = DateTime.Parse(reader["ValidFrom"].ToString()); d.ValidTo = DateTime.Parse(reader["ValidTo"].ToString()); // only date d.ValidTo = DateTime.Parse(reader["ValidTo"].ToString()).Date; // to remove hour,minute,seconds and still use declaration: DateTime ValidTo // bigint with null d.Type = (reader["SystemType"] == DBNull.Value ? (long?)null : // Convert.ToInt64(reader["SystemType"])); //MessageBox.Show(reader["System_bkey"].ToString());
k.Key = int.Parse(reader["System_key"].ToString()); k.Dkey = int.Parse(reader["System_dkey"].ToString()); // k.Num = (reader["SystemNum"] == DBNull.Value ? (int?)null : // Convert.ToInt32(reader["SystemType"])); dictionary.Add(d, k); } } //MessageBox.Show(dictionary.Count.ToString());
// number of rows in table. reader.Close(); reader.Dispose(); reader = null; command.Dispose(); command = null; connection.Close(); connection.Dispose(); connection = null; manager = null; } public override void PostExecute() { base.PostExecute(); } public override void Input0_ProcessInputRow(Input0Buffer Row) { // for each row in pipeline from
source the script instantiate an object. if (!Row.SystemId_IsNull) // if business
key is not null then do. { // && Row.CodeText.Trim().Length
>= 1 no empty string "". Data d = new Data(); // to hold the value of (bkey,
transactiondatetime). d.Bkey = Row.SystemId; // the value to be found for the business key and d.Date = Row.OutageDate; // datetime
datatype as a TransactionDatetime. // only date d.Date = DateTime.Parse(Row.OutageDate.ToString()).Date; // bigint with null d.Type =
(Row.SystemType_IsNull ? (long?)null : // Convert.ToInt64(Row.SystemType)); Keys value; // to hold the value of (key, dkey) that will be
found by TryGetValue. if (dictionary.TryGetValue(d, out value)) // lookup
business key in dictionary. { // if found then
use the keys values. Row.Systemkey = value.Key; // script not like _ in column
name. Row.Systemdkey = value.Dkey;
//if (value.Num.HasValue) // An extra output column that allows a null value.
// Row.Num =
(int)value.Num; // take care of an integer value
with a cast.
//else // Row.Num_IsNull = true; // the way to assign null value to output column. // if (!Row.ColumnA_IsNull)
// assign ColumnB when ColumnA is allow null.
// Row.ColumnB = Row.ColumnA; // else // Row.ColumnB_IsNull
= true; } else // if business key is not found
in dictionary then make an inferred member. { int key = -2, dkey = -2; // -2 in a dimension represent Unknown data value. InferredMember(Row.SystemId, out key, out dkey); // output new id for keys. Row.Systemkey = key; Row.Systemdkey = dkey; // or treat inferred member in
fact row as a not available unknown key (-2). //Row.Systemkey = -2; //Row.Systemdkey = -2; //Row.Num_IsNull = true; } } else // if business key is null or is
an empty string then use the missing key (-1). { Row.Systemkey = -1; Row.Systemdkey = -1; //Row.Num_IsNull = true; } } private void InferredMember(int Bkey, out int Key, out int Dkey) { try { IDTSConnectionManager100 manager; SqlConnection connection; SqlCommand command; // ADO.NET connection in SSIS
package, the last word Connection is from // the name of the Script
Component Connection Managers. manager = this.Connections.Connection; connection = (SqlConnection)manager.AcquireConnection(null); command = new SqlCommand(); command.Connection = connection; command.CommandType = CommandType.StoredProcedure; //command.CommandTimeout = 10; Seconds
to wait for execute. Default is 30 seconds. command.CommandText = "dbo.Dim_System_MakeInferred"; command.Parameters.Add("Bkey", SqlDbType.Int).Value =
Bkey; command.Parameters.Add("Key", SqlDbType.Int).Direction
= ParameterDirection.Output; command.Parameters.Add("Dkey", SqlDbType.Int).Direction
= ParameterDirection.Output; command.Parameters.Add("ValidFrom", SqlDbType.DateTime).Direction
= ParameterDirection.Output; command.Parameters.Add("ValidTo", SqlDbType.DateTime).Direction
=
ParameterDirection.Output;
command.ExecuteNonQuery(); Key = (int)command.Parameters["Key"].Value; Dkey = (int)command.Parameters["Dkey"].Value; DateTime ValidFrom = (DateTime)command.Parameters["ValidFrom"].Value; DateTime ValidTo = (DateTime)command.Parameters["ValidTo"].Value; command.Parameters.RemoveAt("Bkey"); command.Parameters.RemoveAt("Key"); command.Parameters.RemoveAt("Dkey"); command.Parameters.RemoveAt("ValidFrom"); command.Parameters.RemoveAt("ValidTo"); command.Dispose(); command = null; connection.Close(); connection.Dispose(); connection = null; manager = null; Data d = new Data(); Keys v = new Keys(); d.Bkey = Bkey; d.ValidFrom = ValidFrom; d.ValidTo = ValidTo; v.Key = Key; v.Dkey = Dkey; dictionary.Add(d, v); } catch (Exception ex) { Key = Dkey = -2; throw new Exception("Something
wrong: " +
ex.Message); // To be seen in SSISDB. } } } public struct Keys // Keys to be find as output value of the Dictionary
data structure. { public int Key { get; set; } public int Dkey { get; set; } // public int? Num { get; set; } // When an extra output column allows a null value. } public class Data : IEquatable<Data> { public int Bkey { get; set; } // columns from the lookup table to help to find the
row. public DateTime ValidFrom { get; set; } public DateTime ValidTo { get; set; } public DateTime Date { get; set; } // input column to be between ValidFrom and ValidTo. // bigint with null value: public long? Type { get; set; } // or Nullable<Int64> // No need for the constructor // public Data() // {} public override int GetHashCode() { Unchecked // only hash
the business key, not validfromto, to lookup and find a match { // with the row in pipeline and Equals
return condition must also be true. return this.Bkey.GetHashCode(); //return
(this.BkeyCRM.ToString() + ";" + this.BkeyERP.ToString() +
";" + // this.BkeyHR.ToString()).GetHashCode(); //int hash = 13; //hash = (hash * 7) +
this.BkeyCRM.GetHashCode(); //hash = (hash * 7) +
this.BkeyERP.GetHashCode(); //hash = (hash * 7) +
this.BkeyHR.GetHashCode(); //return hash; } } // Equals method handle a collision when same Bkey
is in multiple rows because the values // to the business key has been changed
from the source, then we have to choose the row // where Date is in between. The return condition must be true for all values to
make // TryGetValue true. public bool Equals(Data d) { return this.Bkey == d.Bkey && d.Date
>= this.ValidFrom
&& d.Date < this.ValidTo; } } ----------------- // float? amount = 10.25; equals to
Nullable<float> amount = 10.25; // Database
null in a variable needs a datatype with ? or Nullable<Int32>, an example: int? num = null; if (num.HasValue) { num = Convert.ToInt32(num); } else { num = 0; } string? text = null; if (!string.IsNullOrEmpty(text)) The
stored procedure to make an inferred member in a dimension table. CREATE PROCEDURE [dbo].[Dim_System_MakeInferred] @Bkey int, @Key int
OUTPUT, @Dkey int
OUTPUT, @ValidFrom datetime OUTPUT, @ValidTo datetime OUTPUT AS BEGIN DECLARE
@InsertedRow TABLE (Keyx
int) DECLARE
@currentDateTime datetime = GETDATE() -- IdaInsertTime or Date of Change from source SET @ValidFrom = '1900-01-01 00:00:00' SET
@ValidTo =
'9999-12-31 00:00:00' SET NOCOUNT ON BEGIN
TRY BEGIN TRANSACTION --
Concurrency control when two or more ETL SSIS packages in parallel execution
at the same -- time simultaneously want to make same
inferred member is build as a
serial execution to -- be
serializable will be eligible for parallelism. --
Will be prevented from running at the same time automatically by the SQL
locking -- mechanisms.
Transaction isolation. INSERT
INTO dbo.Dim_System
-- with (serializable) will be removed in future
version. (System_dkey, System_pkey,
System_bkey, System, ValidFrom, ValidTo, IsCurrent, IsDeleted,
IsInferred, InsertTime, UpdateTime ) --
Grap the newly inserted and generated surrogate identity number of
System_key. OUTPUT
inserted.System_key INTO
@InsertedRow SELECT
0,
0, @Bkey, -- System_dkey, System_pkey, System_bkey, CONCAT('Unknown', ' ', @Bkey), -- mix of Unknown with business key to System, @ValidFrom, @ValidTo, --
ValidFrom, ValidTo, 1, 0, 1, -- IsCurrent, IsDeleted, IsInferred, @currentDateTime, @currentDateTime --
InsertTime, UpdateTime WHERE
NOT EXISTS ( SELECT
TOP(1) 1 FROM
dbo.Dim_System WHERE
System_bkey = @Bkey AND
IsCurrent = 1 ) IF
@@ROWCOUNT =
1 BEGIN SELECT
@Key = Keyx FROM
@InsertedRow --
WAITFOR DELAY '00:00:15' -- for testing --
Set Dkey to the new surrogate identity number. UPDATE
dbo.Dim_System SET
@Dkey = System_dkey =
System_key WHERE
System_key = @Key END ELSE -- When
the business key has been inserted by another process we fetch it here. BEGIN SELECT
@Key = System_key,
@Dkey = System_dkey,
@ValidFrom = ValidFrom, @ValidTo = ValidTo FROM
dbo.Dim_System WHERE
System_bkey = @Bkey AND
IsCurrent = 1 END IF @@TRANCOUNT >
0 COMMIT TRANSACTION
-- The transaction will release the lock. END
TRY BEGIN
CATCH
-- Determine if an error occurred. IF @@TRANCOUNT >
0 ROLLBACK TRANSACTION
-- The transaction will be cancelled. -- Return the
error information. DECLARE
@ErrorMessage nvarchar(4000), @ErrorSeverity int, @ErrorState int SELECT
@ErrorMessage = ERROR_MESSAGE(),@ErrorSeverity =
ERROR_SEVERITY(),
@ErrorState =
ERROR_STATE() RAISERROR(@ErrorMessage,
@ErrorSeverity, @ErrorState) WITH NOWAIT ;THROW -- almost do the same as raiseerror so no need for both
commands, I like THROW. END CATCH END GO 11.5
OLE DB Destination handle primary key violation and error When OLE DB Destination meets bad data it will fail
and not insert any rows, even the good ones. Bad data is primary key
violation or foreign key violation and other constraint violation error. Primary
key violation when a row from OLE DB Source table already exists in OLE DB
Destination table, or when source table has two rows with same value in
primary key and maybe the rows are duplicate rows. Here is a trick to have
the good rows inserted in a double OLE DB Destination way:
We let the first OLE DB Destination redirect bad
rows to red pipeline to a second OLE DB Destination that insert rows one-by-one
so all good rows will be inserted successfully and bad rows will again be redirecting
to an error table with an error description we extract from a Script
Component.
A OLE DB Source table comes with 10 rows, but two
rows has same primary key ALFKI and the last row is has null value in a not
allow null column in the OLE DB Destination table:
All 10 rows are in the same batch
therefore the first OLE DB
Destination will fail and not insert any rows and all 10 rows are redirected
to the second OLE DB Destination that insert rows one-by-one so all good 8
rows will be inserted successfully and 2 bad rows will again be redirecting and
inserted to an error table:
ErrorDescription can also be e.g.:
The data was truncated when destination column size is too small. Both OLE DB Destination is using the access mode 'Table or
View - fast load'. Instead of using commit size 1, you can use the access
mode 'Table or View' because it will save each row individually, to perform row-by-row
insert. The Script Component C# code to catch the error message
and add them to two output columns that is in the error table:
SQL Server 2016+: public override void
Input0_ProcessInputRow(Input0Buffer Row) { try { //Row.ErrorRowId = Row.SupplierID_IsNull ?
"" : Row.SupplierID.ToString(); Row.ErrorDescription = this.ComponentMetaData.GetErrorDescription(Row.ErrorCode); // =
Row.ErrorCode.ToString(); IDTSComponentMetaData130 componentMetaData = this.ComponentMetaData
as IDTSComponentMetaData130; if (componentMetaData != null &&
Row.ErrorColumn != 0) { Row.ErrorColumnName
= componentMetaData.GetIdentificationStringByID(Row.ErrorColumn).Replace("OLE DB
Destination Retry.Inputs[OLE DB Destination Input].Columns[", "").Replace("]", ""); } else { if (Row.ErrorCode == -1071607683 || Row.ErrorCode ==
-1071607685) { Row.ErrorDescription = "Check the
row for a violation of a primary key or a foreign key constraint."; Row.ErrorColumnName = "Unable to
fetch column name. ErrorCode: " + Row.ErrorCode.ToString(); } else { Row.ErrorColumnName = "ErrorCode:
" +
Row.ErrorCode.ToString(); } } } catch (Exception) { Row.ErrorColumnName = "Unable to
fetch column name"; } } Old version: public override void
Input0_ProcessInputRow(Input0Buffer Row) { try { //Row.ErrorRowId
= Row.SupplierID_IsNull ? "" : Row.SupplierID.ToString(); if (Row.ErrorCode == -1071607685) { Row.ErrorDescription
= "Check
the row for a violation of a primary key or a foreign key constraint."; Row.ErrorColumnName
= "Unable
to fetch column name. ErrorCode: " + Row.ErrorCode.ToString(); } else { Row.ErrorDescription
= this.ComponentMetaData.GetErrorDescription(Row.ErrorCode);
// = Row.ErrorCode.ToString(); IDTSComponentMetaData130 componentMetaData = this.ComponentMetaData
as IDTSComponentMetaData130; if (componentMetaData != null &&
Row.ErrorColumn != 0) { Row.ErrorColumnName =
componentMetaData.GetIdentificationStringByID(Row.ErrorColumn).Replace("OLE DB
Destination Retry.Inputs[OLE DB Destination Input].Columns[", "").Replace("]", ""); } else { Row.ErrorColumnName
= "ErrorCode:
" +
Row.ErrorCode.ToString(); } } } catch (Exception) { Row.ErrorColumnName = "Unable to
fetch column name"; } } // For sql
server 2014 // Row.ErrorDescription
= this.ComponentMetaData.GetErrorDescription(Row.ErrorCode)
+ // " for column " + Row.ErrorColumn.ToString(); // IDTSComponentMetaData100
componentMetaData = this.ComponentMetaData as IDTSComponentMetaData100; // Row.ErrorColumnName
= componentMetaData.Description; Remember when you drag the red
pipeline from a OLE DB
Destination, you must select 'Redirect row' in the Error column dropdown in
the dialogbox and the yellow warning triangle disappears:
With this »double error destination«
approach you can implement a robust ETL process and avoid to fail and become
a failure when source system provides bad data. 12.
Dynamic sql based of for each row in a table This
approach can be used for asking for delta data from a specific date timestamp
but I will make it with a loop of rows that each create a dynamic sql to fetch
data from a source system table and store data to a table. The source
database is Northwind that has a Customers tables where I will fetch data to
a data warehouse table called Source_Customer with use of another table Source_Customer_ID
which contains the CustomerID I want one by one to fetch from Northwind. I use Execute T-SQL Statement Task,
Data Flow Task, OLE DB Source, Recordset Destination, Foreach Loop Container
and OLE DB Destination. 'Recordset Destination' creates and
populates an in-memory ADO recordset that is available outside of the data
flow and I will store the CustomerID values from the table Source_Customer_ID
that will be
loaded into the data warehouse.
I
make three package variables to hold a recordset of table Source_Customer_ID
and the column CustomerID that will be used for the 'Foreach Loop Container'.
In 'Control Flow' I drag in 'Execute
T-SQL Statement Task' to start for empty the Source_Customer
with an sql statement: TRUNCATE TABLE dbo.Source_Customer I drag in 'Data Flow Task' and a 'OLE
DB Source' that I connect to table Source_Customer_ID. I
drag in 'Recordset
Destination' and pull the pipeline to it and Edit it to select variable User::Recordset
to property VariableName and at tab Input Columns I checkmark column
CustomerID. Now the recordset variable will contain the records from table Source_Customer
and I can loop through it.
Back
in 'Control
Flow' I drag in 'Foreach Loop Container' and pull the 'Precedence
constraint'
green arrow to it and Edit at Collection page where I at property Enumerator
select {Foreach ADO Enumerator} and at property ADO object source variable
select {User::Recordset}. At page Variable Mappings I select variable CustomerID
that will change value for each record there will be looped by.
I
like to test that the package is working but I’m not so much into breakpoint,
therefore I drag in a 'Script
Task' into 'Foreach Loop Container' and I edit it and click at button [Edit
Script] and in the editor window I typein a C# program statement above the
line which is there already: Dts.TaskResult =
(int)ScriptResults.Success; I typein a messagebox that will be
shown when the package is running, I cast the variable to a string, but I
already know variable is a string: MessageBox.Show(Dts.Variables["User::CustomerID"].Value.ToString()); I exit editor C# programming window
and at property ReadOnlyVariables I checkmark User::CustomerID. Very important
to remember this else script is not working. I start the package to see
messagebox for each value of variable CustomerID that has been taking from
table Source_Customer into the recordset
variable while 'Foreach
Loop Container' is traversing through the recordset variable. Everything is working well, so I
rightclick 'Script Task' and {Disable} it, so no more messageboxes and easy
to {Enable} it again another time. The dynamic sql statement will be
using the variable CustomerID and make a select-from-where dynamic sql
statement per loop of the Recordset variable with different values in CustomerID
variable. I drag in a 'Data Flow Task' into 'Foreach Loop
Container' and a 'OLE DB Source' that I let have this SQL Command: SELECT
CustomerID,
CompanyName,
ContactName,
ContactTitle,
Address,
City,
Region,
PostalCode,
Country,
Phone,
Fax FROM dbo.Customers WHERE CustomerID = ? ? question mark is an unknow input parameter value that
make the sql statement dynamic because I will connect the parameter to the CustomerID
variable by click at button [Parameters] and select User::CustomerID and at
runtime the variable will change value from the 'Foreach Loop Container' and 'OLE
DB Source' will make a new query request to the Northwind database to table Customers
and fetch a record that I like to store in Source_Customer.
To
know when the select sql statement has found a record that match the value of
CustomerID variable, I drag in a 'Row Count' and pull pipeline to it and edit it
to select the package variable User::RowCount. I will use RowCount variable
in 'Control Flow' later. First I will tell the 'Data Flow' to store the found
record in the destination table Source_Customer. I
drag in a 'OLE
DB Destination'
and pull the pipeline to it and select table Source_Customer
and check the mapping that is fine as default. When a record has been found in
Northwind and successful saved in Source_Customer,
I like to delete the CustomerID record in the Source_Customer_ID table. Back
in 'Control
Flow' I drag in 'Execute SQL Task' Task' into 'Foreach Loop Container' and
pull the pipeline to it. I edit the green 'Precedence
constraint'
arrow,
because I can extend the constraint with an logical boolean expression, so I
change 'Evaluation
operation'
from "Constraint" to "Expression and Constraint". In the expression I’m using
the RowCount variable with a C# notation for comparison for equivalent: @[User::RowCount] == 1 Expression
must be success before the 'Control
Flow' continue to 'Execute SQL Task'. If a CustomerId in table Source_Customer_ID was not found in
Northwind Customers table in the 'Data Flow Task', the RowCount variable will
be assigned value 0 and the expression above will be false, and 'Control Flow'
will not continue to 'Execute SQL Task'. A smart way to do a kind of 'Conditional
Split' in a 'Control Flow' because a Failure red 'Precedence
constraint'
arrow will be followed when expression is false. A fx logo is shown at the
green 'Precedence constraint' arrow
telling there is an expression included in the criteria for successful and continuation. I edit the 'Execute SQL Task' to add
a dynamic delete sql statement that will delete a record from Source_Customer_ID
table for the value in CustomerID variable. In SQLStatement property I
typein: DELETE
FROM
dbo.Source_Customer_ID WHERE
CustomerID = ? At
Parameter Mapping page I select:
'Parameter Name' show "NewParameterName"
but it must be overwritten with a 0 (zero) for first ? parameter and 1 for
second ? parameter and so on. Parameter Name is only for using a
parameterized stored procedure where 'Parameter Name' is the same name as the
stored procedure's parameter name. For integer, decimal, date, datetime
and so on 'Parameter Size' will be -1.
In case you want to be more sure of
parameter name in a dynamic sql statement and give it a stored procedure
look-a-like this is useful, where ? parameter value will be assigned to a
t-sql variable: DECLARE @CustomerID AS nvarchar(5) =
? IF @CustomerID IS NOT NULL BEGIN
DELETE
FROM dbo.Source_Customer_ID
WHERE CustomerID = @CustomerID END When there is several delete
statements in different tables you can reuse the t-sql variable. Stored
procedure I prefer using stored procedures, so
a SSIS package does not contains sql statements and has dependency to the
database tables and columns. A stored procedure become an interface, so SSIS
package don’t need to know anything else about the database. CREATE PROCEDURE
dbo.Source_Customer_ID_Delete @CustomerID
nchar(5) AS BEGIN SET
NOCOUNT ON DELETE
FROM
dbo.Source_Customer_ID WHERE
CustomerID = @CustomerID END GO
Very important that Parameter Name
has @ in the name, else I can also use 0 as shown before for the first ?
parameter.
Stored procedure can also be used in
a 'OLE DB Source' like this call for data: EXECUTE dbo.CustomerBySelection ? WITH RESULT SETS( (
CustomerID int,
CompanyName nvarchar(50),
ContactName nvarchar(50),
ContactTitle nvarchar(35),
Address nvarchar(100),
City nvarchar(50),
Region nvarchar(20),
PostalCode nvarchar(10),
Country nvarchar(50),
Phone nvarchar(50),
Fax nvarchar(50) )) to explicitly specify the data types
of the columns for the pipeline and under button [Parameters] in column
Parameters I typein the parameter name from the stored procedure include @,
like this: @CustomerID
Preview does not work together with
a ? parameter, therefore replace ? with a value like this: dbo.CustomerBySelection
'DALB' Now Preview will show data from that
CustomerID, remember to replace back to ? so the parameter for the stored
procedure is using the SSIS package variable User::CustomerID. When stored procedure has two or
more multiple parameters, remember to place a comma , between ? like this:
dbo.CustomerBySalesPeriod ?, ? More readable way:
dbo.CustomerBySalesPeriod @StartDate = ?, @EndDate = ? And there must be two Mapping
Parameters @StartDate and @EndDate connected to each own SSIS package
variable, like this:
Execute SQL
Task with ADO.NET connection to Result Set to Foreach Loop Instead of using a 'Data Flow Task'
to do the Select statement and flow data to a 'Recordset Destination', you
can use an 'Execute SQL Task' in 'Control Flow' to do the Select statement
and set property 'ResultSet' to 'Full result set' and at page 'Result Set'
add a package variable with datatype Object like Recordset as used above. If
Select statement has a Where part and you like to use named @parameter
instead of the values 0, 1, then let 'Execute SQL Task' use ConnectionType
ADO.NET and the Where part can have @parameter like we saw above when we
called a stored procedure with parameter. I am using package variables with
default values to show how ADO.NET is implemented and the position of
@parameters does not matter. It is the same ADO.NET connection that 'Execute
T-SQL Statement Task'
is using but this can not have parameters.
ADO.NET benefits for a sql statement with a search criteria in
a variable A package variable @[User::ContactTitle]
in the dialogbox column Variable Name will at run time be transferred to a
t-sql variable in column Parameter Name where I have named the variable @ContactTitle
(don’t need to be same name as package variable) and it gets automatic the
rigth data type, therefore no declare and inside the SQL Statement I can use
the @ContactTitle like in normal t-sql code in a stored procedure or ad hoc
query in SQL Server Management Studio. |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
13.
Transforming data by C# In a Data Flow Task there is a
Script Component that can update columns in a SSIS pipeline by C#. In this
example I have a source table with a nvarchar(50) column called Code that has
a mix of chars like 12AK-34-x or 12.34.56 and I like to update letters to
uppercase and I like to take away the letters from the Code and set null or
empty string with length 0 to text "Nothing". The updated pipeline
will be inserted into a staging table.
When Edit a Script Component it is
important to checkmark the column(s) that is going to be used in C# program
for reading only or for also write back as update the column. I open the
editor by click the button [Edit Script] and there is already three methods:
Input0 represent the
pipeline into Script Component, Row contains the checkmark columns that is
refered like Row.Columnname. It is here the transformation is programmed like
this: public override void
Input0_ProcessInputRow(Input0Buffer Row) { String pattern = "[^0-9]"; System.Text.RegularExpressions.Regex regex = new
System.Text.RegularExpressions.Regex(pattern, System.Text.RegularExpressions.RegexOptions.Compiled); if (!Row.Code_IsNull && Row.Code != String.Empty) { Row.Code = Row.Code.ToUpper(); Row.Code = regex.Replace(Row.Code, String.Empty); } else { Row.Code = "Nothing"; } } Row has a _Isnull property and with
! it become true when column is not null. A empty string with length 0 done in
sql: UPDATE T SET C = "" can
also be detected. The method will be called per row in
the pipeline so the two variables will be declared, assigned and released (or
disposed) in each call, therefore it is better to place variables as
attributes for the class object and assign them in PreExecute because that
will happens only one time no matter how many rows there is in the pipeline.
I have include "using" (same as VB.NET Imports) to enable type name
like "Regex" to be referenced without namespace qualification
that makes the program more readable: using System.Text.RegularExpressions; [Microsoft.SqlServer.Dts.Pipeline. SSISScriptComponentEntryPointAttribute] public class ScriptMain : UserComponent { String pattern; Regex regex; public override void PreExecute() { base.PreExecute(); pattern = "[^0-9]"; regex = new Regex(pattern, RegexOptions.Compiled); } public override void PostExecute() { base.PostExecute(); } public override void Input0_ProcessInputRow(Input0Buffer Row) { if (!Row.Code_IsNull &&
Row.Code != String.Empty) { Row.Code = Row.Code.ToUpper(); Row.Code =
regex.Replace(Row.Code, String.Empty); } else { Row.Code = "Nothing"; } } } A Script Component can split an
input pipeline into multiple output pipelines, so instead of updating to "Nothing"
I will redirect theses rows to another pipeline and to another OLE DB
Destination. I edit Script Component and in Inputs and Outputs page I click
[Add Output] and I rename the two outputs to Valid and Error, and I set both
property SynchronousInputId to same Script Component.Inputs[Input 0] and both
property ExclusionGroup to 1 and change the C# programming:
It is Row that do the direction to
the two outputs Valid and Error with: Row.DirectRowToValid(); and Row.DirectRowToError(); where the . dot popup intelligence shows
the names of the two outputs I made. 14.
Transforming data by OLE DB Command row-by-row I like to extend the pipeline with a
new column but the Derived Column can’t access database or stored procedure,
therefore I will use the row-by-row operation called OLE DB Command. For each
row in the pipeline I will call a stored procedure with an input and output
parameter and it is the output parameter that will be to the new column in
the pipeline and to the destination table in the SSIS package. The trick is to begin with to add a
derived column with an null or empty expression that fit the data type to the
pipeline from the source, like a new Education column:
The new empty column Education will
fetch a value from a stored procedure’s output parameter, where the stored
procedure has been doing som look up (or calculate) in the database to make
an education string for each employee, one-by-one or row-by-row. The OLE DB Command component gets a
connection and a sql command is calling or execute a stored procedure with an
input parameter and an output parameter: EXEC
dbo.Stage_Employees_Fetch_Education ?, ? OUTPUT The two ? parameters will be
connected to the columns of the pipeline as a destination columns that will
show the name of the parameters in the stored procedure (or in a ad hoc sql
command as param_0, param_1, etc.):
Hereafter the new pipeline column
Education is mapped to the destination table column also called Education. A stored procedure could also output
a new surrogate key number from a Identity column in a table using like SCOPE_IDENTITY()
as I showned before inside Lookup component. OLE DB Command sql command can also
use a sql statement to extend pipeline: Select ? = Name From
T Where Id = ? Normally OLE DB Command is used for
Update statement to a table, see next. 15.
Don’t let OLE DB Command do row-by-row update OLE DB Command has not good for
performance with a large number of rows in a pipeline therefore it is better
to insert updated rows in a staging table and then do a T-SQL bulk update
back to the original table. Row-by-row operation is also called singleton
update and is the opposite of a batch bulk update. Maybe you are used to do all data
transformation through t-sql Updates in a stored procedure, where you have a
Update per transformation which means that the same row in a table will be
updated mutiple times. That’s gives a lot of I/O and R/W to the database
table. With a SSIS package and a Data Flow Task and its pipeline the multiple
transformations will be done in memory and therefore save I/O to the database.
But the problem is that when the updates in the pipeline are going to be
stored in the database, SSIS package can only do it with a row-by-row
operation that’s include a t-sql Update with ? parameters for each row which
will kill the performance. This example will show different
transformations in a pipeline and use a staging table to do the updates back
to the original table. The SSIS package will have I/O to the database when
fetch data to pipeline, when insert updated values to the staging table and
when doing the update to the original table. Control Flow where the staging table
is truncated in beginning and the Update to the original table is done at the
ending. In between there is two Data Flow Task where the first will fetch
data to a cache used for a Lookup in the other Data Flow Task. I have an
Orders table with three columns to be calculated and updated:
The first Data Flow Task fetchs the Order
Details data and do a sum of Quantity per OrderId and store the resultset or
recordset in a cache to be used later in a Lookup:
The second Data Flow Task fetchs the
Orders data and to the transformation on the pipeline by adding extra columns
where the new Orderdata is calculated like this: (DT_DATE)((DT_WSTR,4)(YEAR(OrderDate))
+ "-" + (DT_WSTR,2)(MONTH(OrderDate)) + "-01")
And when data is inserted into the
Staging_Orders table, the bulk t-sql Update is performed with a very fast performance
compared to a row-by-row update. 16.
SSIS package gets connection string from a table I
like to place connection string to a source system in a table instead of environment
variable inside the SSISDB catalog at three servers for development, test and
production. Here is an example of a solution called Source that contains a
project per source system and each package will fetch the connectionstring
from a table in a database called ETL_SYSTEM that is placed at same server as
the SSISDB catalog (therefore package can use localhost connection) and it
will be together with the other database warehouse databases. I like to have an
Input Data Area (IDA) database per source system. I am using Northwind as one
of my source systems and it gives me an IDA_Northwind database to store the
fetched source data. In
ETL_SYSTEM database I have a table with connection string for each source
system e.g. sql server, oracle, db2, a csv file and many more can be placed
in the table. Of course the connection string syntax must fit together with
the SSIS Connection Manager where I first make the connection and then I rightclick
{View Code} to fetch the syntax. In each environment the connection string
can be the same or be different, because development fetching data from
source system in development and test and production fetching data from
source system in production. The
Source table has some connection strings:
I
am making a new SSIS solution called 'Source' with three projects for each source
system. I
continue with 'Northwind' project where I add a project parameter with value
1 for the row with source_id 1 for Northwind connection. I let the parameter
be requiried false, so the value 1 will automatic be the default value for
the parameter when executed from SSISDB catelog. I add two localhost connections
for database ETL_SYSTEM using ADO.NET to make sql statement with variable
more readable, and for IDA_Northwind database using OLE DB to store source data
as first step into the data warehouse:
I
will make a package for each table I like to fetch from the source system
e.g. Customers table. I make a package variable called 'Source_Connetionstring'
that I will use to store the connectionstring from the Source table and use
the variable in an Expression for the package connection to the source
system. The variable 'Source_Connetionstring' will have a value for the
connection string to the development server for the source system and is
used for making the package in design mode:
In
case I like to open the package in the production server of the data
warehouse, I will need to change the value of the variable to point to the
production server of the source system so I can debug the package in
production e.g. to find a changed data type for a column. In
Control Flow I make an Execute SQL Task 'Get Source_Connetionstring' to fetch
the connection string from the Source table for source_id from the project
parameter and store it in the variable. Since the Source table is placed in
ETL_SYSTEM database and the connection is using ADO.NET, I select Connectiontype
and I am using @variable in the sql query statement:
SQL
statement to fetch the connection string from the Source table is: SELECT
@Source_Connetionstring = Source_Connetionstring FROM
dbo.Source WHERE
Source_Id = @Source_Id In
Control Flow I make an Execute SQL Task 'Truncate table' to empty the Customers
table in the IDA_Northwind database:
In
Control Flow I make a Data Flow Task 'Fetch data' to do a full dump of all
rows from the source to the empty table in IDA_Northwind database. Inside
the package I make a new package connection in the tab Connection Manager to
the source system server and database Northwind as a OLE DB because it is a
SQL Server. I am calling the connection 'Source'. I click at 'Source' and I
am looking at the properties and click at Expression and click at the […] button.
In the dialogbox I click in column Property and open the dropdown and select
'Connection String' and in the other column Expression I click at the […] button
and in the dialogbox I drag and drop variable User::Source_Connetionstring
into Expression box and it become: @[User::Source_Connetionstring] meaning,
when the package is running or is executed the connection manager will use the
current value of the variable. Therefore the package will run in production
without any changes because in production it will use the connection string
from the Source table from the ETL_SYSTEM database in production server.
Notice
the fx at the Source connection in Connection Managers, fx tells us that it
is using an Expression to give it value in design mode and in running mode. I
can go inside the a Data Flow Task 'Fetch data' and make the OLE DB Source
using the Source connection, and make OLE DB Destination using the
IDA_Northwind project connection, click New button and rename [OLE DB
Destination] to [Customers] to have the table created in the IDA database:
I
like to have in the destination table an extra column called 'InsertTime'
with data type datetime2(3) and default value (sysdatetime()) so I can see
when the rows are inserted the last time. After the adding I need to
rightclick at OLE DB Destination and select Mappings to update the SSIS
package metadata. Now
the package is ready for a test run. If I have user access to production server
I can change the connection string part Data Source=SQLDev4 to Data Source= SQLProd1
and fetch production data to the development server IDA database. For
the next source table I will reuse the first package and make a copy-paste of
it and change the Truncate table, the OLE DB Source and the OLE DB
Destination to the new table. I
will make a batch job run execute package that will be calling the other
packages:
The
_Execute.dtsx package will be part of the ETL process. When
there is many tables from the same source system, I can move the 'Get
Source_Connectionstring' from each table-package to the _Execute package and
send the connection string to each table-package as a parameter e.g. for Categories
table where the package parameter is used in the source connection
expression. The parameter 'Source_Connectionstring' will have a value for the
connection string to the development server for the source system and is
used for making the package in design mode:
The
_Execute.dtsx package has a variable Source_Connectionstring with a value for
design mode and the variable will be assigned in running mode with the
connection string from the Source table in ETL_SYSTEM database as we saw it
made before. When calling the table-package e.g. Categories the variable will
be passed by as a parameter to the other package:
I
like the SSIS deployment by command line with a bat file for each environment
development, test and production, here I making it for dev:
"%ProgramFiles%\Microsoft
SQL Server\120\DTS\Binn\ISDeploymentWizard.exe" /S /ST:File /SP:Northwind.ispac /DS:SQLDEV
/DP:/SSISDB/Source/Northwind The notation is: "%ProgramFiles%\Microsoft SQL
Server\120\DTS\Binn\ISDeploymentWizard.exe" /S /ST:File /SP:<SSIS project name>.ispac /DS:<SQL Server
name> /DP:/SSISDB/<SSISDB
folder name>/<SSIS project name>
Later
it is easy to have other .bat files for test server and for production server
for deployment from my computer, or hand over the Northwind.ispac file to a
person to do it in test and later in production. 17.
SSIS package handles files before a file is loading A
folder will contain some Excel xsl (97-2003) files that one-by-one has to be
loaded as source into a table. I make a SSIS package to scan the files from
the folder and copy it to an Input folder with a specific filename and another
SSIS package to connect to the file and load it, and after load I move the
file to an Archive folder with a datetime prefix to the filename to make all
files unique. In
the first package I define som parameters so folder can be set outside:
Define
variables with expressions because a variable will be assigned a value from a
expression when the package is using the variable:
Variable
vaArchivePathFile gets datetime as prefix in filename with this expression: @[$Package::paFolderArchive] +
"\\" + (DT_WSTR,4)
DATEPART("Year", Getdate()) + RIGHT( "0" + (DT_WSTR,2)
DATEPART("Month", Getdate()) , 2 ) + RIGHT( "0" + (DT_WSTR,2) DATEPART("Day",
Getdate()) , 2 ) + RIGHT( "0" + (DT_WSTR,2)
DATEPART("Hour", Getdate()) , 2 ) + RIGHT( "0" + (DT_WSTR,2) DATEPART("Minute",
Getdate()) , 2 ) + RIGHT( "0" + (DT_WSTR,2)
DATEPART("Second", Getdate()) , 2 ) + @[User::vaSourceFile] Control
flow will copy and move a file and call the other package to load the file. It
is wrapped in a 'Foreach Loop Container' to repeat the sequence for each
file:
Foreach
component settings that set the folder from a parameter and assign a variable
with a filename (without path) from the folder:
Copy
component settings to copy the file to folder Input and a fixed filename,
because the Source will load from that specific filename:
Calling
an other package settings that will load a file from Input folder into a
table:
Move
component settings, but using remove because it works:
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
18.
SSIS package with a .NET C# program In SSIS Toolbox there is a tool
called Script Task where I can make a .NET C# program to handle things, like
to copy a source file to the right folder and for backup the file and give
the file the right name so it later can be imported by the IS package to a
table in the DSA database. I find it better to make a C# program instead of
variables and parameters in IS packages. This C# program has the main procedure
as the program start and an extra function that read the first line of the
file and returned it as a string for further use in the main program: using System; using System.IO; // gives File
og Directory //using
System.Data; //using
System.Math; //using
System.Collections; using
Microsoft.SqlServer.Dts.Runtime; using
System.Windows.Forms; namespace
ST_d1bc9f3673db40b0b35603ccb0a0e61b.csproj { [System.AddIn.AddIn("ScriptMain", Version = "1.0", Publisher = "", Description =
"")] public partial class ScriptMain : Microsoft.SqlServer.Dts.Tasks.ScriptTask.
VSTARTScriptObjectModelBase { #region VSTA generated code enum ScriptResults { Success = Microsoft.SqlServer.Dts.Runtime.DTSExecResult.Success, Failure = Microsoft.SqlServer.Dts.Runtime.DTSExecResult.Failure }; #endregion public void Main() { // The folder source system save the file into.
Filename is different per delivery. string srcFolderPath = "S:\\SOURCE"; // The folder that the IS package will import the
file from with same file name. string dsaFolderPath = "S:\\DSA_SOURCE"; // The fixed file name to be imported by the IS
package. string dsaFileName = "SOURCE.TXT"; string dsaBackupFileName = "SOURCEyyyymm.TXT"; // yyyymm
replaced with the date of running. string srcBackupFolderPath = srcFolderPath + "\\Backup"; string dsaBackupFolderPath = dsaFolderPath + "\\Backup"; string srcFileName; string srcPathFileName; string srcBackupPathFileName; string dsaPathFileName; string dsaBackupPathFileName; long length = 0; string line = null; string yyyymm = null; if (Directory.Exists(srcFolderPath) && Directory.Exists(srcBackupFolderPath)
&& Directory.Exists(dsaFolderPath)
&& Directory.Exists(dsaBackupFolderPath)) { try { if (Directory.GetFiles(srcFolderPath).Length == 0) { //MessageBox.Show("No file
in source folder from source system"); Dts.TaskResult = (int)ScriptResults.Failure; return; } if (Directory.GetFiles(srcFolderPath).Length >= 2) { //MessageBox.Show("Two or
more files in source folder, not good"); Dts.TaskResult = (int)ScriptResults.Failure; return; } if (Directory.GetFiles(srcFolderPath).Length == 1) { srcFileName =
Path.GetFileName(Directory.GetFiles(srcFolderPath)[0]); // Directory.GetFiles return an
array of path and file names. // Copy source file to backup folder. srcPathFileName = srcFolderPath + "\\" + srcFileName; srcBackupPathFileName =
srcBackupFolderPath + "\\" + srcFileName; if (!File.Exists(srcPathFileName)) { //MessageBox.Show("Source
file not found"); Dts.TaskResult = (int)ScriptResults.Failure; return; } // If source file size is 0
byte, something is wrong and better stop. length = new
FileInfo(srcPathFileName).Length; if (length == 0) { //MessageBox.Show("Source
file size is 0 byte"); Dts.TaskResult = (int)ScriptResults.Failure; return; } // Read first line of the file
to receive year and month. line =
ReadFileFirstLine(srcPathFileName); if (line == null || line.Length
<= 13) { //MessageBox.Show("No line
or too short line"); Dts.TaskResult = (int)ScriptResults.Failure; return; } yyyymm = line.Substring(6, 6); // position 0
is the first char in string of C#. //MessageBox.Show(yyyymm); if (File.Exists(srcBackupPathFileName)) File.Delete(srcBackupPathFileName); File.Copy(srcPathFileName,
srcBackupPathFileName); // Move source file to DSA
folder and give a fixed file name. dsaPathFileName = dsaFolderPath + "\\" + dsaFileName; if (File.Exists(dsaPathFileName)) File.Delete(dsaPathFileName); File.Move(srcPathFileName,
dsaPathFileName); // move file, the source folder will be empty. // Copy the file name + yyyymm
to DSA Backup folder. if (!File.Exists(dsaPathFileName)) { //MessageBox.Show("DSA file
was not found"); Dts.TaskResult = (int)ScriptResults.Failure; return; } dsaBackupFileName =
dsaBackupFileName.Replace("yyyymm", yyyymm); dsaBackupPathFileName =
dsaBackupFolderPath + "\\" + dsaBackupFileName; //MessageBox.Show(dsaBackupPathFileName); if
(File.Exists(dsaBackupPathFileName)) File.Delete(dsaBackupPathFileName); File.Copy(dsaPathFileName,
dsaBackupPathFileName); Dts.TaskResult = (int)ScriptResults.Success; return; } else { //MessageBox.Show("Something
had goes wrong 2"); Dts.TaskResult = (int)ScriptResults.Failure; return; } } catch (Exception) { //MessageBox.Show("Something had goes wrong
1"); Dts.TaskResult = (int)ScriptResults.Failure; return; } } else { //MessageBox.Show("One of the four folders was
not found"); Dts.TaskResult = (int)ScriptResults.Failure; return; } } private string ReadFileFirstLine(string dsaPathFileName) { FileStream fs = null; StreamReader sr = null; string line = null; long length = 0; if (File.Exists(dsaPathFileName)) { try { length = new
FileInfo(dsaPathFileName).Length; if (length != 0) { fs = File.OpenRead(dsaPathFileName); //,
FileMode.Open, FileAccess.Read, FileShare.None); sr = new StreamReader(fs); line = sr.ReadLine(); } } catch (Exception) { line = null; } finally { if (sr != null) sr.Close(); if (fs != null) fs.Close(); } } return line; } } } /* Another
example not in use here: Directory.GetFiles(sFilePath,
"*.xls") Dim di As DirectoryInfo =
My.Computer.FileSystem.GetDirectoryInfo(sFilePath) For Each fi As FileInfo In di.GetFiles("*.xls") lstFiles.Items.Add(fi.Name) Next fi Dts.Variables("FileCnt").Value = 0 */ A C# program can call a parameterized
stored procedure that has output values or gives a recordset to be handled or
calculated inside the program and save the data back to table in the
database. Example of a Script Task that check
a variable ValidationResult for true or false and do an action: ST_ValidationResult_is_true_Do_continue_else_halt_with_failure: public
void Main() { If (Dts.Variables["User::ValidationResult"].Value
!= null && (bool)(Dts.Variables["User::ValidationResult"].Value)
== true) { Dts.TaskResult =
(int)ScriptResults.Success; // for
continue. } else { Dts.Events.FireError(0,
"SSIS: Action_Audit_Validation_of_Staging", "Audit
validation of Staging tables has status Failed, therefore the ETL process has stopped.", String.Empty, 0); Dts.TaskResult =
(int)ScriptResults.Failure; // for
halt/stop. } } 19.
Upgrade to a Visual Studio 2022 solution Having a SQL Server 2016 database
and a Visual Studio 2017 32-bit solution using .NET 4.5 Framework with three
projects for: ·
database
project _DB with .sql files per object in the database ·
integration
services project _IS with .dtsx files for SSIS packages ·
analysis
services tabular dax project _AS with a Model.bim file Example
of the _DB properties:
Example
of the _IS properties:
Want to
upgrade to a SQL Server 2022 database and to a Visual Studio 2022 solution
then be aware of: ·
The
Connection Managers OLEDB provider SQL Server Native
Client has been removed from SQL Server 2022 (160) (SQLNCLI or SQLNCLI11 or SQLOLEDB),
therefore must use
Microsoft OLE DB Driver for SQL Server (MSOLEDBSQL). ·
Visual Studio 2022 installation you must include
the .NET Framework 4.8.x. ·
Visual Studio 2022 menu you click Extension
to download for SSIS and SSAS. ·
Visual Studio 2022 menu you click Tools
and Options to set SSAS 2022. ·
Visual Studio 2017 was 32-bit and had
this path: C:\Program Files (x86)\Microsoft Visual Studio\2017\SQL\Common7\IDE\ Visual
Studio 2022 is 64-bit only and the free Community has this path: C:\Program Files\Microsoft Visual
Studio\2022\Community\Common7\IDE\
Before open
your solution in Visual Studio 2022 to connect to SQL Server 2022, please fix
few things in Notepad: ·
In database project file _DB.sqlproj you replace
path for old Visual Studio 32-bit and old SQL version 2016 indicated
by Compatibility level number 130: <ArtifactReference
Include="C:\Program Files (x86)\ Microsoft
Visual Studio\2017\SQL\Common7\IDE\ Extensions\Microsoft\SQLDB\Extensions\SqlServer\ 130\SqlSchemas\msdb.dacpac"> <HintPath>$(DacPacRootPath)\Extensions\ Microsoft\SQLDB\Extensions\SqlServer\ 130\SqlSchemas\msdb.dacpac</HintPath> <ArtifactReference
Include="C:\Program Files (x86)\ Microsoft
Visual Studio\2017\SQL\Common7\IDE\ Extensions\Microsoft\SQLDB\Extensions\SqlServer\ 130\SqlSchemas\master.dacpac"> <HintPath>$(DacPacRootPath)\Extensions\ Microsoft\SQLDB\Extensions\SqlServer\ 130\SqlSchemas\master.dacpac</HintPath> to
a new path for Visual Studio 2022 64-bit and for SQL version 2022 indicated
by Compatibility level number 160. The new path and folder and files must
exists at the computer: <ArtifactReference
Include="C:\Program Files\ Microsoft
Visual Studio\2022\Community\Common7\IDE\ Extensions\Microsoft\SQLDB\Extensions\SqlServer\ 160\SqlSchemas\msdb.dacpac"> <HintPath>$(DacPacRootPath)\Extensions\ Microsoft\SQLDB\Extensions\SqlServer\ 160\SqlSchemas\msdb.dacpac</HintPath> <ArtifactReference
Include="C:\Program Files\ Microsoft
Visual Studio\2022\Community\Common7\IDE\ Extensions\Microsoft\SQLDB\Extensions\SqlServer\ 160\SqlSchemas\master.dacpac"> <HintPath>$(DacPacRootPath)\Extensions\ Microsoft\SQLDB\Extensions\SqlServer\ 160\SqlSchemas\master.dacpac</HintPath> ·
In integration services project file _IS.dtproj
you replace old
provides SQLOLEDB and SQLNCLI11 to new provider MSOLEDBSQL, and at tag TargetServerVersion
you replace value to SQL version 2022 like this: <TargetServerVersion>SQLServer2022</TargetServerVersion>. Now open your solution in Visual
Studio 2022 and you accept .NET Framework 4.8:
Go
to tab Solution Explorer and see your projects. At database project rightclick and click
Properties to change to SQL Server 2022 (Compatibility level number 160):
(Same
as if you with Notepad in file _DB.sqlproj had changed to: <DSP>Microsoft.Data.Tools.Schema.Sql. Sql160DatabaseSchemaProvider</DSP>). And
to change to .NET Framework 4.8.1:
At
analysis project Model.bim in Data source change provider to from SQL
Server Native Client (SQLNCLI) to Microsoft OLE DB Driver for SQL Server (MSOLEDBSQL):
To
change Model.bim Compatibility level rightclick at Model.bim and click Open, click
at tab Solution Explorer and rightclick again at Model.bim and click Properties
and in dropdown Compatibility level click SQL Server 2022 and in dialogbox
confirm by click Yes that the change is irreversible meaning can not be
changed therefore the dropdown in Compatibility level is gone afterwards:
For each Connection Managers OLEDB
connection open it to change provider from SQL
Server Native Client to Microsoft OLE DB Driver for SQL Server:
At
integration services project rightclick and click Properties to see
SQLServer2022:
Now you can build your Visual Studio
2022 solution without errors and warnings, and remember to click SaveAll icon
to save the content of your project files. In case you had started by open your
solution in Visual Studio 2022 and at dropdown for TargetServerVersion had
changed to SQL Server 2022, then Visual Studio would
had done a loop through all your SSIS packages. Afterwards you would had got
problems like: ·
Error
message: conmgr Unable to create the type with the name 'OLEDB'. ·
Error
message: sys is unreachable at master or at msdb. ·
Open
a Connection Managers OLEDB connection to get error message:
Microsoft
Visual Studio is unable to load this document. Unable to create the type with
the name 'OLEDB'. ·
New
Connection and Visual Studio 2022 will crash! ·
Open a SSIS package that is using a OLEDB
connection to a source or destination to see a corrupt icon at all tasks:
SSIS.ReplacementTask is not
registered because the loop had corrupted the package due to an
anomaly in the normal upgrade process to a higher version of VS. 20.
Build server – Agent pool in Azure DevOps Git is a source code version control
system to keep track of all previous versions, but Git does not include build
files like database dacpac and ssis ispac, therefore we need a build server
to build the source code to these files before a deploy. The build server is
often your development server where all the programs and tools are already
installed. Azure DevOps calls it a Agent Pool and when it is placed on a on
prem server it is called a self-hosted agent, read more.
In case you are using classic Azure
DevOps build pipeline and release pipelines to call a Power Shell Script you
had made, remember to extend Power Shell with SQL Server from PowerShell Gallery
SQLServerTools and ReportingServicesTools. Other tip here. When build server is in the cloud you need a personal
access tokens tip here. 21.
About me I have worked with SQL Server since
1997 called 6.5 and the first production was running in 7.0 in 1998. I have used Data
Transformation Services (DTS) in SQL Server 2000, Business Intelligence
Development Studio (BIDS) in SQL Server 2005–2008 R2, SQL Server Data Tools
(SSDT) in SQL Server 2012 and SQL Server Data Tools for Business
Intelligence (SSDT BI) in SQL Server 2014, 2016, 2017, 2019, 2022. Exporting SSIS packages from
Integration Services Catalog SSISDB: 1. Start SQL Server
Management Studio. 2. Locate the deployed
project is the SSIS Catalog. 3. Right click the project
and select Export and save the file as ispac. 4. Rename the file extension
from .ispac to .zip. 5. Extract the .zip file to
a folder. 6. In Visual Studio click New,
Project, Integration Services Import Project Wizard where Project deployment
ask for a ispac file, and Integration Services catalog ask for SSISDB path or
create a new SSIS project and add packages from the folder. Please visit my homepage for the
english part: Sometimes I see a SQL statement in a
SSIS package that is hard to read, because it does not have a
nice format layout, therefore I copy-paste the statement to a site that make
it more readable: sql-format
or sqlformat
with different dialects. |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||